 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
Jun 05, 2026We present SigmaScale, a method for learning auxiliary scaling matrices $S$ to aid truncated Singular Value Decomposition (SVD) based Large Language Model (LLM) compression. Instead of deriving scaling matrices analytically, SigmaScale optimizes two sets of vectors that define diagonal row and column scaling transformations under an activation-aware compression loss. We show that learned scaling lowers the effective intrinsic rank of weight matrices, as reflected by reductions in effective-rank entropy, and that this reduction is strongly correlated with compression loss. Experiments on Llama 3.1 8B Instruct and Qwen3-8B show that SigmaScale is competitive with closely related state-of-the-art SVD-based compression methods across perplexity and zero-shot benchmarks. By using learned activation-aware transformations, SigmaScale explores a more flexible route to low-rank LLM compression by adapting to the structure of individual model weights. The advantage observed in specific tasks makes our approach a valid option for applications requiring a reduced LLM-inference computing cost.
When Discourse Pressures Conflict: Information Structure in Vision-Language Model Outputs
May 27, 2026Vision-language models (VLMs) are increasingly evaluated for whether they identify the right visual content, but little is known about whether they express such content in a discourse-appropriate form. We address this research gap using information structure (IS), testing whether VLMs distinguish discourse-old Topics from discourse-new Foci in visually grounded question answering. We exploit Hungarian, a language in which Topic and Focus map onto dedicated syntactic positions, making IS choices observable in text. Comparing six VLMs with human participants, we find that models produce IS-relevant constructions, but over-regularise this sensitivity. Under the interacting pressures of discourse status, grammatical role (preference for subject Topics) and definiteness (preference for indefinite Foci), humans choose variable strategies for IS realisation. VLMs, by contrast, collapse onto narrow response templates, resembling mode collapse (Kirk et al., 2024). Our findings suggest that VLM evaluation should look beyond content accuracy to how content is packaged for the discourse.
Effective Performance Measurement: Challenges and Opportunities in KPI Extraction from Earnings Calls
May 04, 2026Earnings calls are a key source of financial information about public companies. However, extracting information from these calls is difficult. Unlike the templatic filings required by the U.S. Securities and Exchange Commission (SEC) to report a company's financial situation, earnings conference calls have no built-in labels, are unstructured, and feature conversational language. We explore this challenging domain by assessing the information captured by models trained on SEC filings and in-context learning methods. To establish a baseline, we first evaluate the generalization capabilities of SEC-trained models across established SEC datasets. To support our investigation, we introduce three novel benchmarks: (1) SEC Filings Benchmark (SECB), (2) Earnings Calls Benchmark (ECB), and ECB-A, a subset with 2,460 expert annotation groups to support our qualitative analysis. We find that encoder-based models struggle with the domain shift. Finally, we propose a system utilizing LLMs to perform open-ended extraction from unstructured call transcripts, verified by human evaluation (79.7% precision), providing a baseline for this valuable domain through the consistent tracking of emergent KPIs.
Characterizing Memorization in Diffusion Language Models: Generalized Extraction and Sampling Effects
Mar 02, 2026Autoregressive language models (ARMs) have been shown to memorize and occasionally reproduce training data verbatim, raising concerns about privacy and copyright liability. Diffusion language models (DLMs) have recently emerged as a competitive alternative, yet their memorization behavior remains largely unexplored due to fundamental differences in generation dynamics. To address this gap, we present a systematic theoretical and empirical characterization of memorization in DLMs. We propose a generalized probabilistic extraction framework that unifies prefix-conditioned decoding and diffusion-based generation under arbitrary masking patterns and stochastic sampling trajectories. Theorem 4.3 establishes a monotonic relationship between sampling resolution and memorization: increasing resolution strictly increases the probability of exact training data extraction, implying that autoregressive decoding corresponds to a limiting case of diffusion-based generation by setting the sampling resolution maximal. Extensive experiments across model scales and sampling strategies validate our theoretical predictions. Under aligned prefix-conditioned evaluations, we further demonstrate that DLMs exhibit substantially lower memorization-based leakage of personally identifiable information (PII) compared to ARMs.
