 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverBench: A Challenging Benchmark for Complex Claim Verification
Paper and Code
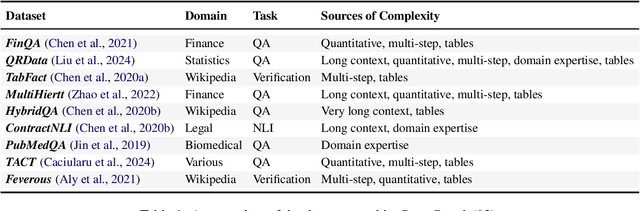
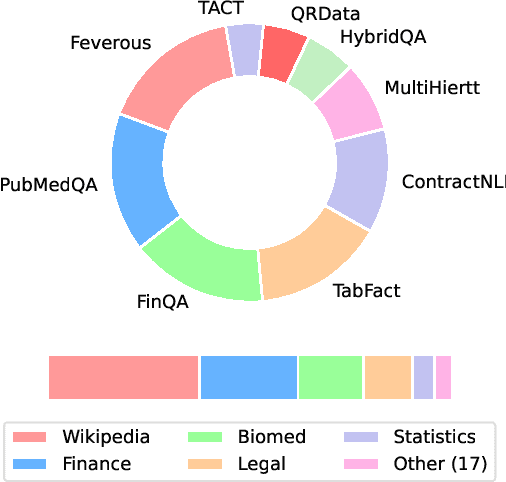
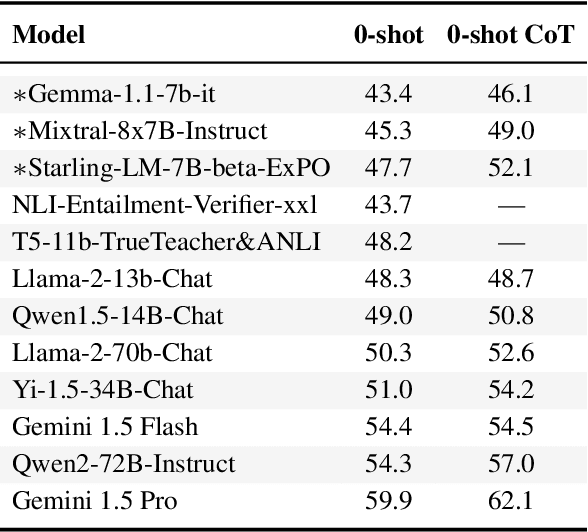
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .