 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInto the Unknown: Generating Geospatial Descriptions for New Environments
Jun 28, 2024Similar to vision-and-language navigation (VLN) tasks that focus on bridging the gap between vision and language for embodied navigation, the new Rendezvous (RVS) task requires reasoning over allocentric spatial relationships (independent of the observer's viewpoint) using non-sequential navigation instructions and maps. However, performance substantially drops in new environments with no training data. Using opensource descriptions paired with coordinates (e.g., Wikipedia) provides training data but suffers from limited spatially-oriented text resulting in low geolocation resolution. We propose a large-scale augmentation method for generating high-quality synthetic data for new environments using readily available geospatial data. Our method constructs a grounded knowledge-graph, capturing entity relationships. Sampled entities and relations (`shop north of school') generate navigation instructions via (i) generating numerous templates using context-free grammar (CFG) to embed specific entities and relations; (ii) feeding the entities and relation into a large language model (LLM) for instruction generation. A comprehensive evaluation on RVS, showed that our approach improves the 100-meter accuracy by 45.83% on unseen environments. Furthermore, we demonstrate that models trained with CFG-based augmentation achieve superior performance compared with those trained with LLM-based augmentation, both in unseen and seen environments. These findings suggest that the potential advantages of explicitly structuring spatial information for text-based geospatial reasoning in previously unknown, can unlock data-scarce scenarios.
Where Do We Go from Here? Multi-scale Allocentric Relational Inference from Natural Spatial Descriptions
Feb 26, 2024When communicating routes in natural language, the concept of {\em acquired spatial knowledge} is crucial for geographic information retrieval (GIR) and in spatial cognitive research. However, NLP navigation studies often overlook the impact of such acquired knowledge on textual descriptions. Current navigation studies concentrate on egocentric local descriptions (e.g., `it will be on your right') that require reasoning over the agent's local perception. These instructions are typically given as a sequence of steps, with each action-step explicitly mentioning and being followed by a landmark that the agent can use to verify they are on the right path (e.g., `turn right and then you will see...'). In contrast, descriptions based on knowledge acquired through a map provide a complete view of the environment and capture its overall structure. These instructions (e.g., `it is south of Central Park and a block north of a police station') are typically non-sequential, contain allocentric relations, with multiple spatial relations and implicit actions, without any explicit verification. This paper introduces the Rendezvous (RVS) task and dataset, which includes 10,404 examples of English geospatial instructions for reaching a target location using map-knowledge. Our analysis reveals that RVS exhibits a richer use of spatial allocentric relations, and requires resolving more spatial relations simultaneously compared to previous text-based navigation benchmarks.
