 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs
Feb 13, 2025Despite advances in the multilingual capabilities of Large Language Models (LLMs) across diverse tasks, English remains the dominant language for LLM research and development. So, when working with a different language, this has led to the widespread practice of pre-translation, i.e., translating the task prompt into English before inference. Selective pre-translation, a more surgical approach, focuses on translating specific prompt components. However, its current use is sporagic and lacks a systematic research foundation. Consequently, the optimal pre-translation strategy for various multilingual settings and tasks remains unclear. In this work, we aim to uncover the optimal setup for pre-translation by systematically assessing its use. Specifically, we view the prompt as a modular entity, composed of four functional parts: instruction, context, examples, and output, either of which could be translated or not. We evaluate pre-translation strategies across 35 languages covering both low and high-resource languages, on various tasks including Question Answering (QA), Natural Language Inference (NLI), Named Entity Recognition (NER), and Abstractive Summarization. Our experiments show the impact of factors as similarity to English, translation quality and the size of pre-trained data, on the model performance with pre-translation. We suggest practical guidelines for choosing optimal strategies in various multilingual settings.
Into the Unknown: Generating Geospatial Descriptions for New Environments
Jun 28, 2024Similar to vision-and-language navigation (VLN) tasks that focus on bridging the gap between vision and language for embodied navigation, the new Rendezvous (RVS) task requires reasoning over allocentric spatial relationships (independent of the observer's viewpoint) using non-sequential navigation instructions and maps. However, performance substantially drops in new environments with no training data. Using opensource descriptions paired with coordinates (e.g., Wikipedia) provides training data but suffers from limited spatially-oriented text resulting in low geolocation resolution. We propose a large-scale augmentation method for generating high-quality synthetic data for new environments using readily available geospatial data. Our method constructs a grounded knowledge-graph, capturing entity relationships. Sampled entities and relations (`shop north of school') generate navigation instructions via (i) generating numerous templates using context-free grammar (CFG) to embed specific entities and relations; (ii) feeding the entities and relation into a large language model (LLM) for instruction generation. A comprehensive evaluation on RVS, showed that our approach improves the 100-meter accuracy by 45.83% on unseen environments. Furthermore, we demonstrate that models trained with CFG-based augmentation achieve superior performance compared with those trained with LLM-based augmentation, both in unseen and seen environments. These findings suggest that the potential advantages of explicitly structuring spatial information for text-based geospatial reasoning in previously unknown, can unlock data-scarce scenarios.
HeSum: a Novel Dataset for Abstractive Text Summarization in Hebrew
Jun 06, 2024While large language models (LLMs) excel in various natural language tasks in English, their performance in lower-resourced languages like Hebrew, especially for generative tasks such as abstractive summarization, remains unclear. The high morphological richness in Hebrew adds further challenges due to the ambiguity in sentence comprehension and the complexities in meaning construction. In this paper, we address this resource and evaluation gap by introducing HeSum, a novel benchmark specifically designed for abstractive text summarization in Modern Hebrew. HeSum consists of 10,000 article-summary pairs sourced from Hebrew news websites written by professionals. Linguistic analysis confirms HeSum's high abstractness and unique morphological challenges. We show that HeSum presents distinct difficulties for contemporary state-of-the-art LLMs, establishing it as a valuable testbed for generative language technology in Hebrew, and MRLs generative challenges in general.
Where Do We Go from Here? Multi-scale Allocentric Relational Inference from Natural Spatial Descriptions
Feb 26, 2024When communicating routes in natural language, the concept of {\em acquired spatial knowledge} is crucial for geographic information retrieval (GIR) and in spatial cognitive research. However, NLP navigation studies often overlook the impact of such acquired knowledge on textual descriptions. Current navigation studies concentrate on egocentric local descriptions (e.g., `it will be on your right') that require reasoning over the agent's local perception. These instructions are typically given as a sequence of steps, with each action-step explicitly mentioning and being followed by a landmark that the agent can use to verify they are on the right path (e.g., `turn right and then you will see...'). In contrast, descriptions based on knowledge acquired through a map provide a complete view of the environment and capture its overall structure. These instructions (e.g., `it is south of Central Park and a block north of a police station') are typically non-sequential, contain allocentric relations, with multiple spatial relations and implicit actions, without any explicit verification. This paper introduces the Rendezvous (RVS) task and dataset, which includes 10,404 examples of English geospatial instructions for reaching a target location using map-knowledge. Our analysis reveals that RVS exhibits a richer use of spatial allocentric relations, and requires resolving more spatial relations simultaneously compared to previous text-based navigation benchmarks.
Apollo: Zero-shot MultiModal Reasoning with Multiple Experts
Oct 25, 2023We propose a modular framework that leverages the expertise of different foundation models over different modalities and domains in order to perform a single, complex, multi-modal task, without relying on prompt engineering or otherwise tailor-made multi-modal training. Our approach enables decentralized command execution and allows each model to both contribute and benefit from the expertise of the other models. Our method can be extended to a variety of foundation models (including audio and vision), above and beyond only language models, as it does not depend on prompts. We demonstrate our approach on two tasks. On the well-known task of stylized image captioning, our experiments show that our approach outperforms semi-supervised state-of-the-art models, while being zero-shot and avoiding costly training, data collection, and prompt engineering. We further demonstrate this method on a novel task, audio-aware image captioning, in which an image and audio are given and the task is to generate text that describes the image within the context of the provided audio. Our code is available on GitHub.
HeGeL: A Novel Dataset for Geo-Location from Hebrew Text
Jul 02, 2023


