 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDicta-LM 3.0: Advancing The Frontier of Hebrew Sovereign LLMs
Feb 02, 2026Open-weight LLMs have been released by frontier labs; however, sovereign Large Language Models (for languages other than English) remain low in supply yet high in demand. Training large language models (LLMs) for low-resource languages such as Hebrew poses unique challenges. In this paper, we introduce Dicta-LM 3.0: an open-weight collection of LLMs trained on substantially-sized corpora of Hebrew and English texts. The model is released in three sizes: 24B - adapted from the Mistral-Small-3.1 base model, 12B - adapted from the NVIDIA Nemotron Nano V2 model, and 1.7B - adapted from the Qwen3-1.7B base model. We are releasing multiple variants of each model, each with a native context length of 65k tokens; base model and chat model with tool-calling support. To rigorously evaluate our models, we introduce a new benchmark suite for evaluation of Hebrew chat-LLMs, covering a diverse set of tasks including Translation, Summarization, Winograd, Israeli Trivia, and Diacritization (nikud). Our work not only addresses the intricacies of training LLMs in low-resource languages but also proposes a framework that can be leveraged for adapting other LLMs to various non-English languages, contributing to the broader field of multilingual NLP.
NeoDictaBERT: Pushing the Frontier of BERT models for Hebrew
Oct 23, 2025Since their initial release, BERT models have demonstrated exceptional performance on a variety of tasks, despite their relatively small size (BERT-base has ~100M parameters). Nevertheless, the architectural choices used in these models are outdated compared to newer transformer-based models such as Llama3 and Qwen3. In recent months, several architectures have been proposed to close this gap. ModernBERT and NeoBERT both show strong improvements on English benchmarks and significantly extend the supported context window. Following their successes, we introduce NeoDictaBERT and NeoDictaBERT-bilingual: BERT-style models trained using the same architecture as NeoBERT, with a dedicated focus on Hebrew texts. These models outperform existing ones on almost all Hebrew benchmarks and provide a strong foundation for downstream tasks. Notably, the NeoDictaBERT-bilingual model shows strong results on retrieval tasks, outperforming other multilingual models of similar size. In this paper, we describe the training process and report results across various benchmarks. We release the models to the community as part of our goal to advance research and development in Hebrew NLP.
Adapting LLMs to Hebrew: Unveiling DictaLM 2.0 with Enhanced Vocabulary and Instruction Capabilities
Jul 09, 2024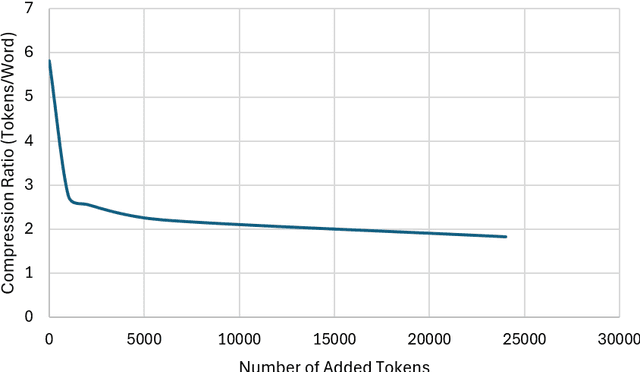
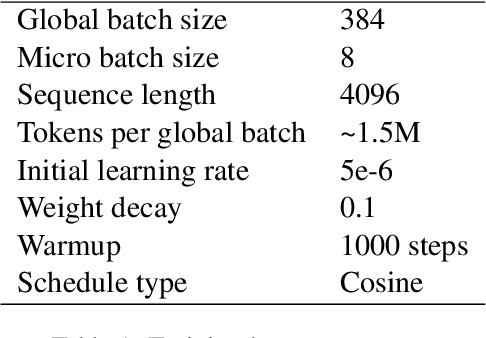
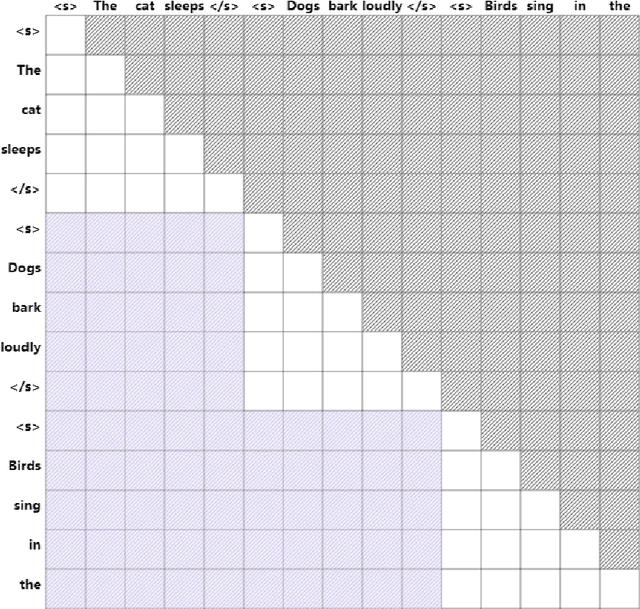
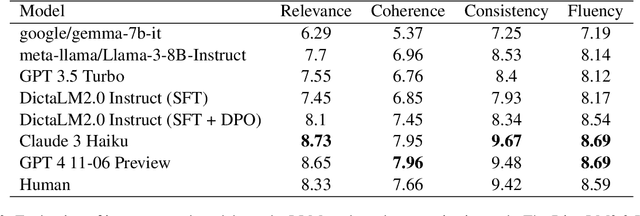
