 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Pre-Trained Models with Extra-Large Vocabularies: A Contrastive Analysis of Hebrew BERT Models and a New One to Outperform Them All
Nov 28, 2022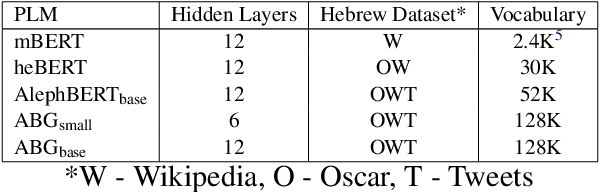
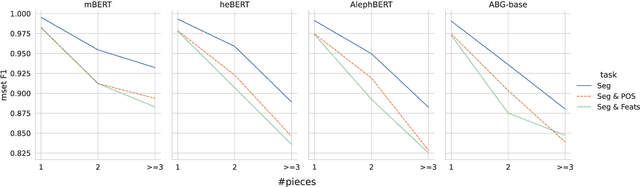

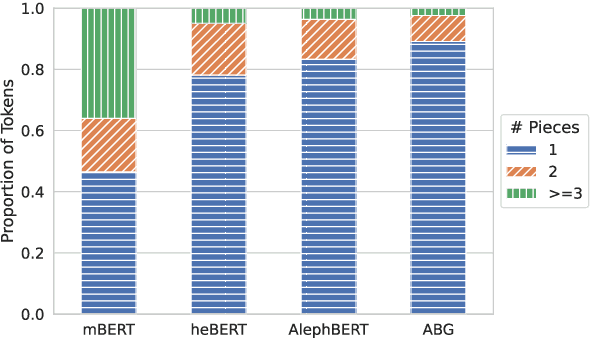
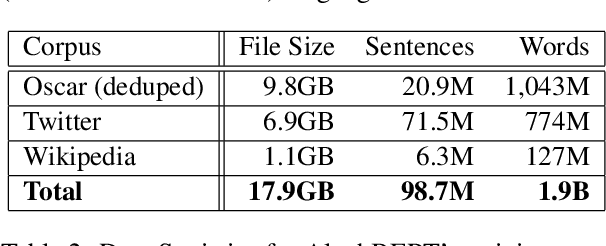
We present a new pre-trained language model (PLM) for modern Hebrew, termed AlephBERTGimmel, which employs a much larger vocabulary (128K items) than standard Hebrew PLMs before. We perform a contrastive analysis of this model against all previous Hebrew PLMs (mBERT, heBERT, AlephBERT) and assess the effects of larger vocabularies on task performance. Our experiments show that larger vocabularies lead to fewer splits, and that reducing splits is better for model performance, across different tasks. All in all this new model achieves new SOTA on all available Hebrew benchmarks, including Morphological Segmentation, POS Tagging, Full Morphological Analysis, NER, and Sentiment Analysis. Subsequently we advocate for PLMs that are larger not only in terms of number of layers or training data, but also in terms of their vocabulary. We release the new model publicly for unrestricted use.
AlephBERT:A Hebrew Large Pre-Trained Language Model to Start-off your Hebrew NLP Application With
Apr 08, 2021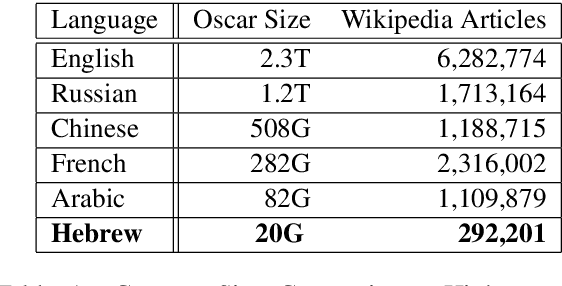

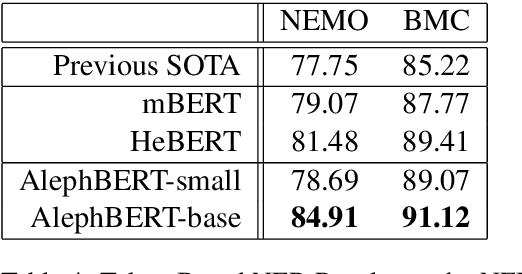
Large Pre-trained Language Models (PLMs) have become ubiquitous in the development of language understanding technology and lie at the heart of many artificial intelligence advances. While advances reported for English using PLMs are unprecedented, reported advances using PLMs in Hebrew are few and far between. The problem is twofold. First, Hebrew resources available for training NLP models are not at the same order of magnitude as their English counterparts. Second, there are no accepted tasks and benchmarks to evaluate the progress of Hebrew PLMs on. In this work we aim to remedy both aspects. First, we present AlephBERT, a large pre-trained language model for Modern Hebrew, which is trained on larger vocabulary and a larger dataset than any Hebrew PLM before. Second, using AlephBERT we present new state-of-the-art results on multiple Hebrew tasks and benchmarks, including: Segmentation, Part-of-Speech Tagging, full Morphological Tagging, Named-Entity Recognition and Sentiment Analysis. We make our AlephBERT model publicly available, providing a single point of entry for the development of Hebrew NLP applications.
From SPMRL to NMRL: What Did We Learn in a Decade of Parsing Morphologically-Rich Languages ?
