 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
Paper and Code
May 23, 2023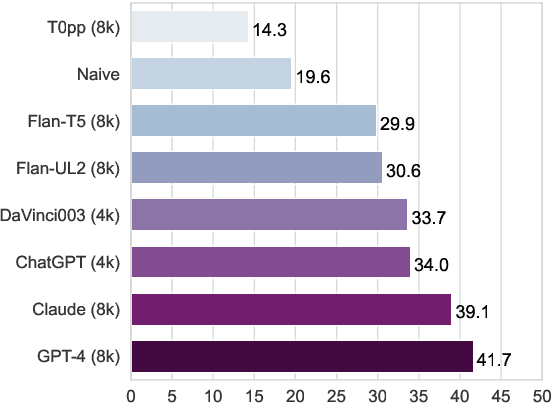
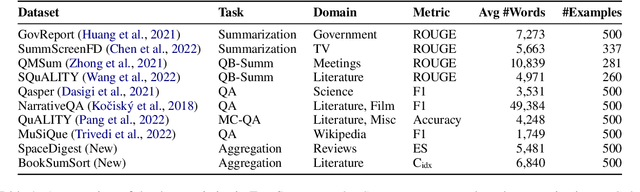
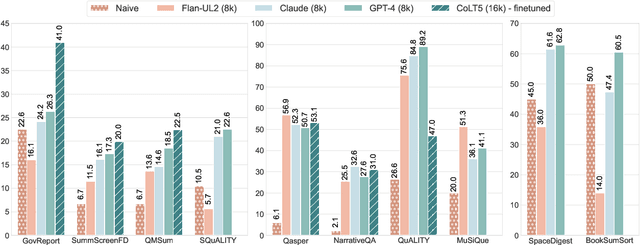
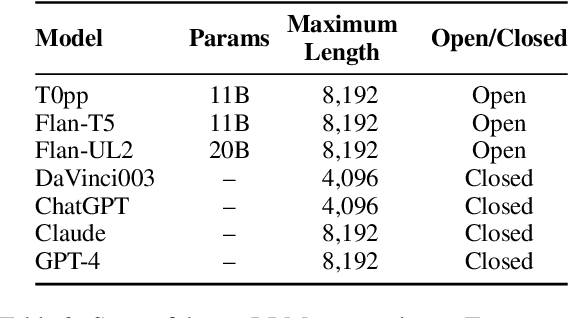
We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard