 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM-Debugger: An Interactive Tool for Inspection and Intervention in Transformer-Based Language Models
Apr 26, 2022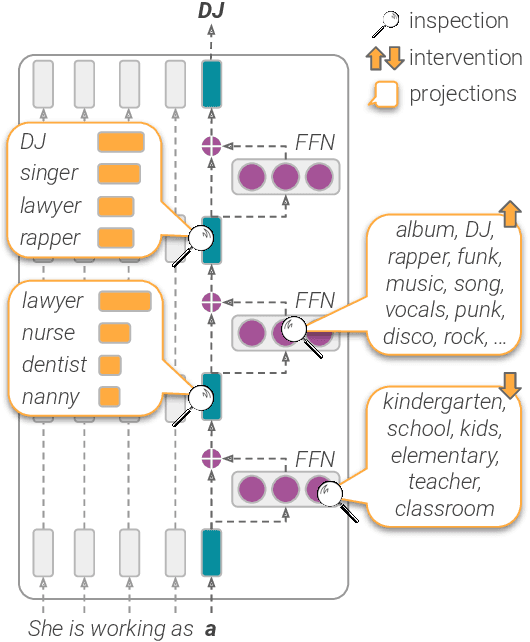

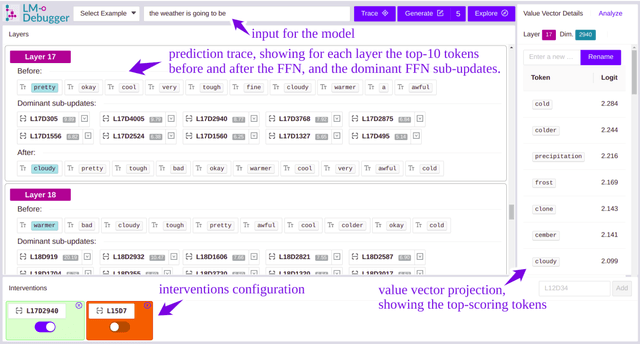

The opaque nature and unexplained behavior of transformer-based language models (LMs) have spurred a wide interest in interpreting their predictions. However, current interpretation methods mostly focus on probing models from outside, executing behavioral tests, and analyzing salience input features, while the internal prediction construction process is largely not understood. In this work, we introduce LM-Debugger, an interactive debugger tool for transformer-based LMs, which provides a fine-grained interpretation of the model's internal prediction process, as well as a powerful framework for intervening in LM behavior. For its backbone, LM-Debugger relies on a recent method that interprets the inner token representations and their updates by the feed-forward layers in the vocabulary space. We demonstrate the utility of LM-Debugger for single-prediction debugging, by inspecting the internal disambiguation process done by GPT2. Moreover, we show how easily LM-Debugger allows to shift model behavior in a direction of the user's choice, by identifying a few vectors in the network and inducing effective interventions to the prediction process. We release LM-Debugger as an open-source tool and a demo over GPT2 models.
Large Scale Substitution-based Word Sense Induction
Oct 14, 2021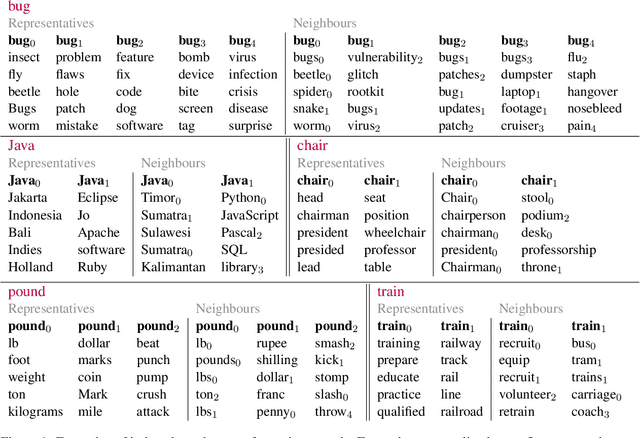