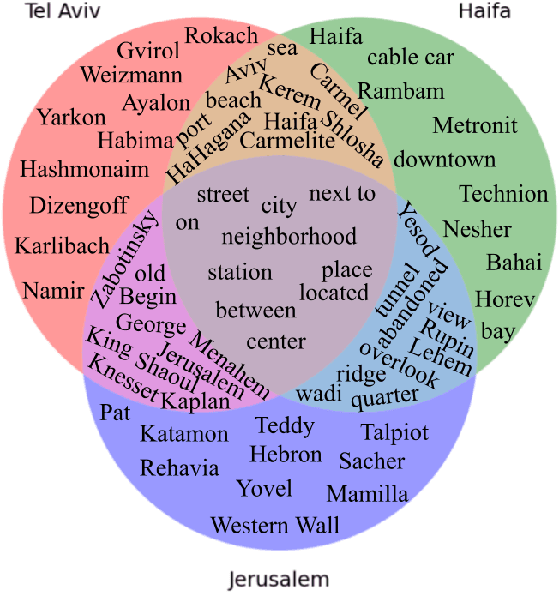
The task of textual geolocation - retrieving the coordinates of a place based on a free-form language description - calls for not only grounding but also natural language understanding and geospatial reasoning. Even though there are quite a few datasets in English used for geolocation, they are currently based on open-source data (Wikipedia and Twitter), where the location of the described place is mostly implicit, such that the location retrieval resolution is limited. Furthermore, there are no datasets available for addressing the problem of textual geolocation in morphologically rich and resource-poor languages, such as Hebrew. In this paper, we present the Hebrew Geo-Location (HeGeL) corpus, designed to collect literal place descriptions and analyze lingual geospatial reasoning. We crowdsourced 5,649 literal Hebrew place descriptions of various place types in three cities in Israel. Qualitative and empirical analysis show that the data exhibits abundant use of geospatial reasoning and requires a novel environmental representation.
ZEST: Zero-shot Learning from Text Descriptions using Textual Similarity and Visual Summarization
Oct 07, 2020



We study the problem of recognizing visual entities from the textual descriptions of their classes. Specifically, given birds' images with free-text descriptions of their species, we learn to classify images of previously-unseen species based on specie descriptions. This setup has been studied in the vision community under the name zero-shot learning from text, focusing on learning to transfer knowledge about visual aspects of birds from seen classes to previously-unseen ones. Here, we suggest focusing on the textual description and distilling from the description the most relevant information to effectively match visual features to the parts of the text that discuss them. Specifically, (1) we propose to leverage the similarity between species, reflected in the similarity between text descriptions of the species. (2) we derive visual summaries of the texts, i.e., extractive summaries that focus on the visual features that tend to be reflected in images. We propose a simple attention-based model augmented with the similarity and visual summaries components. Our empirical results consistently and significantly outperform the state-of-the-art on the largest benchmarks for text-based zero-shot learning, illustrating the critical importance of texts for zero-shot image-recognition.
RUN through the Streets: A New Dataset and Baseline Models for Realistic Urban Navigation
Sep 19, 2019
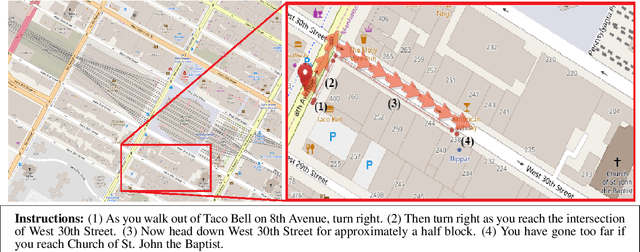


Following navigation instructions in natural language requires a composition of language, action, and knowledge of the environment. Knowledge of the environment may be provided via visual sensors or as a symbolic world representation referred to as a map. Here we introduce the Realistic Urban Navigation (RUN) task, aimed at interpreting navigation instructions based on a real, dense, urban map. Using Amazon Mechanical Turk, we collected a dataset of 2515 instructions aligned with actual routes over three regions of Manhattan. We propose a strong baseline for the task and empirically investigate which aspects of the neural architecture are important for the RUN success. Our results empirically show that entity abstraction, attention over words and worlds, and a constantly updating world-state, significantly contribute to task accuracy.