 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational-WENO: A lightweight, physically-consistent three-point weighted essentially non-oscillatory scheme
Sep 13, 2024



Conventional WENO3 methods are known to be highly dissipative at lower resolutions, introducing significant errors in the pre-asymptotic regime. In this paper, we employ a rational neural network to accurately estimate the local smoothness of the solution, dynamically adapting the stencil weights based on local solution features. As rational neural networks can represent fast transitions between smooth and sharp regimes, this approach achieves a granular reconstruction with significantly reduced dissipation, improving the accuracy of the simulation. The network is trained offline on a carefully chosen dataset of analytical functions, bypassing the need for differentiable solvers. We also propose a robust model selection criterion based on estimates of the interpolation's convergence order on a set of test functions, which correlates better with the model performance in downstream tasks. We demonstrate the effectiveness of our approach on several one-, two-, and three-dimensional fluid flow problems: our scheme generalizes across grid resolutions while handling smooth and discontinuous solutions. In most cases, our rational network-based scheme achieves higher accuracy than conventional WENO3 with the same stencil size, and in a few of them, it achieves accuracy comparable to WENO5, which uses a larger stencil.
A Hierarchical Multi-Modal Encoder for Moment Localization in Video Corpus
Nov 24, 2020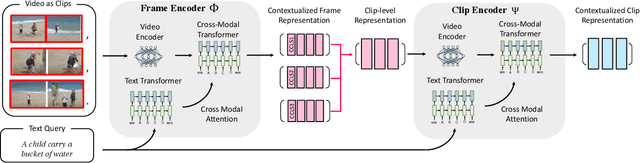
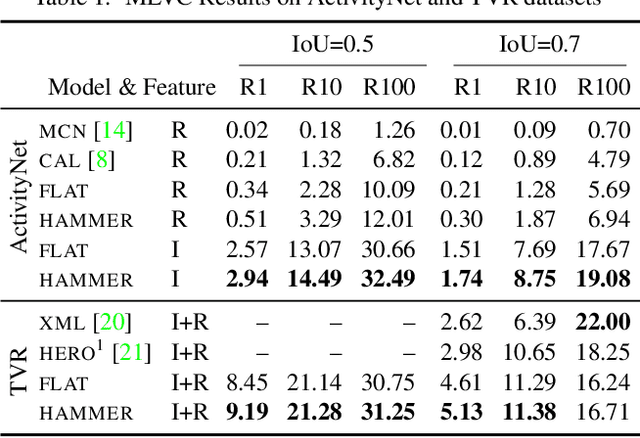
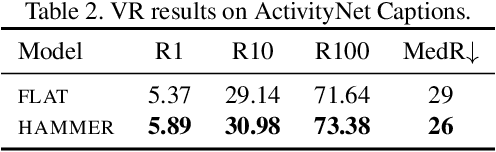
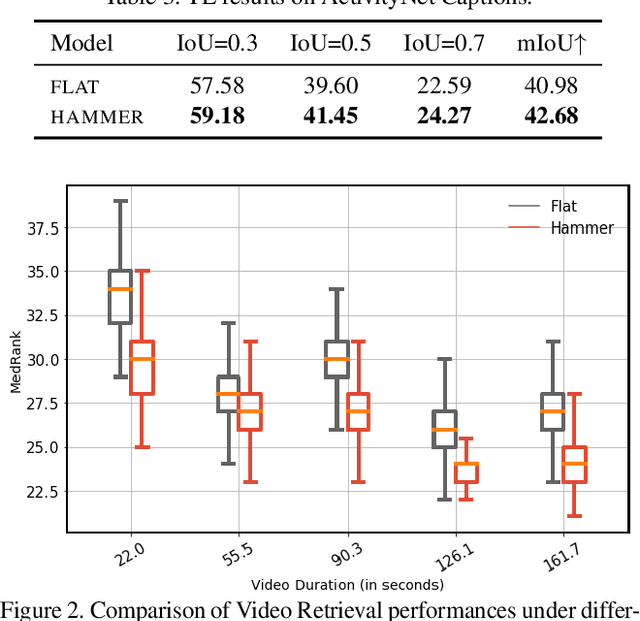
Identifying a short segment in a long video that semantically matches a text query is a challenging task that has important application potentials in language-based video search, browsing, and navigation. Typical retrieval systems respond to a query with either a whole video or a pre-defined video segment, but it is challenging to localize undefined segments in untrimmed and unsegmented videos where exhaustively searching over all possible segments is intractable. The outstanding challenge is that the representation of a video must account for different levels of granularity in the temporal domain. To tackle this problem, we propose the HierArchical Multi-Modal EncodeR (HAMMER) that encodes a video at both the coarse-grained clip level and the fine-grained frame level to extract information at different scales based on multiple subtasks, namely, video retrieval, segment temporal localization, and masked language modeling. We conduct extensive experiments to evaluate our model on moment localization in video corpus on ActivityNet Captions and TVR datasets. Our approach outperforms the previous methods as well as strong baselines, establishing new state-of-the-art for this task.
