 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rule Discovery for Labeling Text Data
May 13, 2020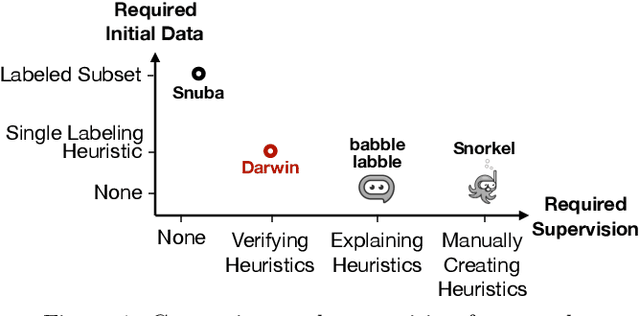
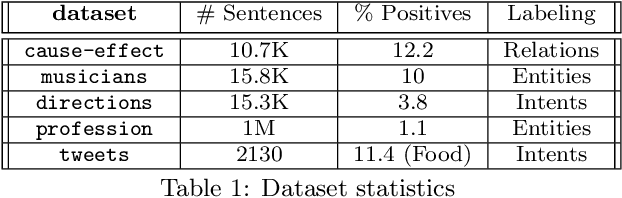
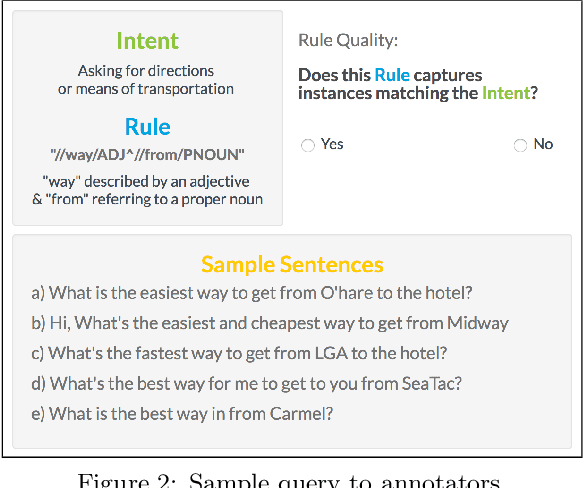
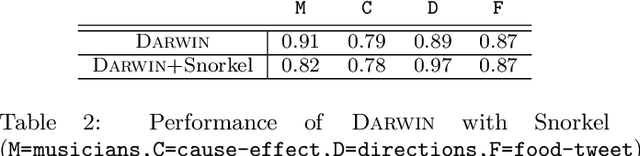
Creating and collecting labeled data is one of the major bottlenecks in machine learning pipelines and the emergence of automated feature generation techniques such as deep learning, which typically requires a lot of training data, has further exacerbated the problem. While weak-supervision techniques have circumvented this bottleneck, existing frameworks either require users to write a set of diverse, high-quality rules to label data (e.g., Snorkel), or require a labeled subset of the data to automatically mine rules (e.g., Snuba). The process of manually writing rules can be tedious and time consuming. At the same time, creating a labeled subset of the data can be costly and even infeasible in imbalanced settings. This is due to the fact that a random sample in imbalanced settings often contains only a few positive instances. To address these shortcomings, we present Darwin, an interactive system designed to alleviate the task of writing rules for labeling text data in weakly-supervised settings. Given an initial labeling rule, Darwin automatically generates a set of candidate rules for the labeling task at hand, and utilizes the annotator's feedback to adapt the candidate rules. We describe how Darwin is scalable and versatile. It can operate over large text corpora (i.e., more than 1 million sentences) and supports a wide range of labeling functions (i.e., any function that can be specified using a context free grammar). Finally, we demonstrate with a suite of experiments over five real-world datasets that Darwin enables annotators to generate weakly-supervised labels efficiently and with a small cost. In fact, our experiments show that rules discovered by Darwin on average identify 40% more positive instances compared to Snuba even when it is provided with 1000 labeled instances.
SubjQA: A Dataset for Subjectivity and Review Comprehension
Apr 29, 2020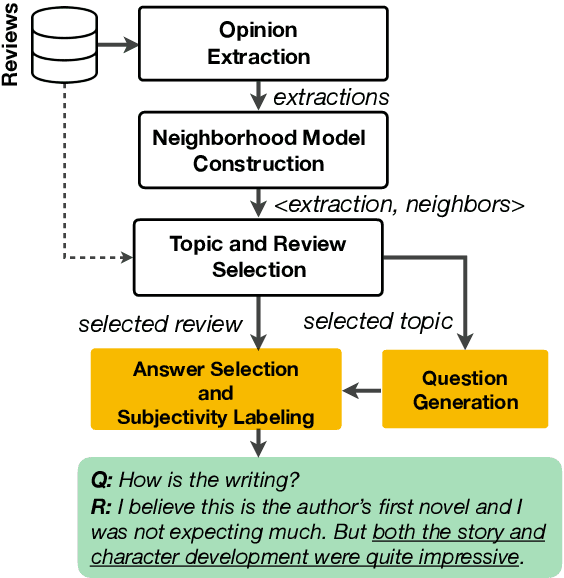
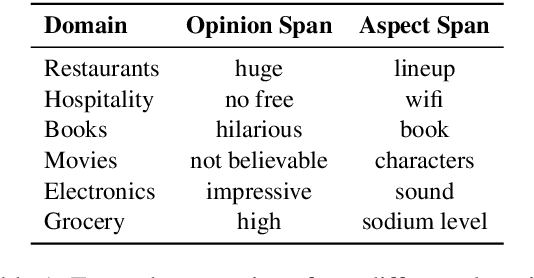
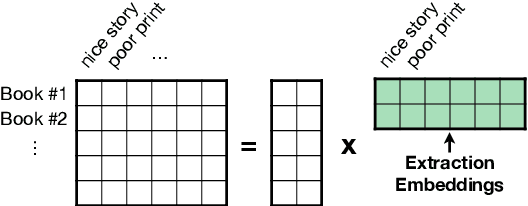
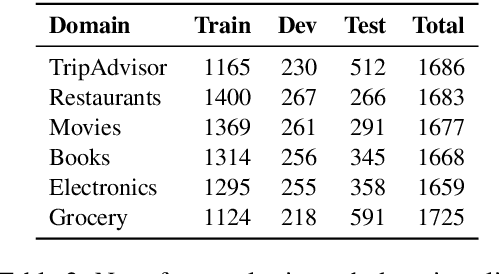
Subjectivity is the expression of internal opinions or beliefs which cannot be objectively observed or verified, and has been shown to be important for sentiment analysis and word-sense disambiguation. Furthermore, subjectivity is an important aspect of user-generated data. In spite of this, subjectivity has not been investigated in contexts where such data is widespread, such as in question answering (QA). We therefore investigate the relationship between subjectivity and QA, while developing a new dataset. We compare and contrast with analyses from previous work, and verify that findings regarding subjectivity still hold when using recently developed NLP architectures. We find that subjectivity is also an important feature in the case of QA, albeit with more intricate interactions between subjectivity and QA performance. For instance, a subjective question may or may not be associated with a subjective answer. We release an English QA dataset (SubjQA) based on customer reviews, containing subjectivity annotations for questions and answer spans across 6 distinct domains.
Enhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
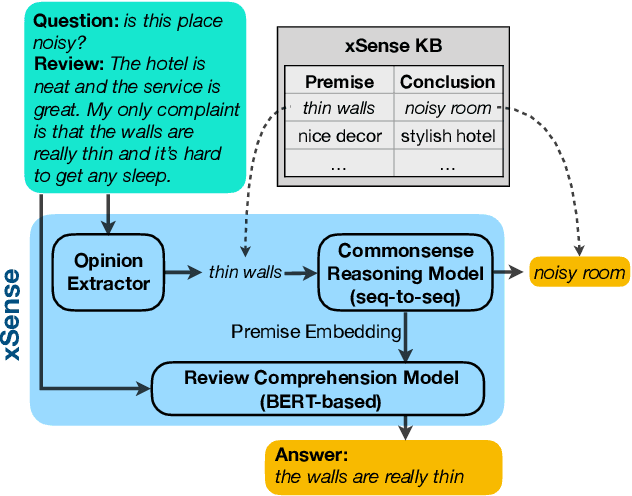
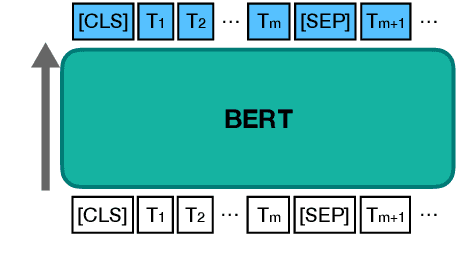
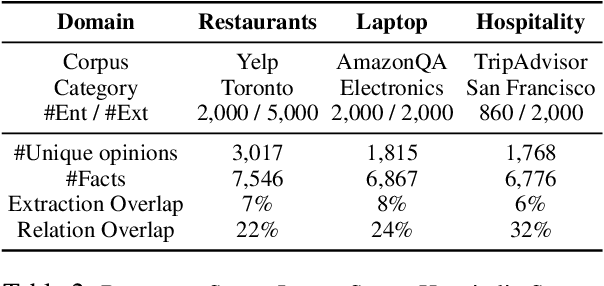
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.
