 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSastBench: A Benchmark for Testing Agentic SAST Triage
Jan 06, 2026SAST (Static Application Security Testing) tools are among the most widely used techniques in defensive cybersecurity, employed by commercial and non-commercial organizations to identify potential vulnerabilities in software. Despite their great utility, they generate numerous false positives, requiring costly manual filtering (aka triage). While LLM-powered agents show promise for automating cybersecurity tasks, existing benchmarks fail to emulate real-world SAST finding distributions. We introduce SastBench, a benchmark for evaluating SAST triage agents that combines real CVEs as true positives with filtered SAST tool findings as approximate false positives. SastBench features an agent-agnostic design. We evaluate different agents on the benchmark and present a comparative analysis of their performance, provide a detailed analysis of the dataset, and discuss the implications for future development.
In-context Learning and Gradient Descent Revisited
Nov 18, 2023In-context learning (ICL) has shown impressive results in few-shot learning tasks, yet its underlying mechanism is still not fully understood. Recent works suggest that ICL can be thought of as a gradient descent (GD) based optimization process. While promising, these results mainly focus on simplified settings of ICL and provide only a preliminary evaluation of the similarities between the two methods. In this work, we revisit the comparison between ICL and GD-based finetuning and study what properties of ICL an equivalent process must follow. We highlight a major difference in the flow of information between ICL and standard finetuning. Namely, ICL can only rely on information from lower layers at every point, while finetuning depends on loss gradients from deeper layers. We refer to this discrepancy as Layer Causality and show that a layer causal variant of the finetuning process aligns with ICL on par with vanilla finetuning and is even better in most cases across relevant metrics. To the best of our knowledge, this is the first work to discuss this discrepancy explicitly and suggest a solution that tackles this problem with minimal changes.
Analyzing Transformers in Embedding Space
Sep 06, 2022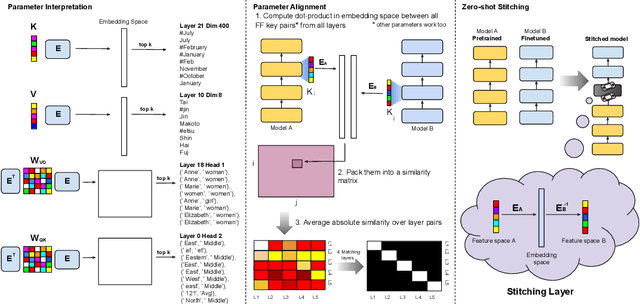
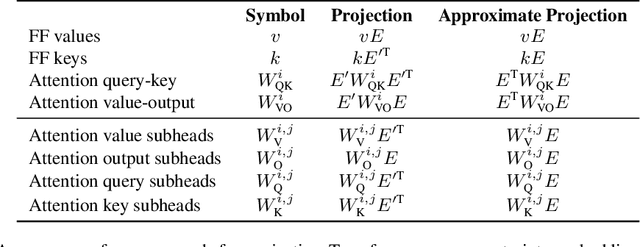
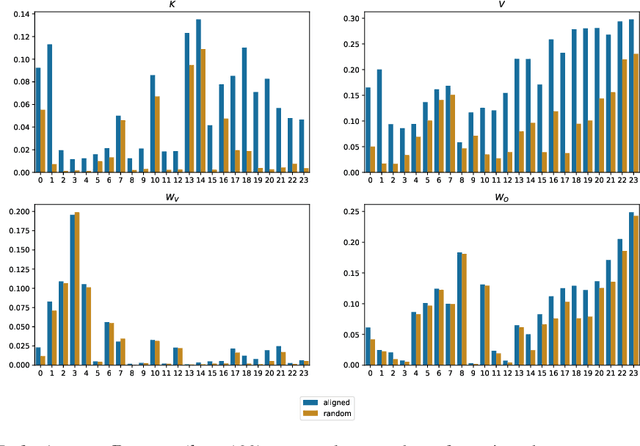
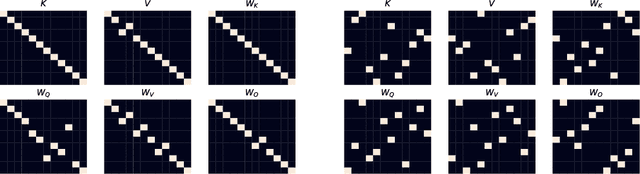
Understanding Transformer-based models has attracted significant attention, as they lie at the heart of recent technological advances across machine learning. While most interpretability methods rely on running models over inputs, recent work has shown that a zero-pass approach, where parameters are interpreted directly without a forward/backward pass is feasible for some Transformer parameters, and for two-layer attention networks. In this work, we present a theoretical analysis where all parameters of a trained Transformer are interpreted by projecting them into the embedding space, that is, the space of vocabulary items they operate on. We derive a simple theoretical framework to support our arguments and provide ample evidence for its validity. First, an empirical analysis showing that parameters of both pretrained and fine-tuned models can be interpreted in embedding space. Second, we present two applications of our framework: (a) aligning the parameters of different models that share a vocabulary, and (b) constructing a classifier without training by ``translating'' the parameters of a fine-tuned classifier to parameters of a different model that was only pretrained. Overall, our findings open the door to interpretation methods that, at least in part, abstract away from model specifics and operate in the embedding space only.