AQuaMuSe: Automatically Generating Datasets for Query-Based Multi-Document Summarization
Oct 23, 2020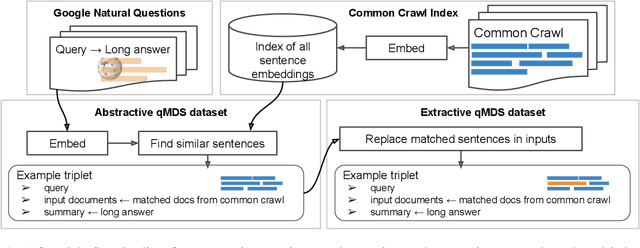

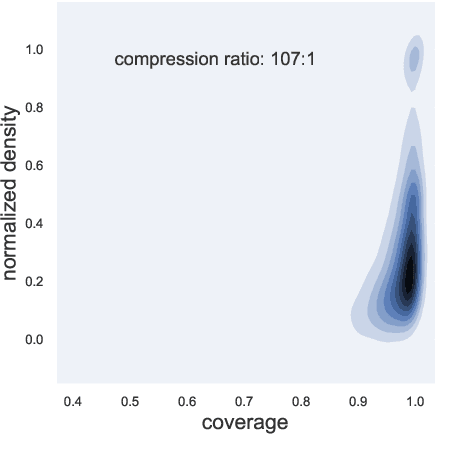
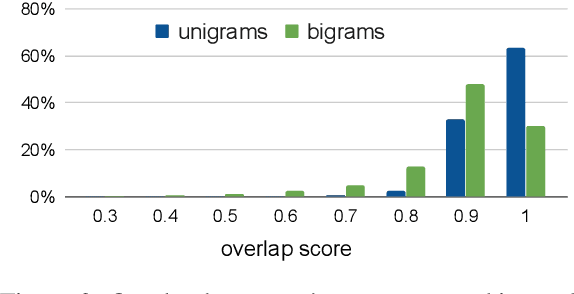
Summarization is the task of compressing source document(s) into coherent and succinct passages. This is a valuable tool to present users with concise and accurate sketch of the top ranked documents related to their queries. Query-based multi-document summarization (qMDS) addresses this pervasive need, but the research is severely limited due to lack of training and evaluation datasets as existing single-document and multi-document summarization datasets are inadequate in form and scale. We propose a scalable approach called AQuaMuSe to automatically mine qMDS examples from question answering datasets and large document corpora. Our approach is unique in the sense that it can general a dual dataset -- for extractive and abstractive summaries both. We publicly release a specific instance of an AQuaMuSe dataset with 5,519 query-based summaries, each associated with an average of 6 input documents selected from an index of 355M documents from Common Crawl. Extensive evaluation of the dataset along with baseline summarization model experiments are provided.
Unifying data for fine-grained visual species classification
Sep 24, 2020
Wildlife monitoring is crucial to nature conservation and has been done by manual observations from motion-triggered camera traps deployed in the field. Widespread adoption of such in-situ sensors has resulted in unprecedented data volumes being collected over the last decade. A significant challenge exists to process and reliably identify what is in these images efficiently. Advances in computer vision are poised to provide effective solutions with custom AI models built to automatically identify images of interest and label the species in them. Here we outline the data unification effort for the Wildlife Insights platform from various conservation partners, and the challenges involved. Then we present an initial deep convolutional neural network model, trained on 2.9M images across 465 fine-grained species, with a goal to reduce the load on human experts to classify species in images manually. The long-term goal is to enable scientists to make conservation recommendations from near real-time analysis of species abundance and population health.
Spatial Language Representation with Multi-Level Geocoding
Aug 21, 2020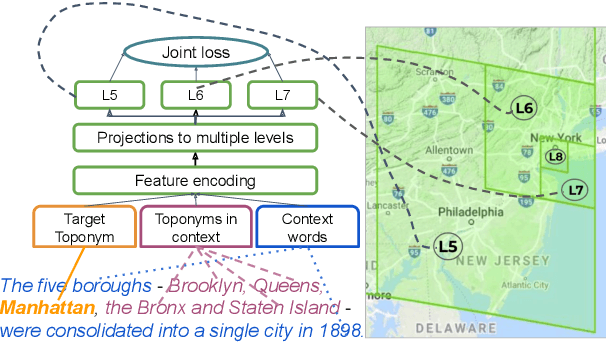

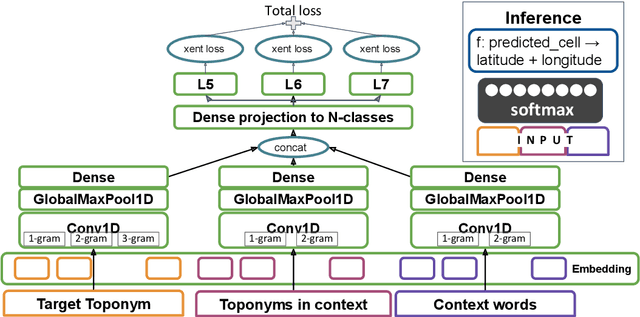

We present a multi-level geocoding model (MLG) that learns to associate texts to geographic locations. The Earth's surface is represented using space-filling curves that decompose the sphere into a hierarchy of similarly sized, non-overlapping cells. MLG balances generalization and accuracy by combining losses across multiple levels and predicting cells at each level simultaneously. Without using any dataset-specific tuning, we show that MLG obtains state-of-the-art results for toponym resolution on three English datasets. Furthermore, it obtains large gains without any knowledge base metadata, demonstrating that it can effectively learn the connection between text spans and coordinates - and thus can be extended to toponymns not present in knowledge bases.