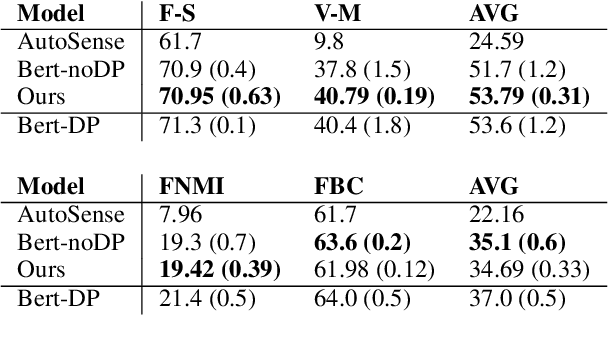
We present a word-sense induction method based on pre-trained masked language models (MLMs), which can cheaply scale to large vocabularies and large corpora. The result is a corpus which is sense-tagged according to a corpus-derived sense inventory and where each sense is associated with indicative words. Evaluation on English Wikipedia that was sense-tagged using our method shows that both the induced senses, and the per-instance sense assignment, are of high quality even compared to WSD methods, such as Babelfy. Furthermore, by training a static word embeddings algorithm on the sense-tagged corpus, we obtain high-quality static senseful embeddings. These outperform existing senseful embeddings techniques on the WiC dataset and on a new outlier detection dataset we developed. The data driven nature of the algorithm allows to induce corpora-specific senses, which may not appear in standard sense inventories, as we demonstrate using a case study on the scientific domain.
The Possible, the Plausible, and the Desirable: Event-Based Modality Detection for Language Processing
Jun 15, 2021
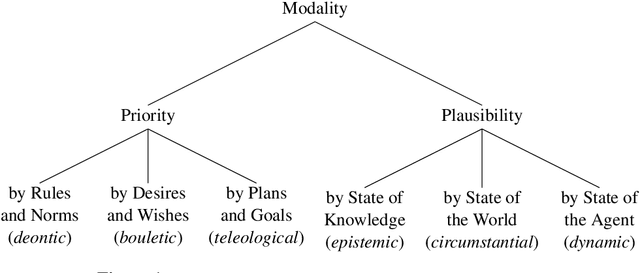

Modality is the linguistic ability to describe events with added information such as how desirable, plausible, or feasible they are. Modality is important for many NLP downstream tasks such as the detection of hedging, uncertainty, speculation, and more. Previous studies that address modality detection in NLP often restrict modal expressions to a closed syntactic class, and the modal sense labels are vastly different across different studies, lacking an accepted standard. Furthermore, these senses are often analyzed independently of the events that they modify. This work builds on the theoretical foundations of the Georgetown Gradable Modal Expressions (GME) work by Rubinstein et al. (2013) to propose an event-based modality detection task where modal expressions can be words of any syntactic class and sense labels are drawn from a comprehensive taxonomy which harmonizes the modal concepts contributed by the different studies. We present experiments on the GME corpus aiming to detect and classify fine-grained modal concepts and associate them with their modified events. We show that detecting and classifying modal expressions is not only feasible, but also improves the detection of modal events in their own right.
Interactive Extractive Search over Biomedical Corpora
Jun 07, 2020