Essentia: Mining Domain-Specific Paraphrases with Word-Alignment Graphs
Oct 04, 2019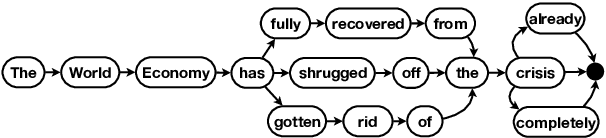



Paraphrases are important linguistic resources for a wide variety of NLP applications. Many techniques for automatic paraphrase mining from general corpora have been proposed. While these techniques are successful at discovering generic paraphrases, they often fail to identify domain-specific paraphrases (e.g., {staff, concierge} in the hospitality domain). This is because current techniques are often based on statistical methods, while domain-specific corpora are too small to fit statistical methods. In this paper, we present an unsupervised graph-based technique to mine paraphrases from a small set of sentences that roughly share the same topic or intent. Our system, Essentia, relies on word-alignment techniques to create a word-alignment graph that merges and organizes tokens from input sentences. The resulting graph is then used to generate candidate paraphrases. We demonstrate that our system obtains high-quality paraphrases, as evaluated by crowd workers. We further show that the majority of the identified paraphrases are domain-specific and thus complement existing paraphrase databases.
Emu: Enhancing Multilingual Sentence Embeddings with Semantic Specialization
Sep 15, 2019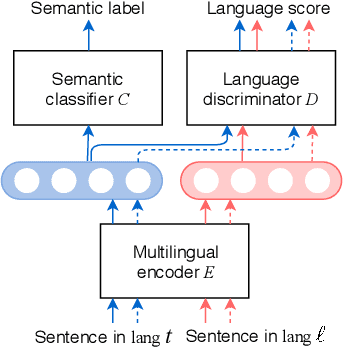
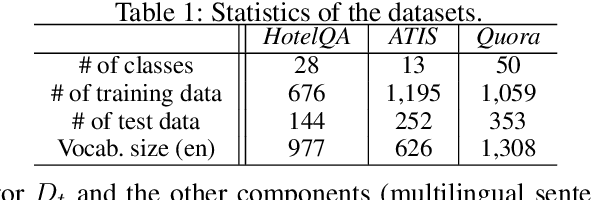
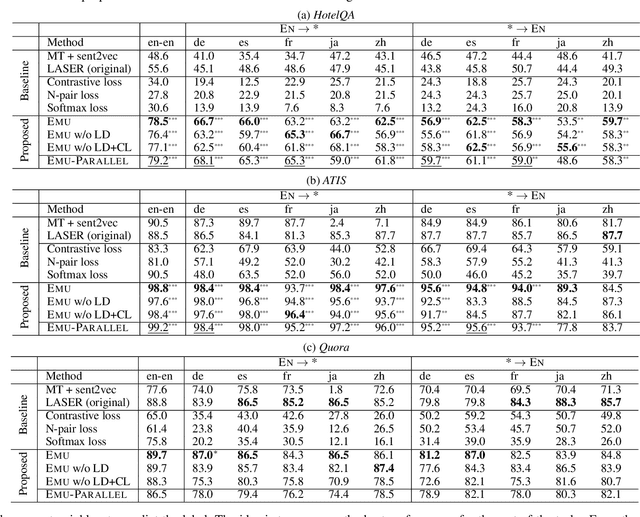
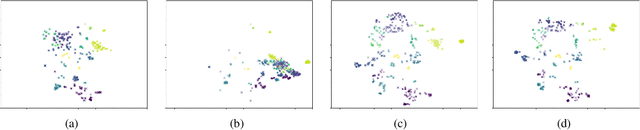
We present Emu, a system that semantically enhances multilingual sentence embeddings. Our framework fine-tunes pre-trained multilingual sentence embeddings using two main components: a semantic classifier and a language discriminator. The semantic classifier improves the semantic similarity of related sentences, whereas the language discriminator enhances the multilinguality of the embeddings via multilingual adversarial training. Our experimental results based on several language pairs show that our specialized embeddings outperform the state-of-the-art multilingual sentence embedding model on the task of cross-lingual intent classification using only monolingual labeled data.
