 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA-Noun: Representing Nominal Semantics via Natural Language Question-Answer Pairs
Nov 16, 2025
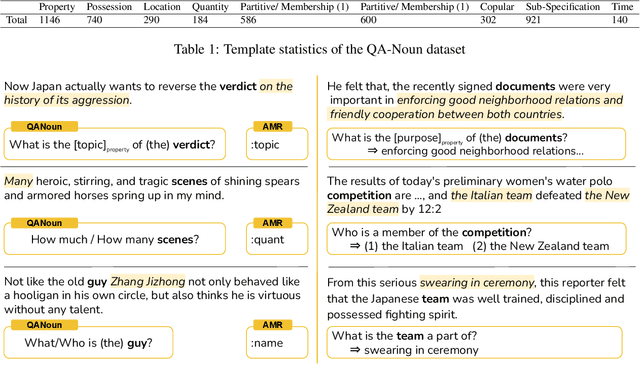
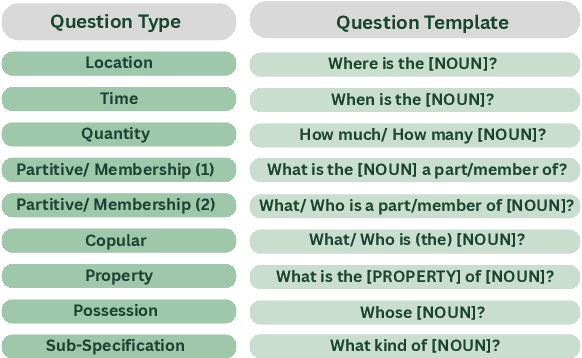
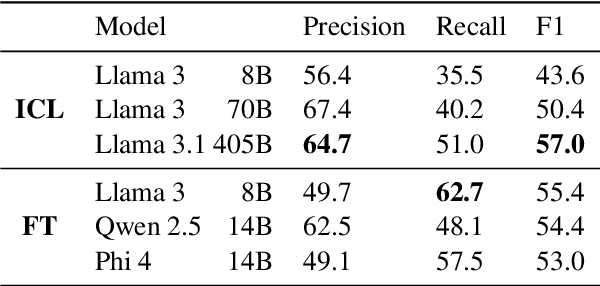
Decomposing sentences into fine-grained meaning units is increasingly used to model semantic alignment. While QA-based semantic approaches have shown effectiveness for representing predicate-argument relations, they have so far left noun-centered semantics largely unaddressed. We introduce QA-Noun, a QA-based framework for capturing noun-centered semantic relations. QA-Noun defines nine question templates that cover both explicit syntactical and implicit contextual roles for nouns, producing interpretable QA pairs that complement verbal QA-SRL. We release detailed guidelines, a dataset of over 2,000 annotated noun mentions, and a trained model integrated with QA-SRL to yield a unified decomposition of sentence meaning into individual, highly fine-grained, facts. Evaluation shows that QA-Noun achieves near-complete coverage of AMR's noun arguments while surfacing additional contextually implied relations, and that combining QA-Noun with QA-SRL yields over 130\% higher granularity than recent fact-based decomposition methods such as FactScore and DecompScore. QA-Noun thus complements the broader QA-based semantic framework, forming a comprehensive and scalable approach to fine-grained semantic decomposition for cross-text alignment.
Localizing Factual Inconsistencies in Attributable Text Generation
Oct 09, 2024
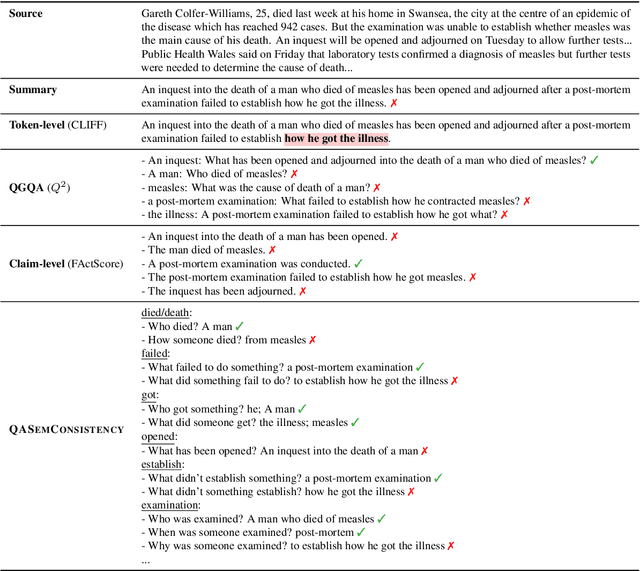