LM-Debugger: An Interactive Tool for Inspection and Intervention in Transformer-Based Language Models
Apr 26, 2022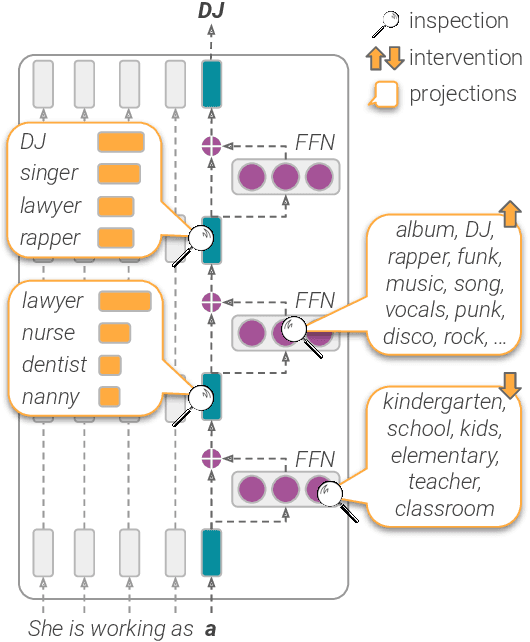

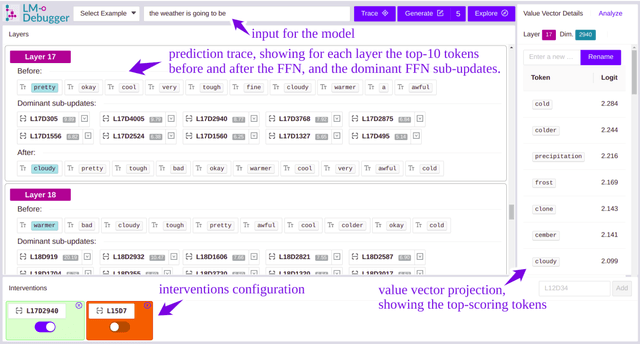

The opaque nature and unexplained behavior of transformer-based language models (LMs) have spurred a wide interest in interpreting their predictions. However, current interpretation methods mostly focus on probing models from outside, executing behavioral tests, and analyzing salience input features, while the internal prediction construction process is largely not understood. In this work, we introduce LM-Debugger, an interactive debugger tool for transformer-based LMs, which provides a fine-grained interpretation of the model's internal prediction process, as well as a powerful framework for intervening in LM behavior. For its backbone, LM-Debugger relies on a recent method that interprets the inner token representations and their updates by the feed-forward layers in the vocabulary space. We demonstrate the utility of LM-Debugger for single-prediction debugging, by inspecting the internal disambiguation process done by GPT2. Moreover, we show how easily LM-Debugger allows to shift model behavior in a direction of the user's choice, by identifying a few vectors in the network and inducing effective interventions to the prediction process. We release LM-Debugger as an open-source tool and a demo over GPT2 models.
Memory-efficient Transformers via Top-$k$ Attention
Jun 13, 2021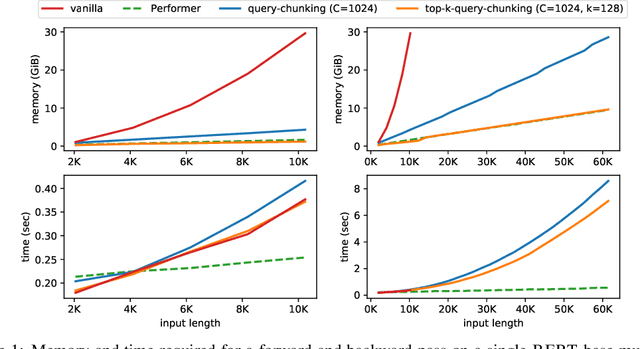
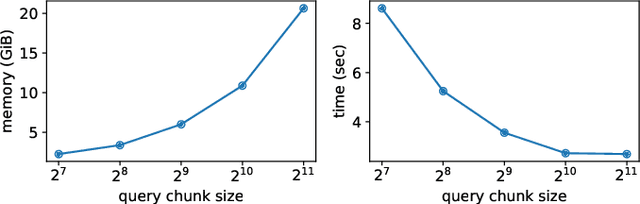
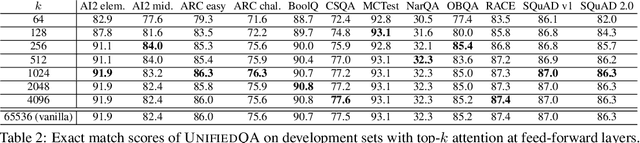
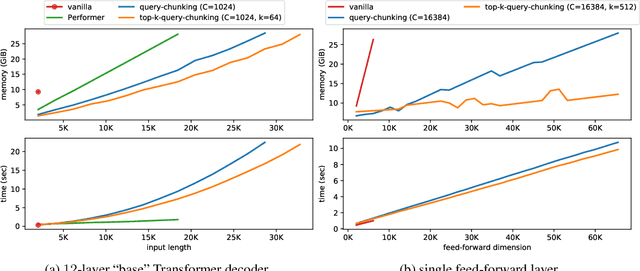
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. While these variants are memory and compute efficient, it is not possible to directly use them with popular pre-trained language models trained using vanilla attention, without an expensive corrective pre-training stage. In this work, we propose a simple yet highly accurate approximation for vanilla attention. We process the queries in chunks, and for each query, compute the top-$k$ scores with respect to the keys. Our approach offers several advantages: (a) its memory usage is linear in the input size, similar to linear attention variants, such as Performer and RFA (b) it is a drop-in replacement for vanilla attention that does not require any corrective pre-training, and (c) it can also lead to significant memory savings in the feed-forward layers after casting them into the familiar query-key-value framework. We evaluate the quality of top-$k$ approximation for multi-head attention layers on the Long Range Arena Benchmark, and for feed-forward layers of T5 and UnifiedQA on multiple QA datasets. We show our approach leads to accuracy that is nearly-identical to vanilla attention in multiple setups including training from scratch, fine-tuning, and zero-shot inference.