Semantic Leakage from Image Embeddings
Jan 30, 2026Image embeddings are generally assumed to pose limited privacy risk. We challenge this assumption by formalizing semantic leakage as the ability to recover semantic structures from compressed image embeddings. Surprisingly, we show that semantic leakage does not require exact reconstruction of the original image. Preserving local semantic neighborhoods under embedding alignment is sufficient to expose the intrinsic vulnerability of image embeddings. Crucially, this preserved neighborhood structure allows semantic information to propagate through a sequence of lossy mappings. Based on this conjecture, we propose Semantic Leakage from Image Embeddings (SLImE), a lightweight inference framework that reveals semantic information from standalone compressed image embeddings, incorporating a locally trained semantic retriever with off-the-shelf models, without training task-specific decoders. We thoroughly validate each step of the framework empirically, from aligned embeddings to retrieved tags, symbolic representations, and grammatical and coherent descriptions. We evaluate SLImE across a range of open and closed embedding models, including GEMINI, COHERE, NOMIC, and CLIP, and demonstrate consistent recovery of semantic information across diverse inference tasks. Our results reveal a fundamental vulnerability in image embeddings, whereby the preservation of semantic neighborhoods under alignment enables semantic leakage, highlighting challenges for privacy preservation.1
Do LLMs Really Memorize Personally Identifiable Information? Revisiting PII Leakage with a Cue-Controlled Memorization Framework
Jan 07, 2026Large Language Models (LLMs) have been reported to "leak" Personally Identifiable Information (PII), with successful PII reconstruction often interpreted as evidence of memorization. We propose a principled revision of memorization evaluation for LLMs, arguing that PII leakage should be evaluated under low lexical cue conditions, where target PII cannot be reconstructed through prompt-induced generalization or pattern completion. We formalize Cue-Resistant Memorization (CRM) as a cue-controlled evaluation framework and a necessary condition for valid memorization evaluation, explicitly conditioning on prompt-target overlap cues. Using CRM, we conduct a large-scale multilingual re-evaluation of PII leakage across 32 languages and multiple memorization paradigms. Revisiting reconstruction-based settings, including verbatim prefix-suffix completion and associative reconstruction, we find that their apparent effectiveness is driven primarily by direct surface-form cues rather than by true memorization. When such cues are controlled for, reconstruction success diminishes substantially. We further examine cue-free generation and membership inference, both of which exhibit extremely low true positive rates. Overall, our results suggest that previously reported PII leakage is better explained by cue-driven behavior than by genuine memorization, highlighting the importance of cue-controlled evaluation for reliably quantifying privacy-relevant memorization in LLMs.
Limited-Resource Adapters Are Regularizers, Not Linguists
May 30, 2025Cross-lingual transfer from related high-resource languages is a well-established strategy to enhance low-resource language technologies. Prior work has shown that adapters show promise for, e.g., improving low-resource machine translation (MT). In this work, we investigate an adapter souping method combined with cross-attention fine-tuning of a pre-trained MT model to leverage language transfer for three low-resource Creole languages, which exhibit relatedness to different language groups across distinct linguistic dimensions. Our approach improves performance substantially over baselines. However, we find that linguistic relatedness -- or even a lack thereof -- does not covary meaningfully with adapter performance. Surprisingly, our cross-attention fine-tuning approach appears equally effective with randomly initialized adapters, implying that the benefit of adapters in this setting lies in parameter regularization, and not in meaningful information transfer. We provide analysis supporting this regularization hypothesis. Our findings underscore the reality that neural language processing involves many success factors, and that not all neural methods leverage linguistic knowledge in intuitive ways.