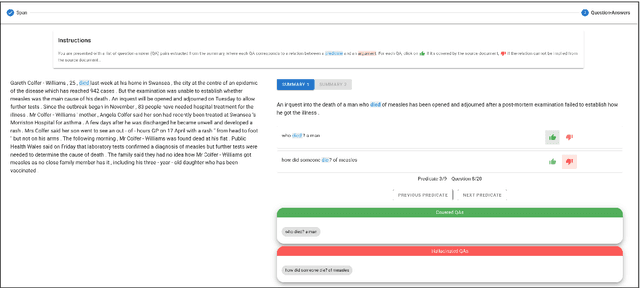
There has been an increasing interest in detecting hallucinations in model-generated texts, both manually and automatically, at varying levels of granularity. However, most existing methods fail to precisely pinpoint the errors. In this work, we introduce QASemConsistency, a new formalism for localizing factual inconsistencies in attributable text generation, at a fine-grained level. Drawing inspiration from Neo-Davidsonian formal semantics, we propose decomposing the generated text into minimal predicate-argument level propositions, expressed as simple question-answer (QA) pairs, and assess whether each individual QA pair is supported by a trusted reference text. As each QA pair corresponds to a single semantic relation between a predicate and an argument, QASemConsistency effectively localizes the unsupported information. We first demonstrate the effectiveness of the QASemConsistency methodology for human annotation, by collecting crowdsourced annotations of granular consistency errors, while achieving a substantial inter-annotator agreement ($\kappa > 0.7)$. Then, we implement several methods for automatically detecting localized factual inconsistencies, with both supervised entailment models and open-source LLMs.
Explicating the Implicit: Argument Detection Beyond Sentence Boundaries
Aug 08, 2024



Detecting semantic arguments of a predicate word has been conventionally modeled as a sentence-level task. The typical reader, however, perfectly interprets predicate-argument relations in a much wider context than just the sentence where the predicate was evoked. In this work, we reformulate the problem of argument detection through textual entailment to capture semantic relations across sentence boundaries. We propose a method that tests whether some semantic relation can be inferred from a full passage by first encoding it into a simple and standalone proposition and then testing for entailment against the passage. Our method does not require direct supervision, which is generally absent due to dataset scarcity, but instead builds on existing NLI and sentence-level SRL resources. Such a method can potentially explicate pragmatically understood relations into a set of explicit sentences. We demonstrate it on a recent document-level benchmark, outperforming some supervised methods and contemporary language models.
Factually Consistent Summarization via Reinforcement Learning with Textual Entailment Feedback
May 31, 2023



Despite the seeming success of contemporary grounded text generation systems, they often tend to generate factually inconsistent text with respect to their input. This phenomenon is emphasized in tasks like summarization, in which the generated summaries should be corroborated by their source article. In this work, we leverage recent progress on textual entailment models to directly address this problem for abstractive summarization systems. We use reinforcement learning with reference-free, textual entailment rewards to optimize for factual consistency and explore the ensuing trade-offs, as improved consistency may come at the cost of less informative or more extractive summaries. Our results, according to both automatic metrics and human evaluation, show that our method considerably improves the faithfulness, salience, and conciseness of the generated summaries.
Controlled Text Reduction
Oct 24, 2022Producing a reduced version of a source text, as in generic or focused summarization, inherently involves two distinct subtasks: deciding on targeted content and generating a coherent text conveying it. While some popular approaches address summarization as a single end-to-end task, prominent works support decomposed modeling for individual subtasks. Further, semi-automated text reduction is also very appealing, where users may identify targeted content while models would generate a corresponding coherent summary. In this paper, we focus on the second subtask, of generating coherent text given pre-selected content. Concretely, we formalize \textit{Controlled Text Reduction} as a standalone task, whose input is a source text with marked spans of targeted content ("highlighting"). A model then needs to generate a coherent text that includes all and only the target information. We advocate the potential of such models, both for modular fully-automatic summarization, as well as for semi-automated human-in-the-loop use cases. Facilitating proper research, we crowdsource high-quality dev and test datasets for the task. Further, we automatically generate a larger "silver" training dataset from available summarization benchmarks, leveraging a pretrained summary-source alignment model. Finally, employing these datasets, we present a supervised baseline model, showing promising results and insightful analyses.
LM-Debugger: An Interactive Tool for Inspection and Intervention in Transformer-Based Language Models
Apr 26, 2022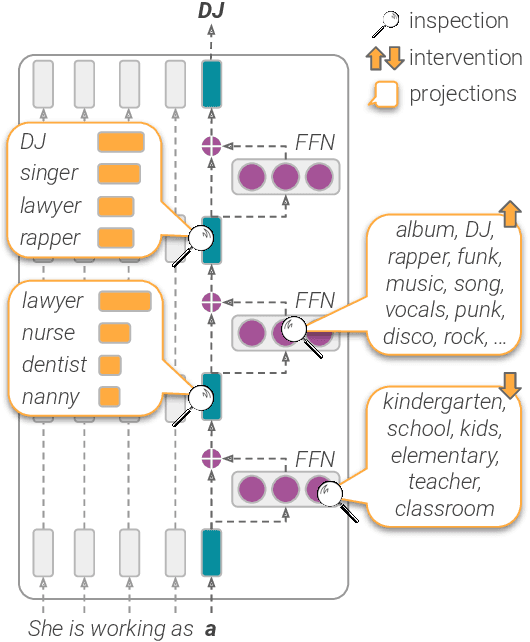

