 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT and Simple Linguistic Inferences: Blind Spots and Blinds
Paper and Code
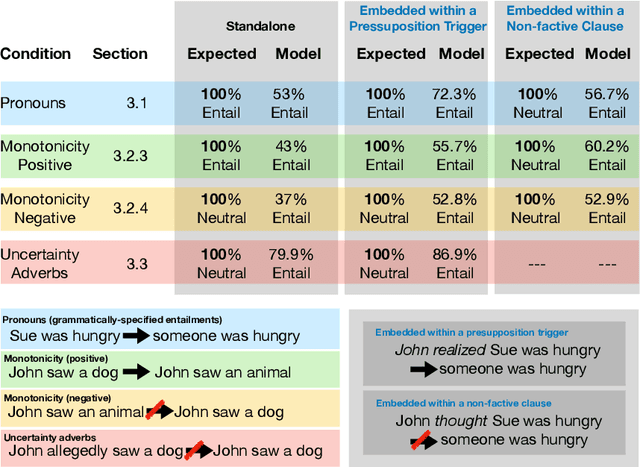
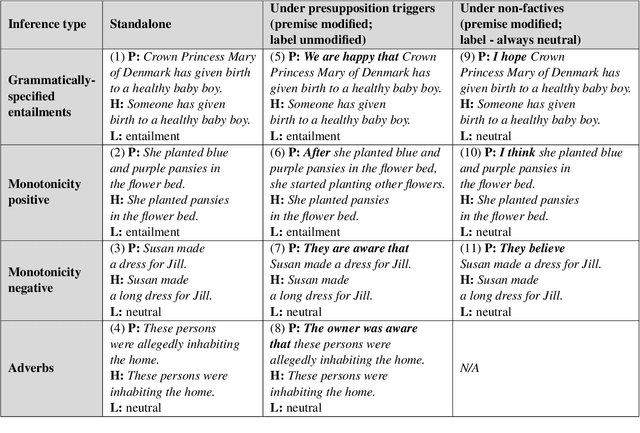
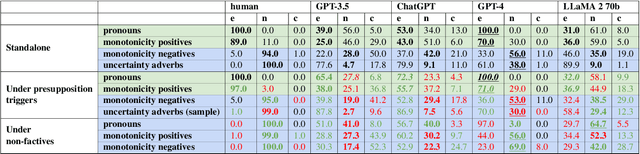
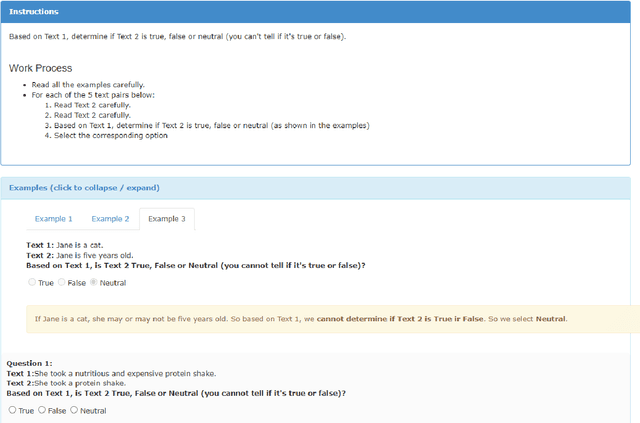
This paper sheds light on the limitations of ChatGPT's understanding capabilities, focusing on simple inference tasks that are typically easy for humans but appear to be challenging for the model. Specifically, we target (i) grammatically-specified entailments, (ii) premises with evidential adverbs of uncertainty, and (iii) monotonicity entailments. We present expert-designed evaluation sets for these inference types and conduct experiments in a zero-shot setup. Our results show that the model struggles with these types of inferences, exhibiting moderate to low accuracy. Moreover, while ChatGPT demonstrates knowledge of the underlying linguistic concepts when prompted directly, it often fails to incorporate this knowledge to make correct inferences. Even more strikingly, further experiments show that embedding the premise under presupposition triggers or non-factive verbs causes the model to predict entailment more frequently {regardless} of the correct semantic label. Overall these results suggest that, despite GPT's celebrated language understanding capacity, ChatGPT has blindspots with respect to certain types of entailment, and that certain entailment-cancelling features act as ``blinds'' overshadowing the semantics of the embedded premise. Our analyses emphasize the need for further research into the linguistic comprehension and reasoning capabilities of LLMs, in order to improve their reliability, and establish their trustworthiness for real-world applications.