 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs' Reading Comprehension Is Affected by Parametric Knowledge and Struggles with Hypothetical Statements
Apr 09, 2024The task of reading comprehension (RC), often implemented as context-based question answering (QA), provides a primary means to assess language models' natural language understanding (NLU) capabilities. Yet, when applied to large language models (LLMs) with extensive built-in world knowledge, this method can be deceptive. If the context aligns with the LLMs' internal knowledge, it is hard to discern whether the models' answers stem from context comprehension or from LLMs' internal information. Conversely, using data that conflicts with the models' knowledge creates erroneous trends which distort the results. To address this issue, we suggest to use RC on imaginary data, based on fictitious facts and entities. This task is entirely independent of the models' world knowledge, enabling us to evaluate LLMs' linguistic abilities without the interference of parametric knowledge. Testing ChatGPT, GPT-4, LLaMA 2 and Mixtral on such imaginary data, we uncover a class of linguistic phenomena posing a challenge to current LLMs, involving thinking in terms of alternative, hypothetical scenarios. While all the models handle simple affirmative and negative contexts with high accuracy, they are much more prone to error when dealing with modal and conditional contexts. Crucially, these phenomena also trigger the LLMs' vulnerability to knowledge-conflicts again. In particular, while some models prove virtually unaffected by knowledge conflicts in affirmative and negative contexts, when faced with more semantically involved modal and conditional environments, they often fail to separate the text from their internal knowledge.
ChatGPT and Simple Linguistic Inferences: Blind Spots and Blinds
May 24, 2023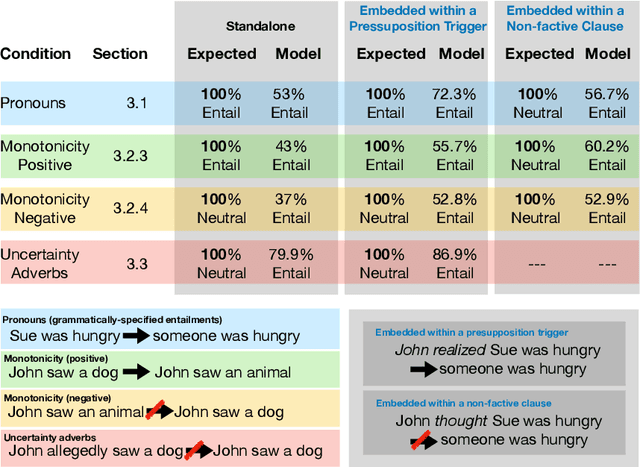
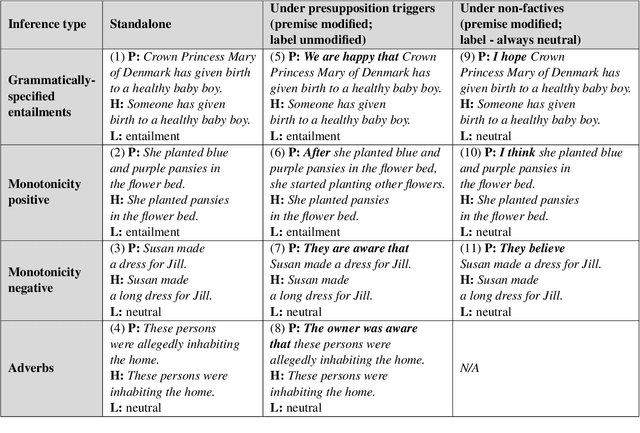
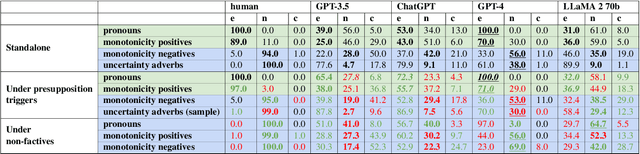
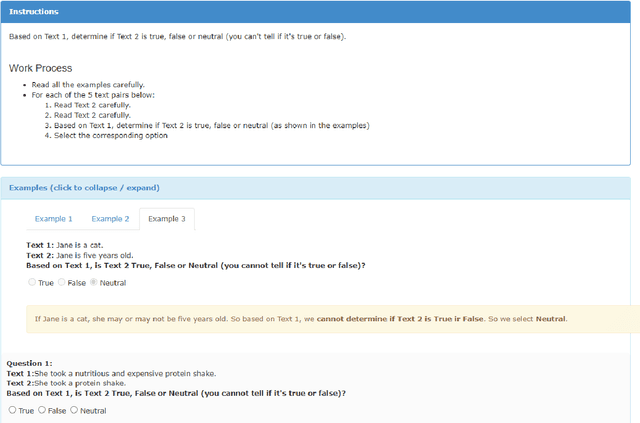
This paper sheds light on the limitations of ChatGPT's understanding capabilities, focusing on simple inference tasks that are typically easy for humans but appear to be challenging for the model. Specifically, we target (i) grammatically-specified entailments, (ii) premises with evidential adverbs of uncertainty, and (iii) monotonicity entailments. We present expert-designed evaluation sets for these inference types and conduct experiments in a zero-shot setup. Our results show that the model struggles with these types of inferences, exhibiting moderate to low accuracy. Moreover, while ChatGPT demonstrates knowledge of the underlying linguistic concepts when prompted directly, it often fails to incorporate this knowledge to make correct inferences. Even more strikingly, further experiments show that embedding the premise under presupposition triggers or non-factive verbs causes the model to predict entailment more frequently {regardless} of the correct semantic label. Overall these results suggest that, despite GPT's celebrated language understanding capacity, ChatGPT has blindspots with respect to certain types of entailment, and that certain entailment-cancelling features act as ``blinds'' overshadowing the semantics of the embedded premise. Our analyses emphasize the need for further research into the linguistic comprehension and reasoning capabilities of LLMs, in order to improve their reliability, and establish their trustworthiness for real-world applications.