May 04, 2020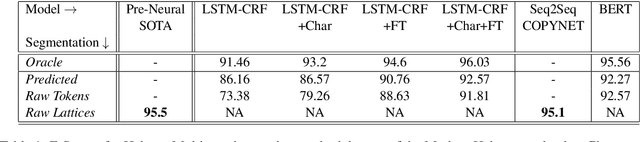
It has been exactly a decade since the first establishment of SPMRL, a research initiative unifying multiple research efforts to address the peculiar challenges of Statistical Parsing for Morphologically-Rich Languages (MRLs).Here we reflect on parsing MRLs in that decade, highlight the solutions and lessons learned for the architectural, modeling and lexical challenges in the pre-neural era, and argue that similar challenges re-emerge in neural architectures for MRLs. We then aim to offer a climax, suggesting that incorporating symbolic ideas proposed in SPMRL terms into nowadays neural architectures has the potential to push NLP for MRLs to a new level. We sketch strategies for designing Neural Models for MRLs (NMRL), and showcase preliminary support for these strategies via investigating the task of multi-tagging in Hebrew, a morphologically-rich, high-fusion, language
What's Wrong with Hebrew NLP? And How to Make it Right
Aug 15, 2019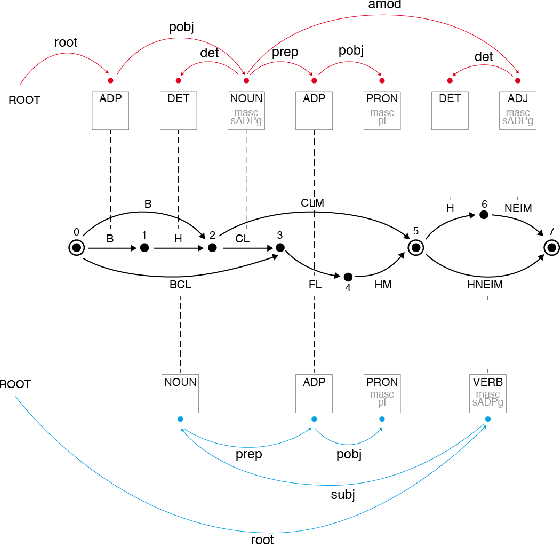
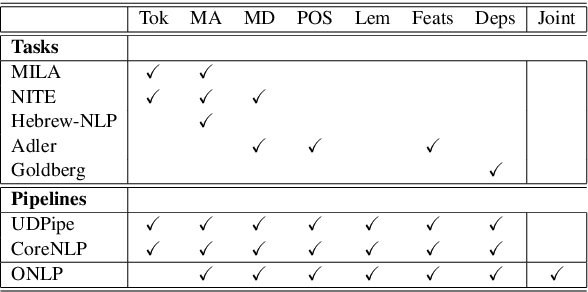
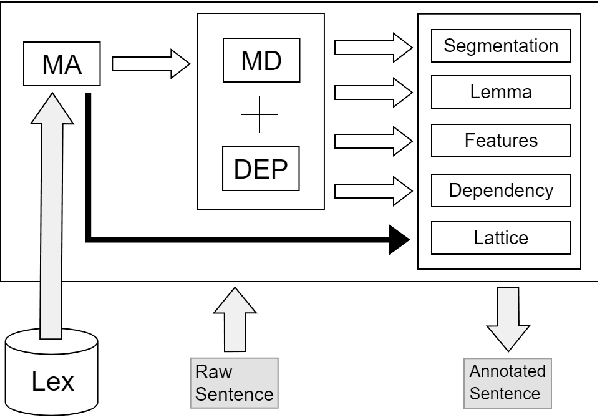
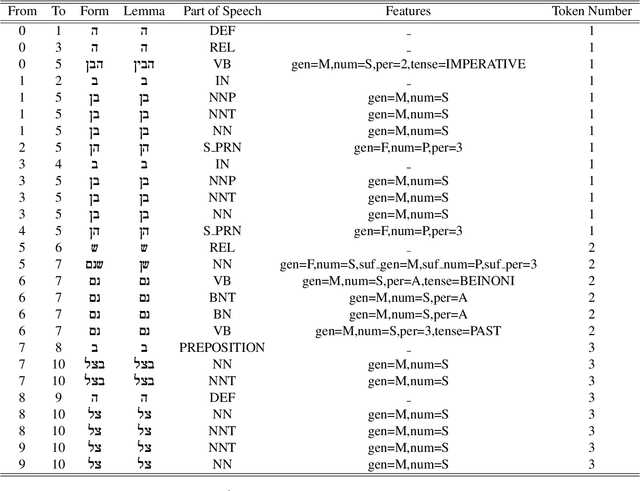
For languages with simple morphology, such as English, automatic annotation pipelines such as spaCy or Stanford's CoreNLP successfully serve projects in academia and the industry. For many morphologically-rich languages (MRLs), similar pipelines show sub-optimal performance that limits their applicability for text analysis in research and the industry.The sub-optimal performance is mainly due to errors in early morphological disambiguation decisions, which cannot be recovered later in the pipeline, yielding incoherent annotations on the whole. In this paper we describe the design and use of the Onlp suite, a joint morpho-syntactic parsing framework for processing Modern Hebrew texts. The joint inference over morphology and syntax substantially limits error propagation, and leads to high accuracy. Onlp provides rich and expressive output which already serves diverse academic and commercial needs. Its accompanying online demo further serves educational activities, introducing Hebrew NLP intricacies to researchers and non-researchers alike.