AQuaMuSe: Automatically Generating Datasets for Query-Based Multi-Document Summarization
Oct 23, 2020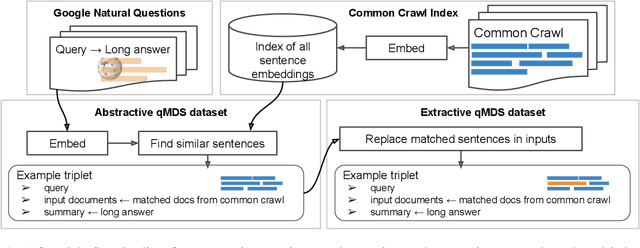

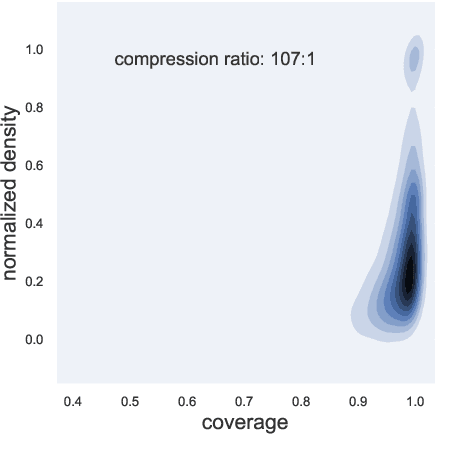
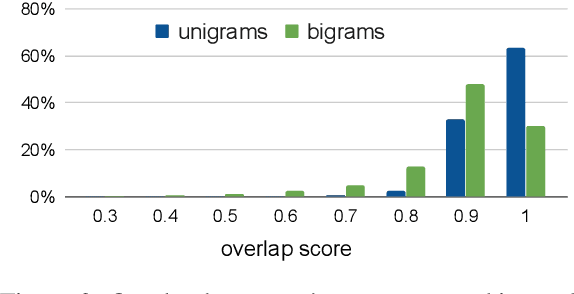
Summarization is the task of compressing source document(s) into coherent and succinct passages. This is a valuable tool to present users with concise and accurate sketch of the top ranked documents related to their queries. Query-based multi-document summarization (qMDS) addresses this pervasive need, but the research is severely limited due to lack of training and evaluation datasets as existing single-document and multi-document summarization datasets are inadequate in form and scale. We propose a scalable approach called AQuaMuSe to automatically mine qMDS examples from question answering datasets and large document corpora. Our approach is unique in the sense that it can general a dual dataset -- for extractive and abstractive summaries both. We publicly release a specific instance of an AQuaMuSe dataset with 5,519 query-based summaries, each associated with an average of 6 input documents selected from an index of 355M documents from Common Crawl. Extensive evaluation of the dataset along with baseline summarization model experiments are provided.