 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs
Feb 13, 2025Despite advances in the multilingual capabilities of Large Language Models (LLMs) across diverse tasks, English remains the dominant language for LLM research and development. So, when working with a different language, this has led to the widespread practice of pre-translation, i.e., translating the task prompt into English before inference. Selective pre-translation, a more surgical approach, focuses on translating specific prompt components. However, its current use is sporagic and lacks a systematic research foundation. Consequently, the optimal pre-translation strategy for various multilingual settings and tasks remains unclear. In this work, we aim to uncover the optimal setup for pre-translation by systematically assessing its use. Specifically, we view the prompt as a modular entity, composed of four functional parts: instruction, context, examples, and output, either of which could be translated or not. We evaluate pre-translation strategies across 35 languages covering both low and high-resource languages, on various tasks including Question Answering (QA), Natural Language Inference (NLI), Named Entity Recognition (NER), and Abstractive Summarization. Our experiments show the impact of factors as similarity to English, translation quality and the size of pre-trained data, on the model performance with pre-translation. We suggest practical guidelines for choosing optimal strategies in various multilingual settings.
HeSum: a Novel Dataset for Abstractive Text Summarization in Hebrew
Jun 06, 2024While large language models (LLMs) excel in various natural language tasks in English, their performance in lower-resourced languages like Hebrew, especially for generative tasks such as abstractive summarization, remains unclear. The high morphological richness in Hebrew adds further challenges due to the ambiguity in sentence comprehension and the complexities in meaning construction. In this paper, we address this resource and evaluation gap by introducing HeSum, a novel benchmark specifically designed for abstractive text summarization in Modern Hebrew. HeSum consists of 10,000 article-summary pairs sourced from Hebrew news websites written by professionals. Linguistic analysis confirms HeSum's high abstractness and unique morphological challenges. We show that HeSum presents distinct difficulties for contemporary state-of-the-art LLMs, establishing it as a valuable testbed for generative language technology in Hebrew, and MRLs generative challenges in general.
HeGeL: A Novel Dataset for Geo-Location from Hebrew Text
Jul 02, 2023


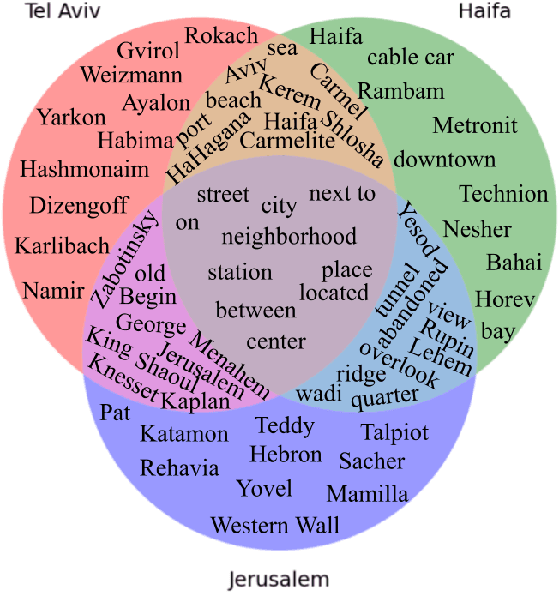
The task of textual geolocation - retrieving the coordinates of a place based on a free-form language description - calls for not only grounding but also natural language understanding and geospatial reasoning. Even though there are quite a few datasets in English used for geolocation, they are currently based on open-source data (Wikipedia and Twitter), where the location of the described place is mostly implicit, such that the location retrieval resolution is limited. Furthermore, there are no datasets available for addressing the problem of textual geolocation in morphologically rich and resource-poor languages, such as Hebrew. In this paper, we present the Hebrew Geo-Location (HeGeL) corpus, designed to collect literal place descriptions and analyze lingual geospatial reasoning. We crowdsourced 5,649 literal Hebrew place descriptions of various place types in three cities in Israel. Qualitative and empirical analysis show that the data exhibits abundant use of geospatial reasoning and requires a novel environmental representation.