We present a system that allows life-science researchers to search a linguistically annotated corpus of scientific texts using patterns over dependency graphs, as well as using patterns over token sequences and a powerful variant of boolean keyword queries. In contrast to previous attempts to dependency-based search, we introduce a light-weight query language that does not require the user to know the details of the underlying linguistic representations, and instead to query the corpus by providing an example sentence coupled with simple markup. Search is performed at an interactive speed due to efficient linguistic graph-indexing and retrieval engine. This allows for rapid exploration, development and refinement of user queries. We demonstrate the system using example workflows over two corpora: the PubMed corpus including 14,446,243 PubMed abstracts and the CORD-19 dataset, a collection of over 45,000 research papers focused on COVID-19 research. The system is publicly available at https://allenai.github.io/spike
Syntactic Search by Example
Jun 04, 2020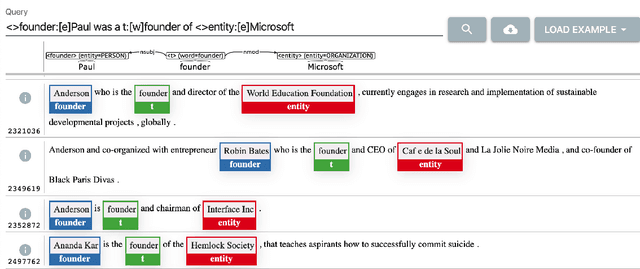
We present a system that allows a user to search a large linguistically annotated corpus using syntactic patterns over dependency graphs. In contrast to previous attempts to this effect, we introduce a light-weight query language that does not require the user to know the details of the underlying syntactic representations, and instead to query the corpus by providing an example sentence coupled with simple markup. Search is performed at an interactive speed due to an efficient linguistic graph-indexing and retrieval engine. This allows for rapid exploration, development and refinement of syntax-based queries. We demonstrate the system using queries over two corpora: the English wikipedia, and a collection of English pubmed abstracts. A demo of the wikipedia system is available at: https://allenai.github.io/spike
What's Wrong with Hebrew NLP? And How to Make it Right
Aug 15, 2019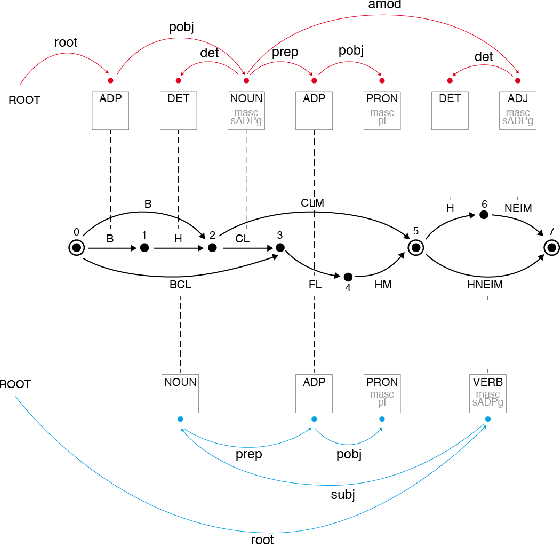
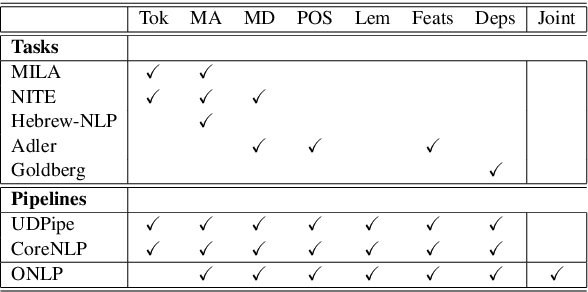
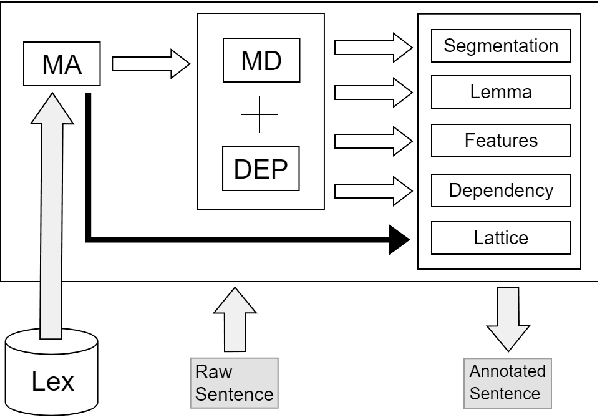
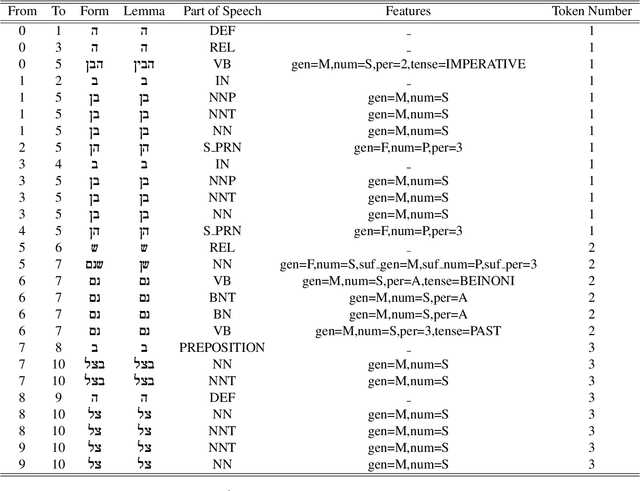
For languages with simple morphology, such as English, automatic annotation pipelines such as spaCy or Stanford's CoreNLP successfully serve projects in academia and the industry. For many morphologically-rich languages (MRLs), similar pipelines show sub-optimal performance that limits their applicability for text analysis in research and the industry.The sub-optimal performance is mainly due to errors in early morphological disambiguation decisions, which cannot be recovered later in the pipeline, yielding incoherent annotations on the whole. In this paper we describe the design and use of the Onlp suite, a joint morpho-syntactic parsing framework for processing Modern Hebrew texts. The joint inference over morphology and syntax substantially limits error propagation, and leads to high accuracy. Onlp provides rich and expressive output which already serves diverse academic and commercial needs. Its accompanying online demo further serves educational activities, introducing Hebrew NLP intricacies to researchers and non-researchers alike.