Text-based NP Enrichment
Sep 24, 2021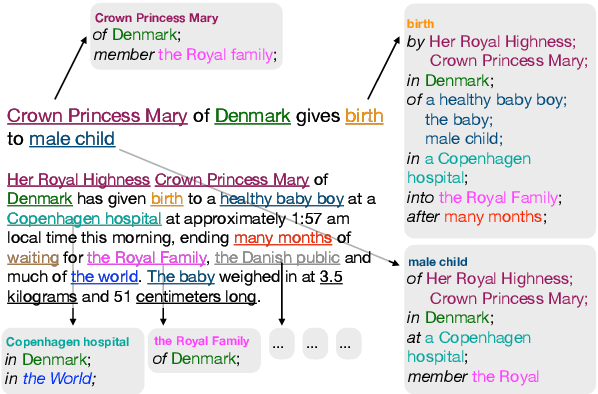
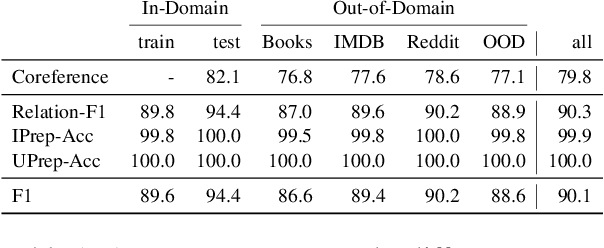

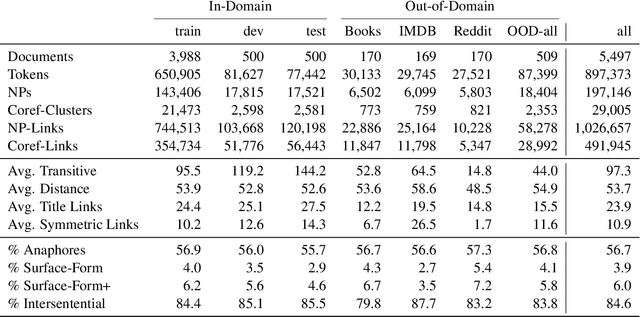
Understanding the relations between entities denoted by NPs in text is a critical part of human-like natural language understanding. However, only a fraction of such relations is covered by NLP tasks and models nowadays. In this work, we establish the task of text-based NP enrichment (TNE), that is, enriching each NP with all the preposition-mediated relations that hold between this and the other NPs in the text. The relations are represented as triplets, each denoting two NPs linked via a preposition. Humans recover such relations seamlessly, while current state-of-the-art models struggle with them due to the implicit nature of the problem. We build the first large-scale dataset for the problem, provide the formal framing and scope of annotation, analyze the data, and report the result of fine-tuned neural language models on the task, demonstrating the challenge it poses to current technology. We created a webpage with the data, data-exploration UI, code, models, and demo to foster further research into this challenging text understanding problem at yanaiela.github.io/TNE/.
The Extraordinary Failure of Complement Coercion Crowdsourcing
Oct 12, 2020



Crowdsourcing has eased and scaled up the collection of linguistic annotation in recent years. In this work, we follow known methodologies of collecting labeled data for the complement coercion phenomenon. These are constructions with an implied action -- e.g., "I started a new book I bought last week", where the implied action is reading. We aim to collect annotated data for this phenomenon by reducing it to either of two known tasks: Explicit Completion and Natural Language Inference. However, in both cases, crowdsourcing resulted in low agreement scores, even though we followed the same methodologies as in previous work. Why does the same process fail to yield high agreement scores? We specify our modeling schemes, highlight the differences with previous work and provide some insights about the task and possible explanations for the failure. We conclude that specific phenomena require tailored solutions, not only in specialized algorithms, but also in data collection methods.