Training large language models (LLMs) in low-resource languages such as Hebrew poses unique challenges. In this paper, we introduce DictaLM2.0 and DictaLM2.0-Instruct, two LLMs derived from the Mistral model, trained on a substantial corpus of approximately 200 billion tokens in both Hebrew and English. Adapting a pre-trained model to a new language involves specialized techniques that differ significantly from training a model from scratch or further training existing models on well-resourced languages such as English. We outline these novel training methodologies, which facilitate effective learning and adaptation to the linguistic properties of Hebrew. Additionally, we fine-tuned DictaLM2.0-Instruct on a comprehensive instruct dataset to enhance its performance on task-specific instructions. To rigorously evaluate our models, we introduce a new benchmark suite for Hebrew LLM evaluation, covering a diverse set of tasks including Question Answering, Sentiment Analysis, Winograd Schema Challenge, Translation, and Summarization. Our work not only addresses the intricacies of training LLMs in low-resource languages but also proposes a framework that can be leveraged for adapting other LLMs to various non-English languages, contributing to the broader field of multilingual NLP.
Do Pretrained Contextual Language Models Distinguish between Hebrew Homograph Analyses?
May 11, 2024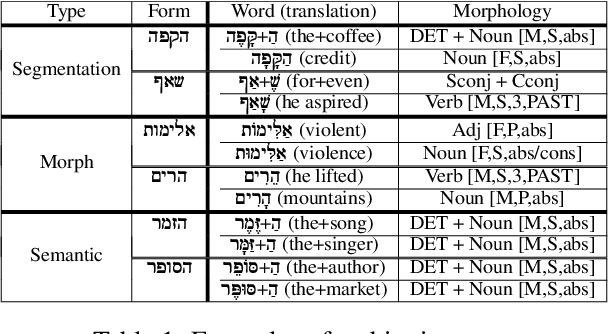
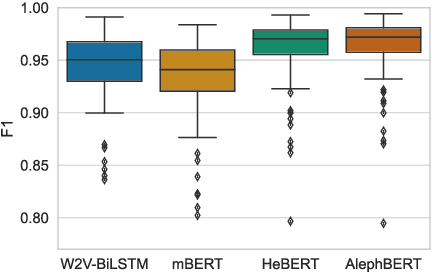
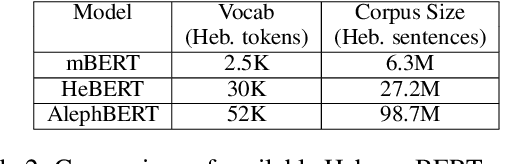
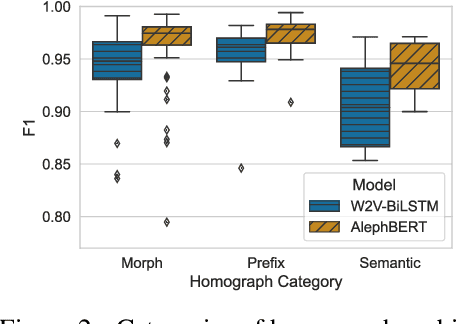
Semitic morphologically-rich languages (MRLs) are characterized by extreme word ambiguity. Because most vowels are omitted in standard texts, many of the words are homographs with multiple possible analyses, each with a different pronunciation and different morphosyntactic properties. This ambiguity goes beyond word-sense disambiguation (WSD), and may include token segmentation into multiple word units. Previous research on MRLs claimed that standardly trained pre-trained language models (PLMs) based on word-pieces may not sufficiently capture the internal structure of such tokens in order to distinguish between these analyses. Taking Hebrew as a case study, we investigate the extent to which Hebrew homographs can be disambiguated and analyzed using PLMs. We evaluate all existing models for contextualized Hebrew embeddings on a novel Hebrew homograph challenge sets that we deliver. Our empirical results demonstrate that contemporary Hebrew contextualized embeddings outperform non-contextualized embeddings; and that they are most effective for disambiguating segmentation and morphosyntactic features, less so regarding pure word-sense disambiguation. We show that these embeddings are more effective when the number of word-piece splits is limited, and they are more effective for 2-way and 3-way ambiguities than for 4-way ambiguity. We show that the embeddings are equally effective for homographs of both balanced and skewed distributions, whether calculated as masked or unmasked tokens. Finally, we show that these embeddings are as effective for homograph disambiguation with extensive supervised training as with a few-shot setup.
