 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational-WENO: A lightweight, physically-consistent three-point weighted essentially non-oscillatory scheme
Sep 13, 2024



Conventional WENO3 methods are known to be highly dissipative at lower resolutions, introducing significant errors in the pre-asymptotic regime. In this paper, we employ a rational neural network to accurately estimate the local smoothness of the solution, dynamically adapting the stencil weights based on local solution features. As rational neural networks can represent fast transitions between smooth and sharp regimes, this approach achieves a granular reconstruction with significantly reduced dissipation, improving the accuracy of the simulation. The network is trained offline on a carefully chosen dataset of analytical functions, bypassing the need for differentiable solvers. We also propose a robust model selection criterion based on estimates of the interpolation's convergence order on a set of test functions, which correlates better with the model performance in downstream tasks. We demonstrate the effectiveness of our approach on several one-, two-, and three-dimensional fluid flow problems: our scheme generalizes across grid resolutions while handling smooth and discontinuous solutions. In most cases, our rational network-based scheme achieves higher accuracy than conventional WENO3 with the same stencil size, and in a few of them, it achieves accuracy comparable to WENO5, which uses a larger stencil.
Neural networks can be FLOP-efficient integrators of 1D oscillatory integrands
Apr 09, 2024



We demonstrate that neural networks can be FLOP-efficient integrators of one-dimensional oscillatory integrands. We train a feed-forward neural network to compute integrals of highly oscillatory 1D functions. The training set is a parametric combination of functions with varying characters and oscillatory behavior degrees. Numerical examples show that these networks are FLOP-efficient for sufficiently oscillatory integrands with an average FLOP gain of 1000 FLOPs. The network calculates oscillatory integrals better than traditional quadrature methods under the same computational budget or number of floating point operations. We find that feed-forward networks of 5 hidden layers are satisfactory for a relative accuracy of 0.001. The computational burden of inference of the neural network is relatively small, even compared to inner-product pattern quadrature rules. We postulate that our result follows from learning latent patterns in the oscillatory integrands that are otherwise opaque to traditional numerical integrators.
* 11 pages, 7 figures, 3 tables. Published in TMLR 03/2024. Code at https://github.com/comp-physics/deepOscillations
RoseNNa: A performant, portable library for neural network inference with application to computational fluid dynamics
Jul 30, 2023The rise of neural network-based machine learning ushered in high-level libraries, including TensorFlow and PyTorch, to support their functionality. Computational fluid dynamics (CFD) researchers have benefited from this trend and produced powerful neural networks that promise shorter simulation times. For example, multilayer perceptrons (MLPs) and Long Short Term Memory (LSTM) recurrent-based (RNN) architectures can represent sub-grid physical effects, like turbulence. Implementing neural networks in CFD solvers is challenging because the programming languages used for machine learning and CFD are mostly non-overlapping, We present the roseNNa library, which bridges the gap between neural network inference and CFD. RoseNNa is a non-invasive, lightweight (1000 lines), and performant tool for neural network inference, with focus on the smaller networks used to augment PDE solvers, like those of CFD, which are typically written in C/C++ or Fortran. RoseNNa accomplishes this by automatically converting trained models from typical neural network training packages into a high-performance Fortran library with C and Fortran APIs. This reduces the effort needed to access trained neural networks and maintains performance in the PDE solvers that CFD researchers build and rely upon. Results show that RoseNNa reliably outperforms PyTorch (Python) and libtorch (C++) on MLPs and LSTM RNNs with less than 100 hidden layers and 100 neurons per layer, even after removing the overhead cost of API calls. Speedups range from a factor of about 10 and 2 faster than these established libraries for the smaller and larger ends of the neural network size ranges tested.
Competitive Physics Informed Networks
Apr 23, 2022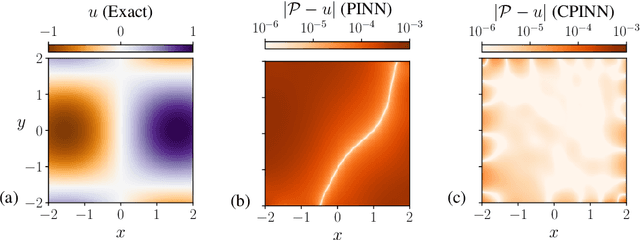

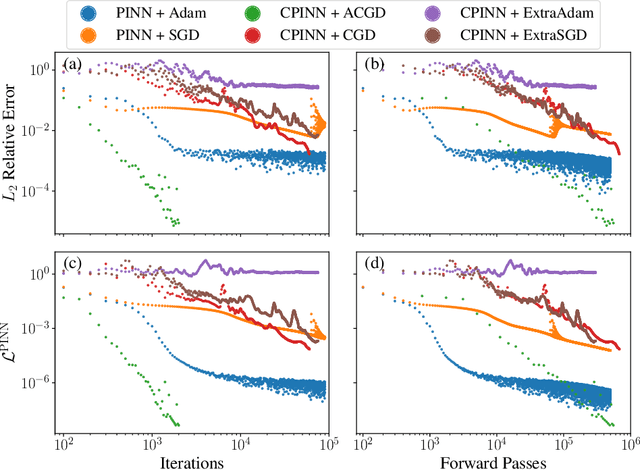

Physics Informed Neural Networks (PINNs) solve partial differential equations (PDEs) by representing them as neural networks. The original PINN implementation does not provide high accuracy, typically attaining about $0.1\%$ relative error. We formulate and test an adversarial approach called competitive PINNs (CPINNs) to overcome this limitation. CPINNs train a discriminator that is rewarded for predicting PINN mistakes. The discriminator and PINN participate in a zero-sum game with the exact PDE solution as an optimal strategy. This approach avoids the issue of squaring the large condition numbers of PDE discretizations. Numerical experiments show that a CPINN trained with competitive gradient descent can achieve errors two orders of magnitude smaller than that of a PINN trained with Adam or stochastic gradient descent.