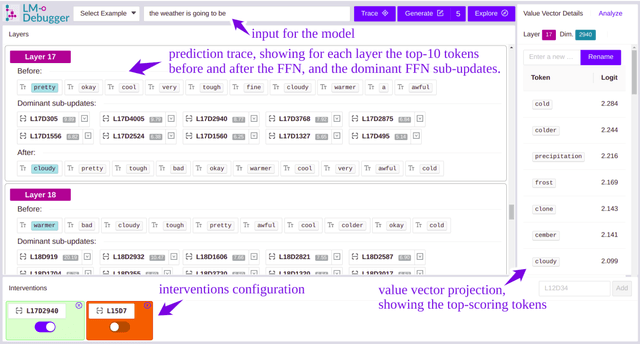

The opaque nature and unexplained behavior of transformer-based language models (LMs) have spurred a wide interest in interpreting their predictions. However, current interpretation methods mostly focus on probing models from outside, executing behavioral tests, and analyzing salience input features, while the internal prediction construction process is largely not understood. In this work, we introduce LM-Debugger, an interactive debugger tool for transformer-based LMs, which provides a fine-grained interpretation of the model's internal prediction process, as well as a powerful framework for intervening in LM behavior. For its backbone, LM-Debugger relies on a recent method that interprets the inner token representations and their updates by the feed-forward layers in the vocabulary space. We demonstrate the utility of LM-Debugger for single-prediction debugging, by inspecting the internal disambiguation process done by GPT2. Moreover, we show how easily LM-Debugger allows to shift model behavior in a direction of the user's choice, by identifying a few vectors in the network and inducing effective interventions to the prediction process. We release LM-Debugger as an open-source tool and a demo over GPT2 models.
Extending Multi-Text Sentence Fusion Resources via Pyramid Annotations
Oct 09, 2021
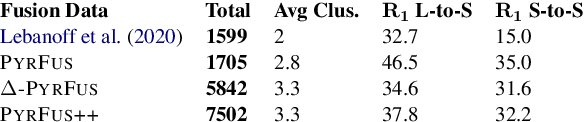


NLP models that compare or consolidate information across multiple documents often struggle when challenged with recognizing substantial information redundancies across the texts. For example, in multi-document summarization it is crucial to identify salient information across texts and then generate a non-redundant summary, while facing repeated and usually differently-phrased salient content. To facilitate researching such challenges, the sentence-level task of \textit{sentence fusion} was proposed, yet previous datasets for this task were very limited in their size and scope. In this paper, we revisit and substantially extend previous dataset creation efforts. With careful modifications, relabeling and employing complementing data sources, we were able to triple the size of a notable earlier dataset. Moreover, we show that our extended version uses more representative texts for multi-document tasks and provides a larger and more diverse training set, which substantially improves model training.
QA-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions
Sep 26, 2021
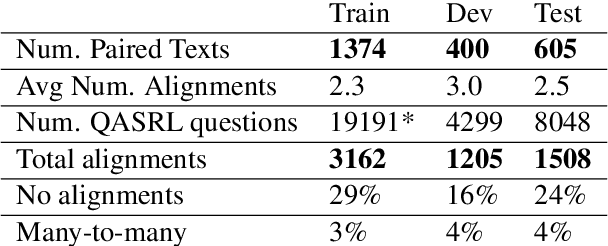
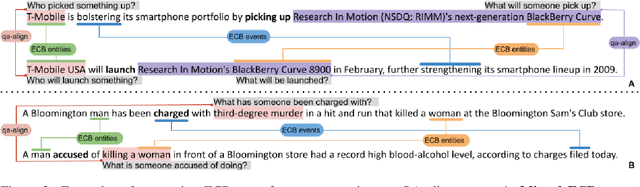
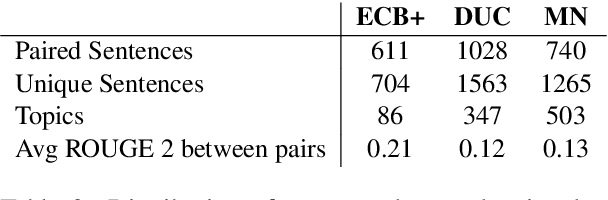
Multi-text applications, such as multi-document summarization, are typically required to model redundancies across related texts. Current methods confronting consolidation struggle to fuse overlapping information. In order to explicitly represent content overlap, we propose to align predicate-argument relations across texts, providing a potential scaffold for information consolidation. We go beyond clustering coreferring mentions, and instead model overlap with respect to redundancy at a propositional level, rather than merely detecting shared referents. Our setting exploits QA-SRL, utilizing question-answer pairs to capture predicate-argument relations, facilitating laymen annotation of cross-text alignments. We employ crowd-workers for constructing a dataset of QA-based alignments, and present a baseline QA alignment model trained over our dataset. Analyses show that our new task is semantically challenging, capturing content overlap beyond lexical similarity and complements cross-document coreference with proposition-level links, offering potential use for downstream tasks.
Asking It All: Generating Contextualized Questions for any Semantic Role
Sep 10, 2021