MRL Parsing Without Tears: The Case of Hebrew
Mar 11, 2024



Syntactic parsing remains a critical tool for relation extraction and information extraction, especially in resource-scarce languages where LLMs are lacking. Yet in morphologically rich languages (MRLs), where parsers need to identify multiple lexical units in each token, existing systems suffer in latency and setup complexity. Some use a pipeline to peel away the layers: first segmentation, then morphology tagging, and then syntax parsing; however, errors in earlier layers are then propagated forward. Others use a joint architecture to evaluate all permutations at once; while this improves accuracy, it is notoriously slow. In contrast, and taking Hebrew as a test case, we present a new "flipped pipeline": decisions are made directly on the whole-token units by expert classifiers, each one dedicated to one specific task. The classifiers are independent of one another, and only at the end do we synthesize their predictions. This blazingly fast approach sets a new SOTA in Hebrew POS tagging and dependency parsing, while also reaching near-SOTA performance on other Hebrew NLP tasks. Because our architecture does not rely on any language-specific resources, it can serve as a model to develop similar parsers for other MRLs.
Introducing DictaLM -- A Large Generative Language Model for Modern Hebrew
Sep 25, 2023We present DictaLM, a large-scale language model tailored for Modern Hebrew. Boasting 7B parameters, this model is predominantly trained on Hebrew-centric data. As a commitment to promoting research and development in the Hebrew language, we release both the foundation model and the instruct-tuned model under a Creative Commons license. Concurrently, we introduce DictaLM-Rab, another foundation model geared towards Rabbinic/Historical Hebrew. These foundation models serve as ideal starting points for fine-tuning various Hebrew-specific tasks, such as instruction, Q&A, sentiment analysis, and more. This release represents a preliminary step, offering an initial Hebrew LLM model for the Hebrew NLP community to experiment with.
DictaBERT: A State-of-the-Art BERT Suite for Modern Hebrew
Aug 31, 2023We present DictaBERT, a new state-of-the-art pre-trained BERT model for modern Hebrew, outperforming existing models on most benchmarks. Additionally, we release two fine-tuned versions of the model, designed to perform two specific foundational tasks in the analysis of Hebrew texts: prefix segmentation and morphological tagging. These fine-tuned models allow any developer to perform prefix segmentation and morphological tagging of a Hebrew sentence with a single call to a HuggingFace model, without the need to integrate any additional libraries or code. In this paper we describe the details of the training as well and the results on the different benchmarks. We release the models to the community, along with sample code demonstrating their use. We release these models as part of our goal to help further research and development in Hebrew NLP.