Learning Dense Representations for Entity Retrieval
Sep 23, 2019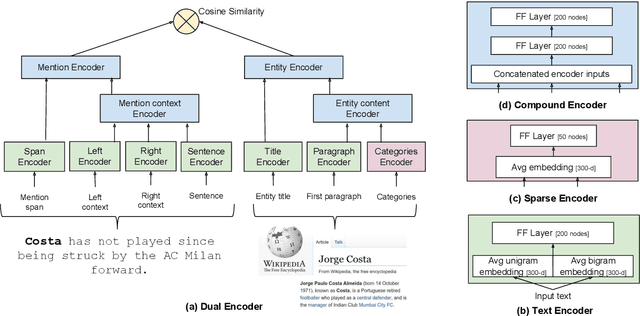
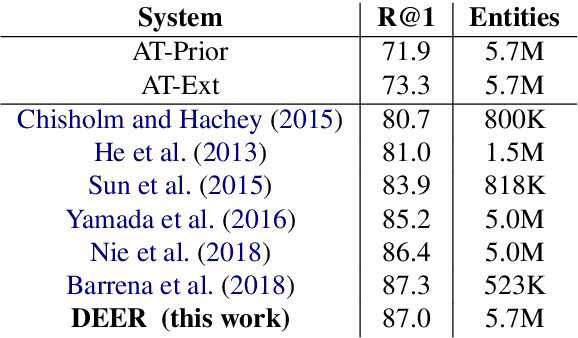
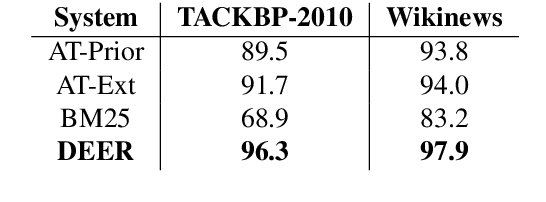
We show that it is feasible to perform entity linking by training a dual encoder (two-tower) model that encodes mentions and entities in the same dense vector space, where candidate entities are retrieved by approximate nearest neighbor search. Unlike prior work, this setup does not rely on an alias table followed by a re-ranker, and is thus the first fully learned entity retrieval model. We show that our dual encoder, trained using only anchor-text links in Wikipedia, outperforms discrete alias table and BM25 baselines, and is competitive with the best comparable results on the standard TACKBP-2010 dataset. In addition, it can retrieve candidates extremely fast, and generalizes well to a new dataset derived from Wikinews. On the modeling side, we demonstrate the dramatic value of an unsupervised negative mining algorithm for this task.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018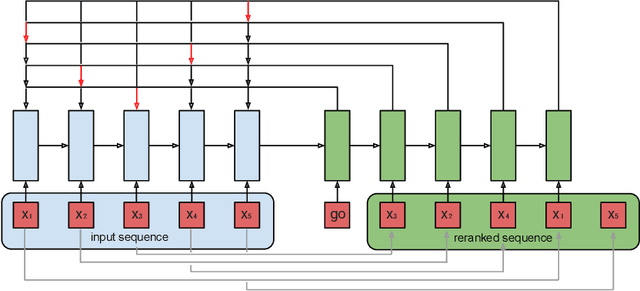
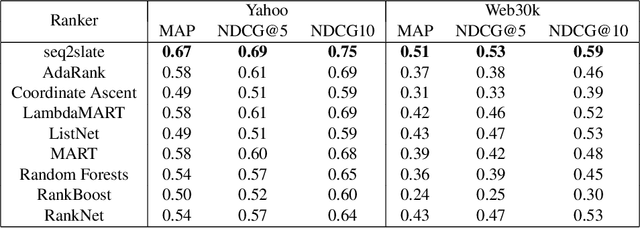

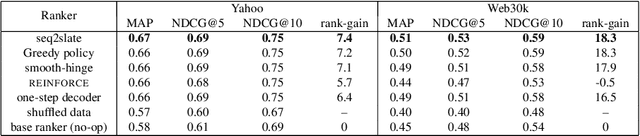
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.