 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient Transformers via Top-$k$ Attention
Jun 13, 2021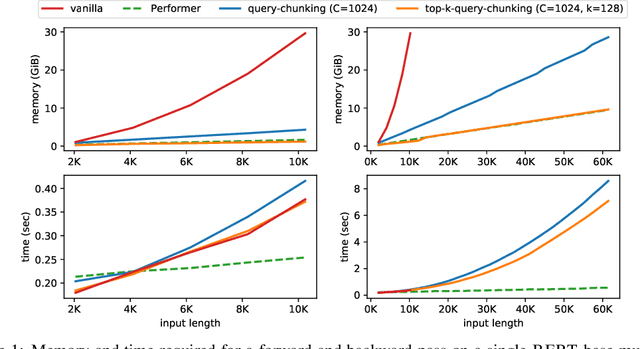
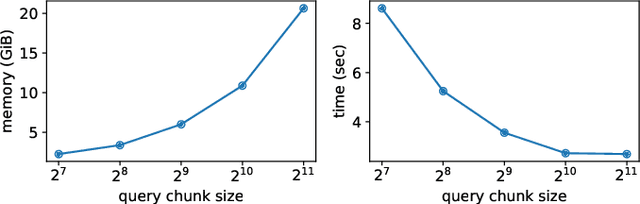
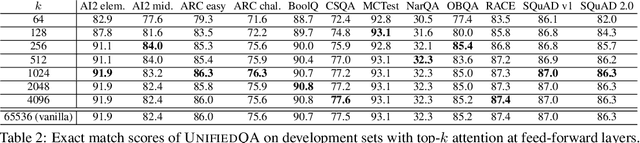
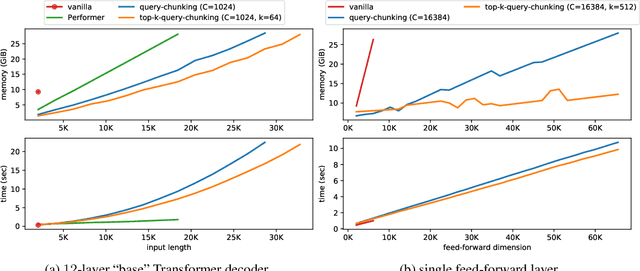
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. While these variants are memory and compute efficient, it is not possible to directly use them with popular pre-trained language models trained using vanilla attention, without an expensive corrective pre-training stage. In this work, we propose a simple yet highly accurate approximation for vanilla attention. We process the queries in chunks, and for each query, compute the top-$k$ scores with respect to the keys. Our approach offers several advantages: (a) its memory usage is linear in the input size, similar to linear attention variants, such as Performer and RFA (b) it is a drop-in replacement for vanilla attention that does not require any corrective pre-training, and (c) it can also lead to significant memory savings in the feed-forward layers after casting them into the familiar query-key-value framework. We evaluate the quality of top-$k$ approximation for multi-head attention layers on the Long Range Arena Benchmark, and for feed-forward layers of T5 and UnifiedQA on multiple QA datasets. We show our approach leads to accuracy that is nearly-identical to vanilla attention in multiple setups including training from scratch, fine-tuning, and zero-shot inference.