Large Pre-Trained Models with Extra-Large Vocabularies: A Contrastive Analysis of Hebrew BERT Models and a New One to Outperform Them All
Nov 28, 2022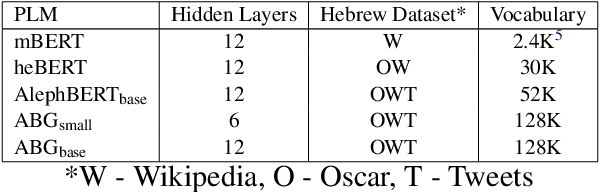
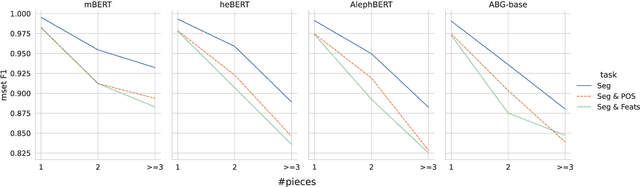

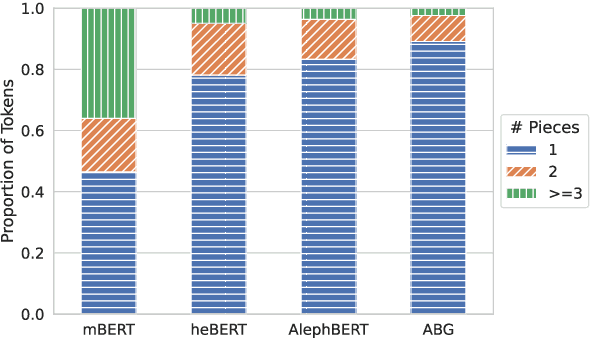
We present a new pre-trained language model (PLM) for modern Hebrew, termed AlephBERTGimmel, which employs a much larger vocabulary (128K items) than standard Hebrew PLMs before. We perform a contrastive analysis of this model against all previous Hebrew PLMs (mBERT, heBERT, AlephBERT) and assess the effects of larger vocabularies on task performance. Our experiments show that larger vocabularies lead to fewer splits, and that reducing splits is better for model performance, across different tasks. All in all this new model achieves new SOTA on all available Hebrew benchmarks, including Morphological Segmentation, POS Tagging, Full Morphological Analysis, NER, and Sentiment Analysis. Subsequently we advocate for PLMs that are larger not only in terms of number of layers or training data, but also in terms of their vocabulary. We release the new model publicly for unrestricted use.
Introducing BEREL: BERT Embeddings for Rabbinic-Encoded Language
Aug 03, 2022We present a new pre-trained language model (PLM) for Rabbinic Hebrew, termed Berel (BERT Embeddings for Rabbinic-Encoded Language). Whilst other PLMs exist for processing Hebrew texts (e.g., HeBERT, AlephBert), they are all trained on modern Hebrew texts, which diverges substantially from Rabbinic Hebrew in terms of its lexicographical, morphological, syntactic and orthographic norms. We demonstrate the superiority of Berel on Rabbinic texts via a challenge set of Hebrew homographs. We release the new model and homograph challenge set for unrestricted use.
A Novel Challenge Set for Hebrew Morphological Disambiguation and Diacritics Restoration
Oct 06, 2020One of the primary tasks of morphological parsers is the disambiguation of homographs. Particularly difficult are cases of unbalanced ambiguity, where one of the possible analyses is far more frequent than the others. In such cases, there may not exist sufficient examples of the minority analyses in order to properly evaluate performance, nor to train effective classifiers. In this paper we address the issue of unbalanced morphological ambiguities in Hebrew. We offer a challenge set for Hebrew homographs -- the first of its kind -- containing substantial attestation of each analysis of 21 Hebrew homographs. We show that the current SOTA of Hebrew disambiguation performs poorly on cases of unbalanced ambiguity. Leveraging our new dataset, we achieve a new state-of-the-art for all 21 words, improving the overall average F1 score from 0.67 to 0.95. Our resulting annotated datasets are made publicly available for further research.