 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective QA-driven Annotation of Predicate-Argument Relations Across Languages
Feb 26, 2026Explicit representations of predicate-argument relations form the basis of interpretable semantic analysis, supporting reasoning, generation, and evaluation. However, attaining such semantic structures requires costly annotation efforts and has remained largely confined to English. We leverage the Question-Answer driven Semantic Role Labeling (QA-SRL) framework -- a natural-language formulation of predicate-argument relations -- as the foundation for extending semantic annotation to new languages. To this end, we introduce a cross-linguistic projection approach that reuses an English QA-SRL parser within a constrained translation and word-alignment pipeline to automatically generate question-answer annotations aligned with target-language predicates. Applied to Hebrew, Russian, and French -- spanning diverse language families -- the method yields high-quality training data and fine-tuned, language-specific parsers that outperform strong multilingual LLM baselines (GPT-4o, LLaMA-Maverick). By leveraging QA-SRL as a transferable natural-language interface for semantics, our approach enables efficient and broadly accessible predicate-argument parsing across languages.
IQ Test for LLMs: An Evaluation Framework for Uncovering Core Skills in LLMs
Jul 27, 2025Current evaluations of large language models (LLMs) rely on benchmark scores, but it is difficult to interpret what these individual scores reveal about a model's overall skills. Specifically, as a community we lack understanding of how tasks relate to one another, what they measure in common, how they differ, or which ones are redundant. As a result, models are often assessed via a single score averaged across benchmarks, an approach that fails to capture the models' wholistic strengths and limitations. Here, we propose a new evaluation paradigm that uses factor analysis to identify latent skills driving performance across benchmarks. We apply this method to a comprehensive new leaderboard showcasing the performance of 60 LLMs on 44 tasks, and identify a small set of latent skills that largely explain performance. Finally, we turn these insights into practical tools that identify redundant tasks, aid in model selection, and profile models along each latent skill.
ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025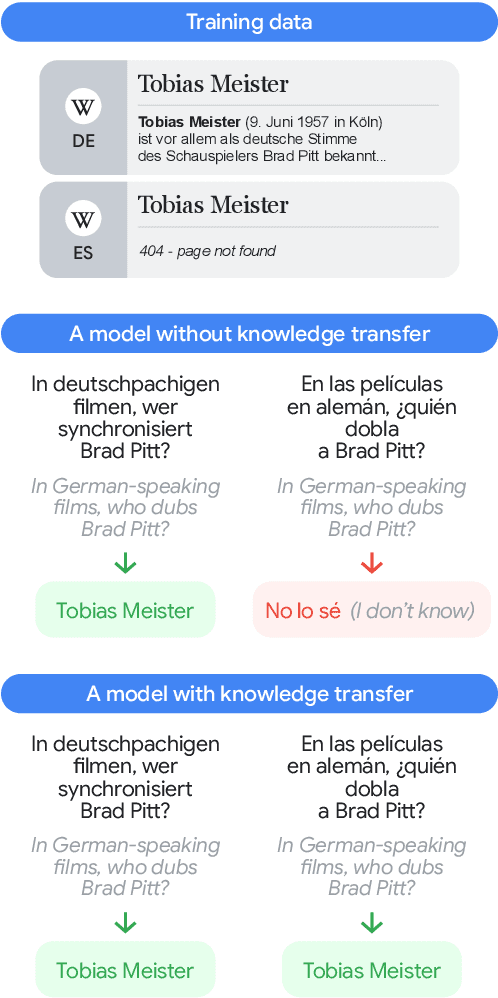
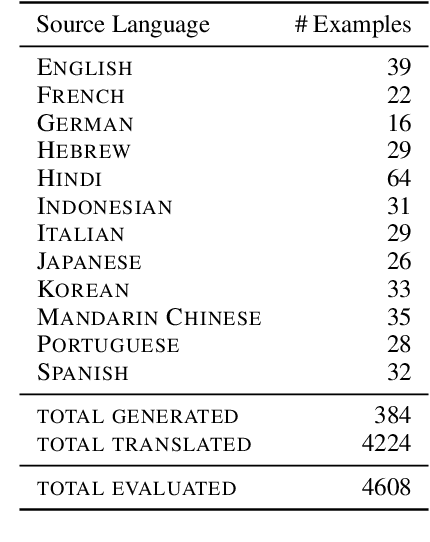
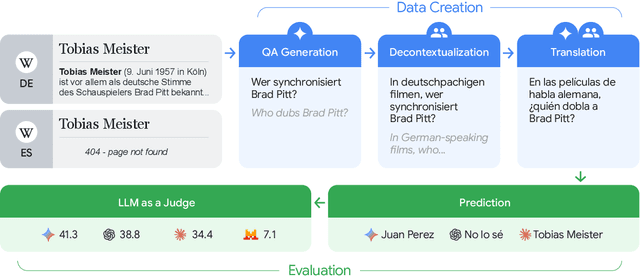
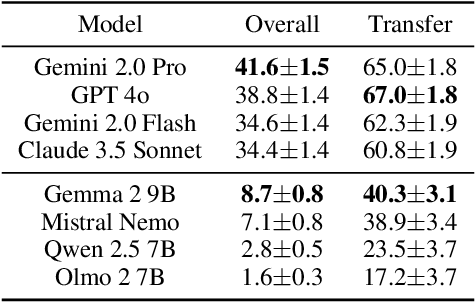
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
Beyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs
Feb 13, 2025Despite advances in the multilingual capabilities of Large Language Models (LLMs) across diverse tasks, English remains the dominant language for LLM research and development. So, when working with a different language, this has led to the widespread practice of pre-translation, i.e., translating the task prompt into English before inference. Selective pre-translation, a more surgical approach, focuses on translating specific prompt components. However, its current use is sporagic and lacks a systematic research foundation. Consequently, the optimal pre-translation strategy for various multilingual settings and tasks remains unclear. In this work, we aim to uncover the optimal setup for pre-translation by systematically assessing its use. Specifically, we view the prompt as a modular entity, composed of four functional parts: instruction, context, examples, and output, either of which could be translated or not. We evaluate pre-translation strategies across 35 languages covering both low and high-resource languages, on various tasks including Question Answering (QA), Natural Language Inference (NLI), Named Entity Recognition (NER), and Abstractive Summarization. Our experiments show the impact of factors as similarity to English, translation quality and the size of pre-trained data, on the model performance with pre-translation. We suggest practical guidelines for choosing optimal strategies in various multilingual settings.
