 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Pre-Trained Models with Extra-Large Vocabularies: A Contrastive Analysis of Hebrew BERT Models and a New One to Outperform Them All
Nov 28, 2022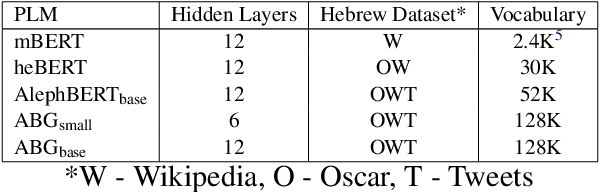
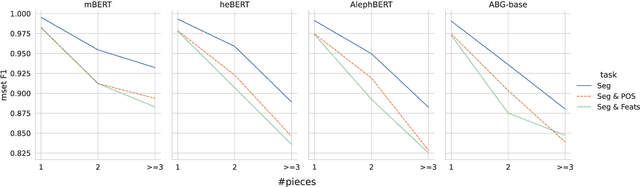

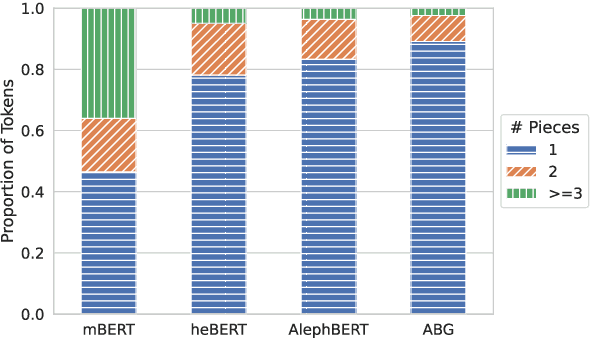
We present a new pre-trained language model (PLM) for modern Hebrew, termed AlephBERTGimmel, which employs a much larger vocabulary (128K items) than standard Hebrew PLMs before. We perform a contrastive analysis of this model against all previous Hebrew PLMs (mBERT, heBERT, AlephBERT) and assess the effects of larger vocabularies on task performance. Our experiments show that larger vocabularies lead to fewer splits, and that reducing splits is better for model performance, across different tasks. All in all this new model achieves new SOTA on all available Hebrew benchmarks, including Morphological Segmentation, POS Tagging, Full Morphological Analysis, NER, and Sentiment Analysis. Subsequently we advocate for PLMs that are larger not only in terms of number of layers or training data, but also in terms of their vocabulary. We release the new model publicly for unrestricted use.
Introducing BEREL: BERT Embeddings for Rabbinic-Encoded Language
Aug 03, 2022We present a new pre-trained language model (PLM) for Rabbinic Hebrew, termed Berel (BERT Embeddings for Rabbinic-Encoded Language). Whilst other PLMs exist for processing Hebrew texts (e.g., HeBERT, AlephBert), they are all trained on modern Hebrew texts, which diverges substantially from Rabbinic Hebrew in terms of its lexicographical, morphological, syntactic and orthographic norms. We demonstrate the superiority of Berel on Rabbinic texts via a challenge set of Hebrew homographs. We release the new model and homograph challenge set for unrestricted use.
A Novel Challenge Set for Hebrew Morphological Disambiguation and Diacritics Restoration
Oct 06, 2020One of the primary tasks of morphological parsers is the disambiguation of homographs. Particularly difficult are cases of unbalanced ambiguity, where one of the possible analyses is far more frequent than the others. In such cases, there may not exist sufficient examples of the minority analyses in order to properly evaluate performance, nor to train effective classifiers. In this paper we address the issue of unbalanced morphological ambiguities in Hebrew. We offer a challenge set for Hebrew homographs -- the first of its kind -- containing substantial attestation of each analysis of 21 Hebrew homographs. We show that the current SOTA of Hebrew disambiguation performs poorly on cases of unbalanced ambiguity. Leveraging our new dataset, we achieve a new state-of-the-art for all 21 words, improving the overall average F1 score from 0.67 to 0.95. Our resulting annotated datasets are made publicly available for further research.