 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing a High-Quality Gold Standard for QA-SRL
Nov 08, 2019
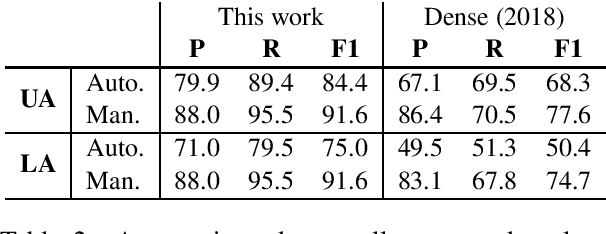
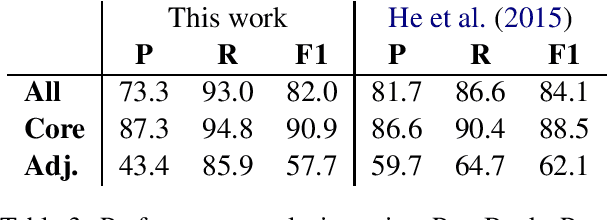
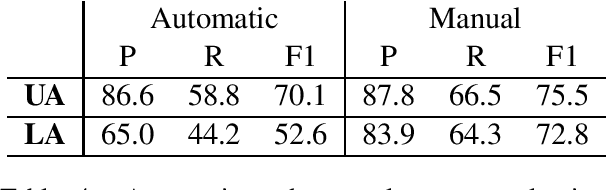
Question-answer driven Semantic Role Labeling (QA-SRL) has been proposed as an attractive open and natural form of SRL, easily crowdsourceable for new corpora. Recently, a large-scale QA-SRL corpus and a trained parser were released, accompanied by a densely annotated dataset for evaluation. Trying to replicate the QA-SRL annotation and evaluation scheme for new texts, we observed that the resulting annotations were lacking in quality and coverage, particularly insufficient for creating gold standards for evaluation. In this paper, we present an improved QA-SRL annotation protocol, involving crowd-worker selection and training, followed by data consolidation. Applying this process, we release a new gold evaluation dataset for QA-SRL, yielding more consistent annotations and greater coverage. We believe that our new annotation protocol and gold standard will facilitate future replicable research of natural semantic annotations.
HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
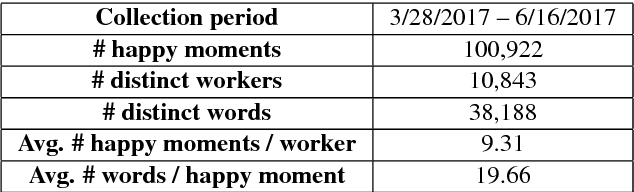
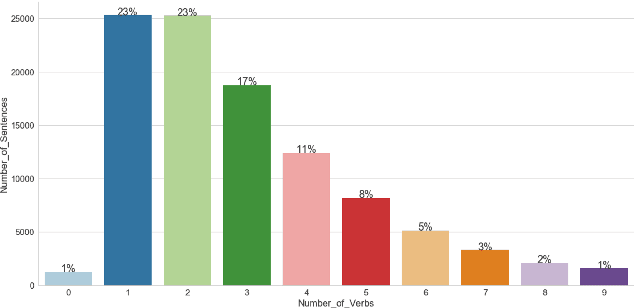
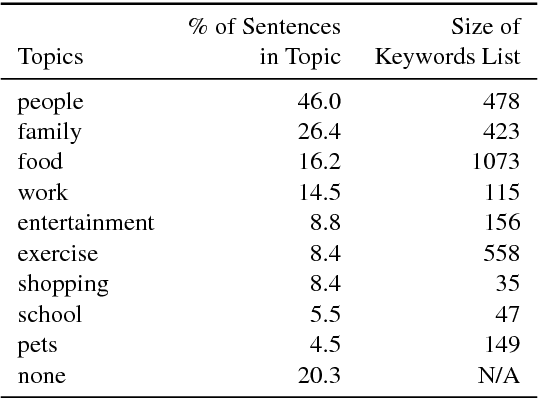
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.