NoviCode: Generating Programs from Natural Language Utterances by Novices
Jul 16, 2024Current Text-to-Code models demonstrate impressive capabilities in generating executable code from natural language snippets. However, current studies focus on technical instructions and programmer-oriented language, and it is an open question whether these models can effectively translate natural language descriptions given by non-technical users and express complex goals, to an executable program that contains an intricate flow - composed of API access and control structures as loops, conditions, and sequences. To unlock the challenge of generating a complete program from a plain non-technical description we present NoviCode, a novel NL Programming task, which takes as input an API and a natural language description by a novice non-programmer and provides an executable program as output. To assess the efficacy of models on this task, we provide a novel benchmark accompanied by test suites wherein the generated program code is assessed not according to their form, but according to their functional execution. Our experiments show that, first, NoviCode is indeed a challenging task in the code synthesis domain, and that generating complex code from non-technical instructions goes beyond the current Text-to-Code paradigm. Second, we show that a novel approach wherein we align the NL utterances with the compositional hierarchical structure of the code, greatly enhances the performance of LLMs on this task, compared with the end-to-end Text-to-Code counterparts.
Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Jun 29, 2024Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of "long-context", defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.
Into the Unknown: Generating Geospatial Descriptions for New Environments
Jun 28, 2024Similar to vision-and-language navigation (VLN) tasks that focus on bridging the gap between vision and language for embodied navigation, the new Rendezvous (RVS) task requires reasoning over allocentric spatial relationships (independent of the observer's viewpoint) using non-sequential navigation instructions and maps. However, performance substantially drops in new environments with no training data. Using opensource descriptions paired with coordinates (e.g., Wikipedia) provides training data but suffers from limited spatially-oriented text resulting in low geolocation resolution. We propose a large-scale augmentation method for generating high-quality synthetic data for new environments using readily available geospatial data. Our method constructs a grounded knowledge-graph, capturing entity relationships. Sampled entities and relations (`shop north of school') generate navigation instructions via (i) generating numerous templates using context-free grammar (CFG) to embed specific entities and relations; (ii) feeding the entities and relation into a large language model (LLM) for instruction generation. A comprehensive evaluation on RVS, showed that our approach improves the 100-meter accuracy by 45.83% on unseen environments. Furthermore, we demonstrate that models trained with CFG-based augmentation achieve superior performance compared with those trained with LLM-based augmentation, both in unseen and seen environments. These findings suggest that the potential advantages of explicitly structuring spatial information for text-based geospatial reasoning in previously unknown, can unlock data-scarce scenarios.