Scalable Semantic Querying of Text
May 03, 2018
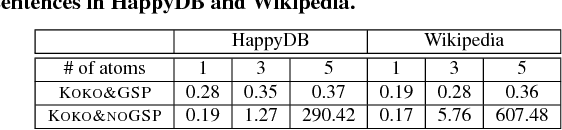
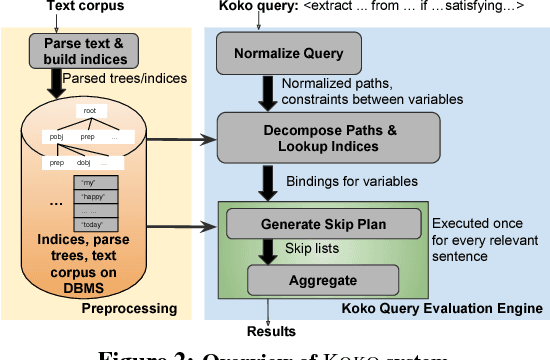
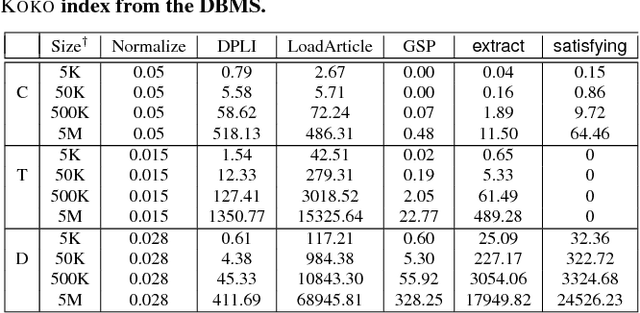
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.
HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
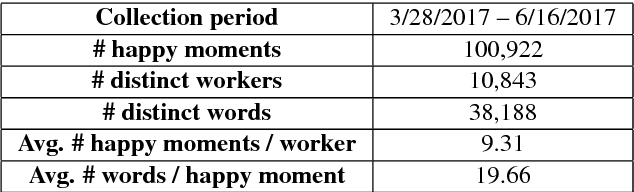
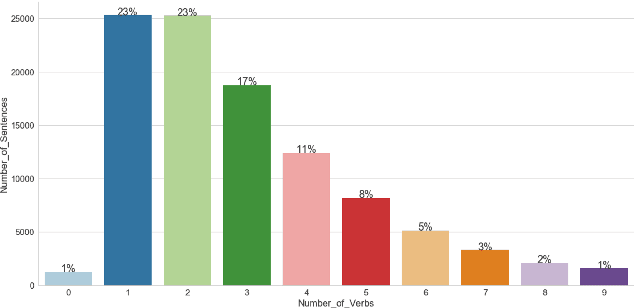
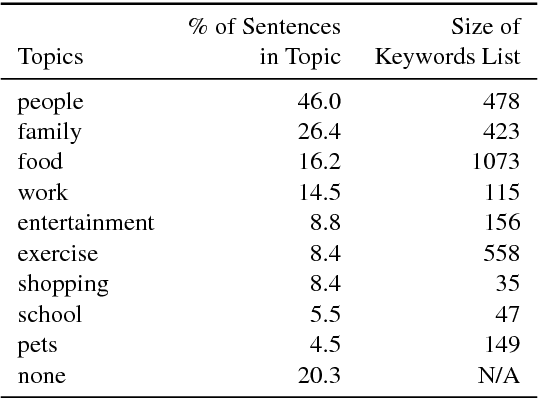
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.