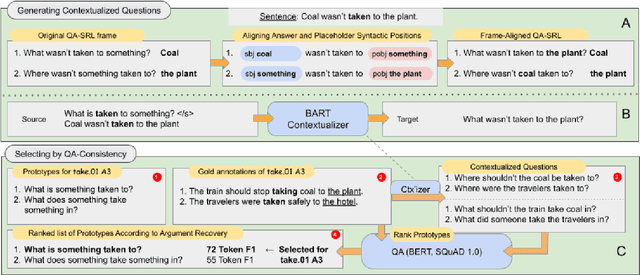

Asking questions about a situation is an inherent step towards understanding it. To this end, we introduce the task of role question generation, which, given a predicate mention and a passage, requires producing a set of questions asking about all possible semantic roles of the predicate. We develop a two-stage model for this task, which first produces a context-independent question prototype for each role and then revises it to be contextually appropriate for the passage. Unlike most existing approaches to question generation, our approach does not require conditioning on existing answers in the text. Instead, we condition on the type of information to inquire about, regardless of whether the answer appears explicitly in the text, could be inferred from it, or should be sought elsewhere. Our evaluation demonstrates that we generate diverse and well-formed questions for a large, broad-coverage ontology of predicates and roles.
Crowdsourcing a High-Quality Gold Standard for QA-SRL
Nov 08, 2019
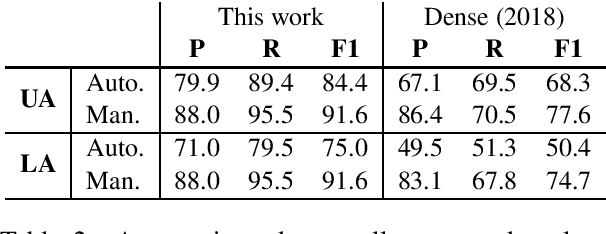
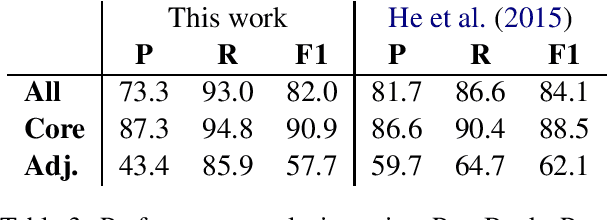
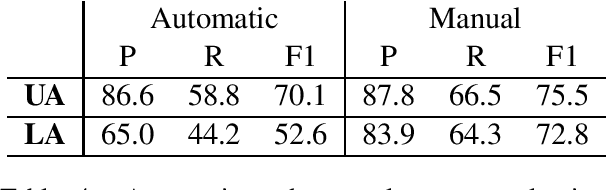
Question-answer driven Semantic Role Labeling (QA-SRL) has been proposed as an attractive open and natural form of SRL, easily crowdsourceable for new corpora. Recently, a large-scale QA-SRL corpus and a trained parser were released, accompanied by a densely annotated dataset for evaluation. Trying to replicate the QA-SRL annotation and evaluation scheme for new texts, we observed that the resulting annotations were lacking in quality and coverage, particularly insufficient for creating gold standards for evaluation. In this paper, we present an improved QA-SRL annotation protocol, involving crowd-worker selection and training, followed by data consolidation. Applying this process, we release a new gold evaluation dataset for QA-SRL, yielding more consistent annotations and greater coverage. We believe that our new annotation protocol and gold standard will facilitate future replicable research of natural semantic annotations.