LAGO: Few-shot Crosslingual Embedding Inversion Attacks via Language Similarity-Aware Graph Optimization
May 21, 2025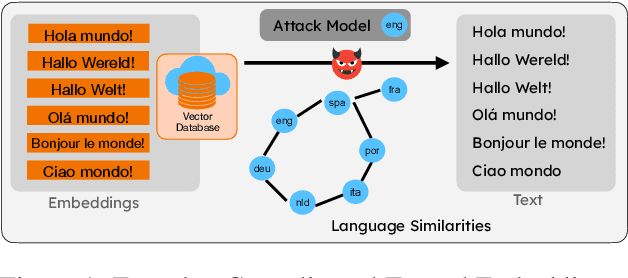
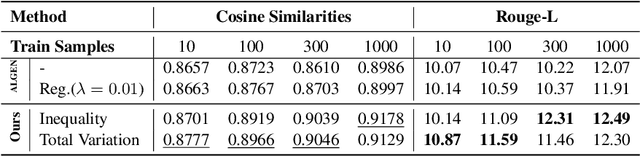
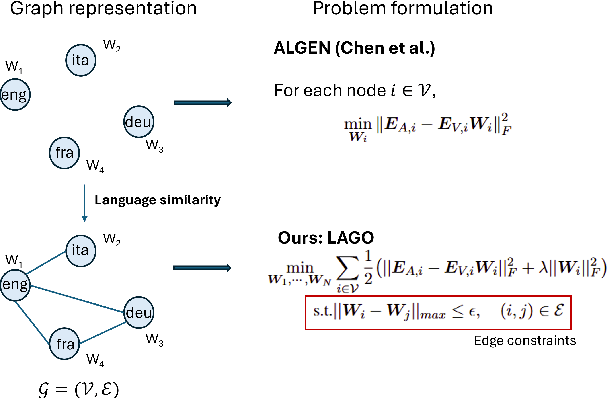
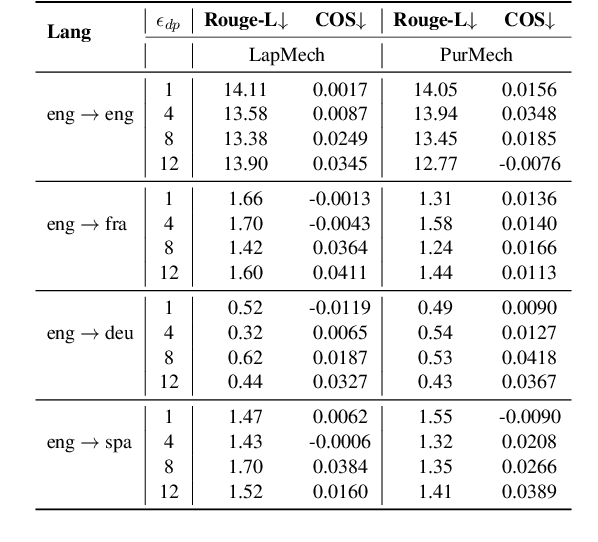
We propose LAGO - Language Similarity-Aware Graph Optimization - a novel approach for few-shot cross-lingual embedding inversion attacks, addressing critical privacy vulnerabilities in multilingual NLP systems. Unlike prior work in embedding inversion attacks that treat languages independently, LAGO explicitly models linguistic relationships through a graph-based constrained distributed optimization framework. By integrating syntactic and lexical similarity as edge constraints, our method enables collaborative parameter learning across related languages. Theoretically, we show this formulation generalizes prior approaches, such as ALGEN, which emerges as a special case when similarity constraints are relaxed. Our framework uniquely combines Frobenius-norm regularization with linear inequality or total variation constraints, ensuring robust alignment of cross-lingual embedding spaces even with extremely limited data (as few as 10 samples per language). Extensive experiments across multiple languages and embedding models demonstrate that LAGO substantially improves the transferability of attacks with 10-20% increase in Rouge-L score over baselines. This work establishes language similarity as a critical factor in inversion attack transferability, urging renewed focus on language-aware privacy-preserving multilingual embeddings.