HeSum: a Novel Dataset for Abstractive Text Summarization in Hebrew
Jun 06, 2024While large language models (LLMs) excel in various natural language tasks in English, their performance in lower-resourced languages like Hebrew, especially for generative tasks such as abstractive summarization, remains unclear. The high morphological richness in Hebrew adds further challenges due to the ambiguity in sentence comprehension and the complexities in meaning construction. In this paper, we address this resource and evaluation gap by introducing HeSum, a novel benchmark specifically designed for abstractive text summarization in Modern Hebrew. HeSum consists of 10,000 article-summary pairs sourced from Hebrew news websites written by professionals. Linguistic analysis confirms HeSum's high abstractness and unique morphological challenges. We show that HeSum presents distinct difficulties for contemporary state-of-the-art LLMs, establishing it as a valuable testbed for generative language technology in Hebrew, and MRLs generative challenges in general.
Superlatives in Context: Explicit and Implicit Domain Restrictions for Superlative Frames
May 31, 2024Superlatives are used to single out elements with a maximal/minimal property. Semantically, superlatives perform a set comparison: something (or some things) has the min/max property out of a set. As such, superlatives provide an ideal phenomenon for studying implicit phenomena and discourse restrictions. While this comparison set is often not explicitly defined, its (implicit) restrictions can be inferred from the discourse context the expression appears in. In this work we provide an extensive computational study on the semantics of superlatives. We propose a unified account of superlative semantics which allows us to derive a broad-coverage annotation schema. Using this unified schema we annotated a multi-domain dataset of superlatives and their semantic interpretations. We specifically focus on interpreting implicit or ambiguous superlative expressions, by analyzing how the discourse context restricts the set of interpretations. In a set of experiments we then analyze how well models perform at variations of predicting superlative semantics, with and without context. We show that the fine-grained semantics of superlatives in context can be challenging for contemporary models, including GPT-4.
Do Pretrained Contextual Language Models Distinguish between Hebrew Homograph Analyses?
May 11, 2024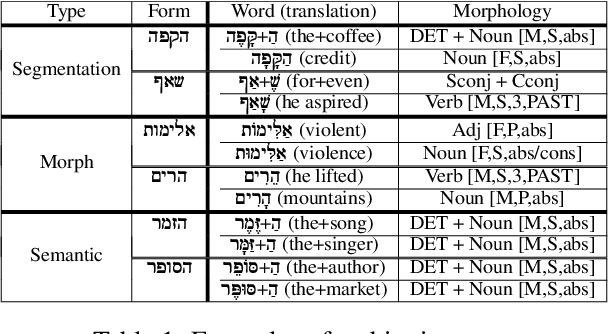
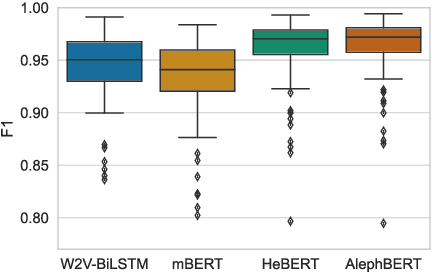
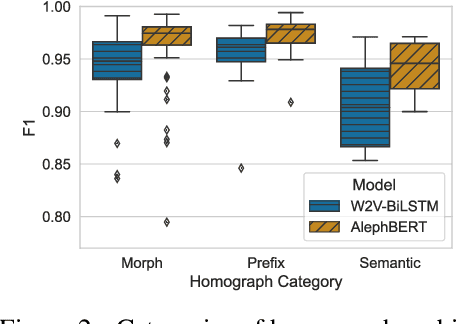
Semitic morphologically-rich languages (MRLs) are characterized by extreme word ambiguity. Because most vowels are omitted in standard texts, many of the words are homographs with multiple possible analyses, each with a different pronunciation and different morphosyntactic properties. This ambiguity goes beyond word-sense disambiguation (WSD), and may include token segmentation into multiple word units. Previous research on MRLs claimed that standardly trained pre-trained language models (PLMs) based on word-pieces may not sufficiently capture the internal structure of such tokens in order to distinguish between these analyses. Taking Hebrew as a case study, we investigate the extent to which Hebrew homographs can be disambiguated and analyzed using PLMs. We evaluate all existing models for contextualized Hebrew embeddings on a novel Hebrew homograph challenge sets that we deliver. Our empirical results demonstrate that contemporary Hebrew contextualized embeddings outperform non-contextualized embeddings; and that they are most effective for disambiguating segmentation and morphosyntactic features, less so regarding pure word-sense disambiguation. We show that these embeddings are more effective when the number of word-piece splits is limited, and they are more effective for 2-way and 3-way ambiguities than for 4-way ambiguity. We show that the embeddings are equally effective for homographs of both balanced and skewed distributions, whether calculated as masked or unmasked tokens. Finally, we show that these embeddings are as effective for homograph disambiguation with extensive supervised training as with a few-shot setup.