 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Ensemble Learning Through Deep Energy-based Models
Jan 28, 2026Unsupervised ensemble learning emerged to address the challenge of combining multiple learners' predictions without access to ground truth labels or additional data. This paradigm is crucial in scenarios where evaluating individual classifier performance or understanding their strengths is challenging due to limited information. We propose a novel deep energy-based method for constructing an accurate meta-learner using only the predictions of individual learners, potentially capable of capturing complex dependence structures between them. Our approach requires no labeled data, learner features, or problem-specific information, and has theoretical guarantees for when learners are conditionally independent. We demonstrate superior performance across diverse ensemble scenarios, including challenging mixture of experts settings. Our experiments span standard ensemble datasets and curated datasets designed to test how the model fuses expertise from multiple sources. These results highlight the potential of unsupervised ensemble learning to harness collective intelligence, especially in data-scarce or privacy-sensitive environments.
RealStats: A Rigorous Real-Only Statistical Framework for Fake Image Detection
Jan 26, 2026As generative models continue to evolve, detecting AI-generated images remains a critical challenge. While effective detection methods exist, they often lack formal interpretability and may rely on implicit assumptions about fake content, potentially limiting robustness to distributional shifts. In this work, we introduce a rigorous, statistically grounded framework for fake image detection that focuses on producing a probability score interpretable with respect to the real-image population. Our method leverages the strengths of multiple existing detectors by combining training-free statistics. We compute p-values over a range of test statistics and aggregate them using classical statistical ensembling to assess alignment with the unified real-image distribution. This framework is generic, flexible, and training-free, making it well-suited for robust fake image detection across diverse and evolving settings.
P-CAFE: Personalized Cost-Aware Incremental Feature Selection For Electronic Health Records
Aug 12, 2025Electronic Health Records (EHR) have revolutionized healthcare by digitizing patient data, improving accessibility, and streamlining clinical workflows. However, extracting meaningful insights from these complex and multimodal datasets remains a significant challenge for researchers. Traditional feature selection methods often struggle with the inherent sparsity and heterogeneity of EHR data, especially when accounting for patient-specific variations and feature costs in clinical applications. To address these challenges, we propose a novel personalized, online and cost-aware feature selection framework tailored specifically for EHR datasets. The features are aquired in an online fashion for individual patients, incorporating budgetary constraints and feature variability costs. The framework is designed to effectively manage sparse and multimodal data, ensuring robust and scalable performance in diverse healthcare contexts. A primary application of our proposed method is to support physicians' decision making in patient screening scenarios. By guiding physicians toward incremental acquisition of the most informative features within budget constraints, our approach aims to increase diagnostic confidence while optimizing resource utilization.
Convexified Message-Passing Graph Neural Networks
May 23, 2025Graph Neural Networks (GNNs) have become prominent methods for graph representation learning, demonstrating strong empirical results on diverse graph prediction tasks. In this paper, we introduce Convexified Message Passing Graph Neural Networks (CGNNs), a novel and general framework that combines the power of message-passing GNNs with the tractability of convex optimization. By mapping their nonlinear filters into a reproducing kernel Hilbert space, CGNNs transform training into a convex optimization problem, which can be solved efficiently and optimally by projected gradient methods. This convexity further allows the statistical properties of CGNNs to be analyzed accurately and rigorously. For two-layer CGNNs, we establish rigorous generalization guarantees, showing convergence to the performance of the optimal GNN. To scale to deeper architectures, we adopt a principled layer-wise training strategy. Experiments on benchmark datasets show that CGNNs significantly exceed the performance of leading GNN models, achieving 10 to 40 percent higher accuracy in most cases, underscoring their promise as a powerful and principled method with strong theoretical foundations. In rare cases where improvements are not quantitatively substantial, the convex models either slightly exceed or match the baselines, stressing their robustness and wide applicability. Though over-parameterization is often employed to enhance performance in nonconvex models, we show that our CGNNs framework yields shallow convex models that can surpass these models in both accuracy and resource efficiency.
ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025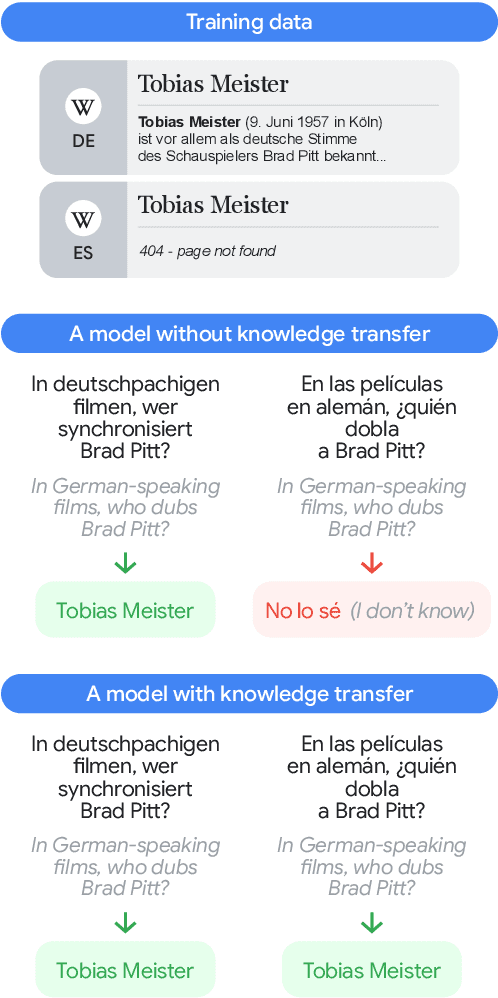
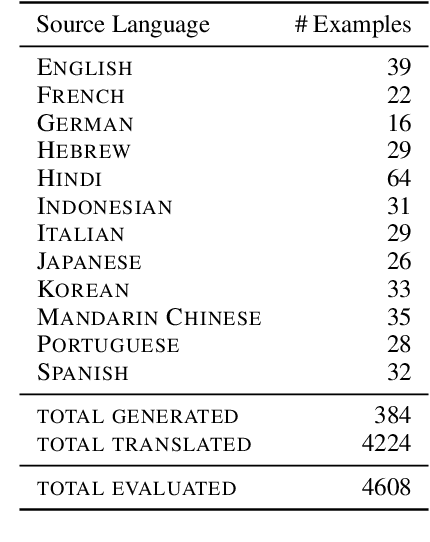
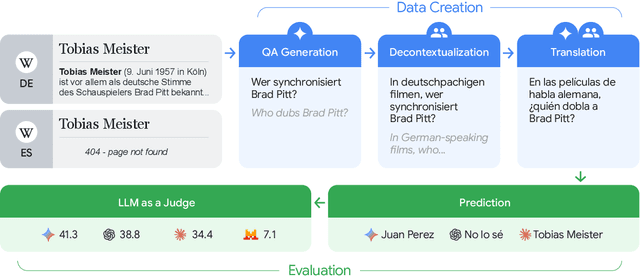
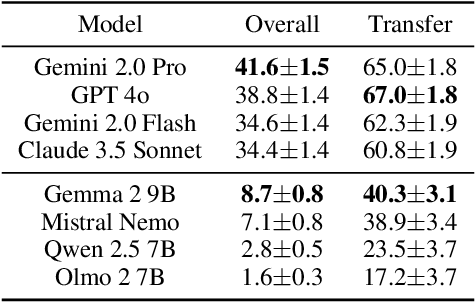
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
Generalizable Spectral Embedding with an Application to UMAP
Jan 20, 2025Spectral Embedding (SE) is a popular method for dimensionality reduction, applicable across diverse domains. Nevertheless, its current implementations face three prominent drawbacks which curtail its broader applicability: generalizability (i.e., out-of-sample extension), scalability, and eigenvectors separation. In this paper, we introduce GrEASE: Generalizable and Efficient Approximate Spectral Embedding, a novel deep-learning approach designed to address these limitations. GrEASE incorporates an efficient post-processing step to achieve eigenvectors separation, while ensuring both generalizability and scalability, allowing for the computation of the Laplacian's eigenvectors on unseen data. This method expands the applicability of SE to a wider range of tasks and can enhance its performance in existing applications. We empirically demonstrate GrEASE's ability to consistently approximate and generalize SE, while ensuring scalability. Additionally, we show how GrEASE can be leveraged to enhance existing methods. Specifically, we focus on UMAP, a leading visualization technique, and introduce NUMAP, a generalizable version of UMAP powered by GrEASE. Our codes are publicly available.
SpecRaGE: Robust and Generalizable Multi-view Spectral Representation Learning
Nov 04, 2024Multi-view representation learning (MvRL) has garnered substantial attention in recent years, driven by the increasing demand for applications that can effectively process and analyze data from multiple sources. In this context, graph Laplacian-based MvRL methods have demonstrated remarkable success in representing multi-view data. However, these methods often struggle with generalization to new data and face challenges with scalability. Moreover, in many practical scenarios, multi-view data is contaminated by noise or outliers. In such cases, modern deep-learning-based MvRL approaches that rely on alignment or contrastive objectives can lead to misleading results, as they may impose incorrect consistency between clear and corrupted data sources. We introduce $\textit{SpecRaGE}$, a novel fusion-based framework that integrates the strengths of graph Laplacian methods with the power of deep learning to overcome these challenges. SpecRage uses neural networks to learn parametric mapping that approximates a joint diagonalization of graph Laplacians. This solution bypasses the need for alignment while enabling generalizable and scalable learning of informative and meaningful representations. Moreover, it incorporates a meta-learning fusion module that dynamically adapts to data quality, ensuring robustness against outliers and noisy views. Our extensive experiments demonstrate that SpecRaGE outperforms state-of-the-art methods, particularly in scenarios with data contamination, paving the way for more reliable and efficient multi-view learning. Our code will be made publicly available upon acceptance.
G-SPARC: SPectral ARchitectures tackling the Cold-start problem in Graph learning
Nov 03, 2024



Graphs play a central role in modeling complex relationships across various domains. Most graph learning methods rely heavily on neighborhood information, raising the question of how to handle cold-start nodes - nodes with no known connections within the graph. These models often overlook the cold-start nodes, making them ineffective for real-world scenarios. To tackle this, we propose G-SPARC, a novel framework addressing cold-start nodes, that leverages generalizable spectral embedding. This framework enables extension to state-of-the-art methods making them suitable for practical applications. By utilizing a key idea of transitioning from graph representation to spectral representation, our approach is generalizable to cold-start nodes, capturing the global structure of the graph without relying on adjacency data. Experimental results demonstrate that our method outperforms existing models on cold-start nodes across various tasks like node classification, node clustering, and link prediction. G-SPARC provides a breakthrough built-in solution to the cold-start problem in graph learning. Our code will be publicly available upon acceptance.
CoverBench: A Challenging Benchmark for Complex Claim Verification
Aug 06, 2024
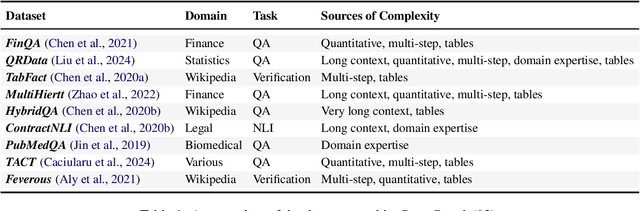
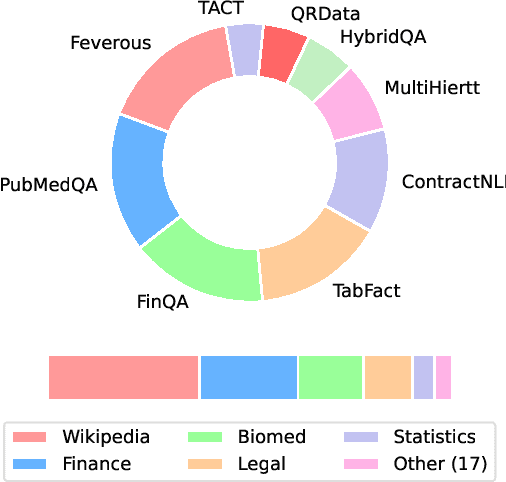
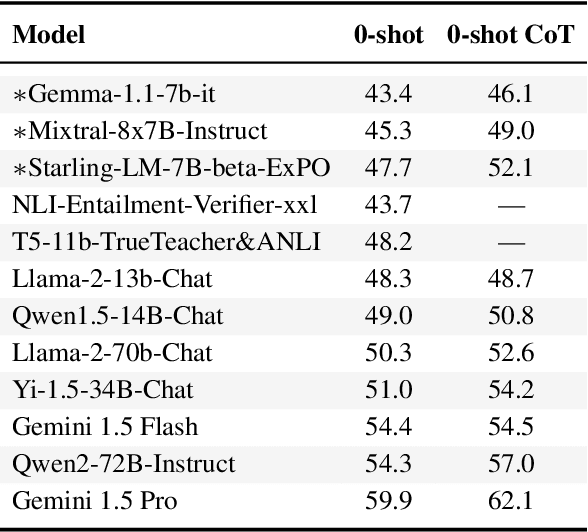
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .
Sparse Binarization for Fast Keyword Spotting
Jun 09, 2024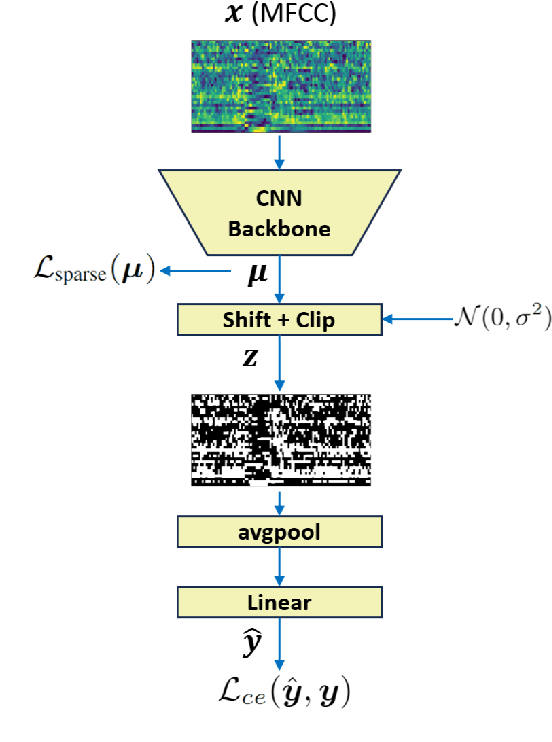

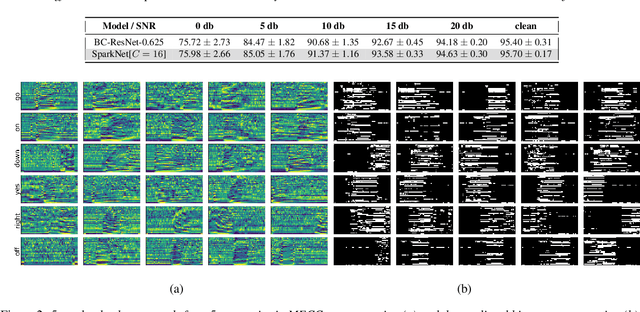
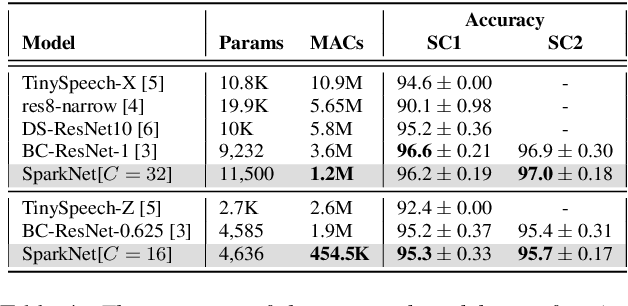
With the increasing prevalence of voice-activated devices and applications, keyword spotting (KWS) models enable users to interact with technology hands-free, enhancing convenience and accessibility in various contexts. Deploying KWS models on edge devices, such as smartphones and embedded systems, offers significant benefits for real-time applications, privacy, and bandwidth efficiency. However, these devices often possess limited computational power and memory. This necessitates optimizing neural network models for efficiency without significantly compromising their accuracy. To address these challenges, we propose a novel keyword-spotting model based on sparse input representation followed by a linear classifier. The model is four times faster than the previous state-of-the-art edge device-compatible model with better accuracy. We show that our method is also more robust in noisy environments while being fast. Our code is available at: https://github.com/jsvir/sparknet.