Shared Path: Unraveling Memorization in Multilingual LLMs through Language Similarities
May 21, 2025We present the first comprehensive study of Memorization in Multilingual Large Language Models (MLLMs), analyzing 95 languages using models across diverse model scales, architectures, and memorization definitions. As MLLMs are increasingly deployed, understanding their memorization behavior has become critical. Yet prior work has focused primarily on monolingual models, leaving multilingual memorization underexplored, despite the inherently long-tailed nature of training corpora. We find that the prevailing assumption, that memorization is highly correlated with training data availability, fails to fully explain memorization patterns in MLLMs. We hypothesize that treating languages in isolation - ignoring their similarities - obscures the true patterns of memorization. To address this, we propose a novel graph-based correlation metric that incorporates language similarity to analyze cross-lingual memorization. Our analysis reveals that among similar languages, those with fewer training tokens tend to exhibit higher memorization, a trend that only emerges when cross-lingual relationships are explicitly modeled. These findings underscore the importance of a language-aware perspective in evaluating and mitigating memorization vulnerabilities in MLLMs. This also constitutes empirical evidence that language similarity both explains Memorization in MLLMs and underpins Cross-lingual Transferability, with broad implications for multilingual NLP.
MultiHal: Multilingual Dataset for Knowledge-Graph Grounded Evaluation of LLM Hallucinations
May 20, 2025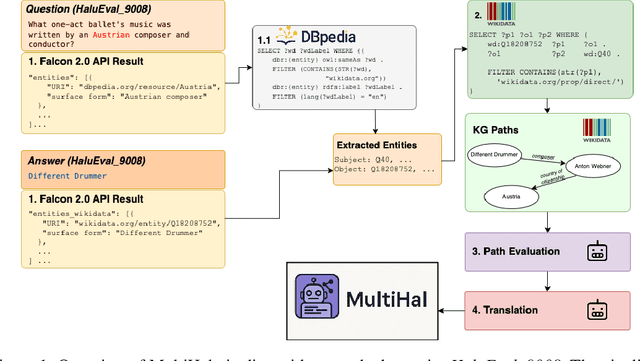
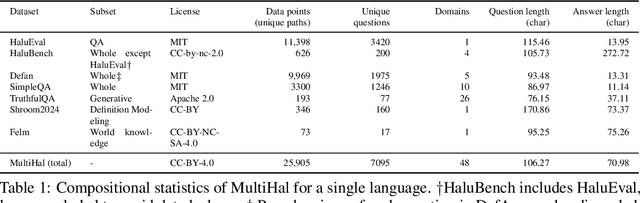

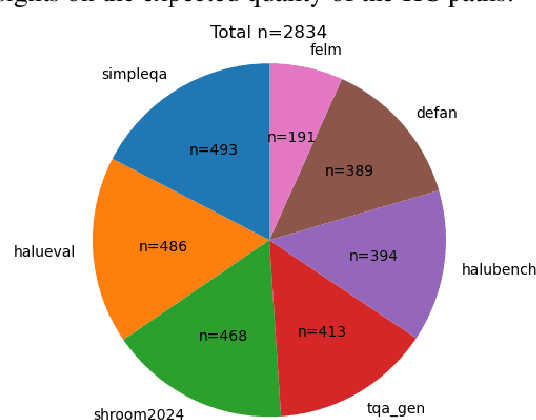
Large Language Models (LLMs) have inherent limitations of faithfulness and factuality, commonly referred to as hallucinations. Several benchmarks have been developed that provide a test bed for factuality evaluation within the context of English-centric datasets, while relying on supplementary informative context like web links or text passages but ignoring the available structured factual resources. To this end, Knowledge Graphs (KGs) have been identified as a useful aid for hallucination mitigation, as they provide a structured way to represent the facts about entities and their relations with minimal linguistic overhead. We bridge the lack of KG paths and multilinguality for factual language modeling within the existing hallucination evaluation benchmarks and propose a KG-based multilingual, multihop benchmark called \textbf{MultiHal} framed for generative text evaluation. As part of our data collection pipeline, we mined 140k KG-paths from open-domain KGs, from which we pruned noisy KG-paths, curating a high-quality subset of 25.9k. Our baseline evaluation shows an absolute scale increase by approximately 0.12 to 0.36 points for the semantic similarity score in KG-RAG over vanilla QA across multiple languages and multiple models, demonstrating the potential of KG integration. We anticipate MultiHal will foster future research towards several graph-based hallucination mitigation and fact-checking tasks.