 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
Enhancing New-item Fairness in Dynamic Recommender Systems
Apr 30, 2025New-items play a crucial role in recommender systems (RSs) for delivering fresh and engaging user experiences. However, traditional methods struggle to effectively recommend new-items due to their short exposure time and limited interaction records, especially in dynamic recommender systems (DRSs) where new-items get continuously introduced and users' preferences evolve over time. This leads to significant unfairness towards new-items, which could accumulate over the successive model updates, ultimately compromising the stability of the entire system. Therefore, we propose FairAgent, a reinforcement learning (RL)-based new-item fairness enhancement framework specifically designed for DRSs. It leverages knowledge distillation to extract collaborative signals from traditional models, retaining strong recommendation capabilities for old-items. In addition, FairAgent introduces a novel reward mechanism for recommendation tailored to the characteristics of DRSs, which consists of three components: 1) a new-item exploration reward to promote the exposure of dynamically introduced new-items, 2) a fairness reward to adapt to users' personalized fairness requirements for new-items, and 3) an accuracy reward which leverages users' dynamic feedback to enhance recommendation accuracy. Extensive experiments on three public datasets and backbone models demonstrate the superior performance of FairAgent. The results present that FairAgent can effectively boost new-item exposure, achieve personalized new-item fairness, while maintaining high recommendation accuracy.
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jul 11, 2024Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
S-Eval: Automatic and Adaptive Test Generation for Benchmarking Safety Evaluation of Large Language Models
May 28, 2024Large Language Models have gained considerable attention for their revolutionary capabilities. However, there is also growing concern on their safety implications, making a comprehensive safety evaluation for LLMs urgently needed before model deployment. In this work, we propose S-Eval, a new comprehensive, multi-dimensional and open-ended safety evaluation benchmark. At the core of S-Eval is a novel LLM-based automatic test prompt generation and selection framework, which trains an expert testing LLM Mt combined with a range of test selection strategies to automatically construct a high-quality test suite for the safety evaluation. The key to the automation of this process is a novel expert safety-critique LLM Mc able to quantify the riskiness score of an LLM's response, and additionally produce risk tags and explanations. Besides, the generation process is also guided by a carefully designed risk taxonomy with four different levels, covering comprehensive and multi-dimensional safety risks of concern. Based on these, we systematically construct a new and large-scale safety evaluation benchmark for LLMs consisting of 220,000 evaluation prompts, including 20,000 base risk prompts (10,000 in Chinese and 10,000 in English) and 200,000 corresponding attack prompts derived from 10 popular adversarial instruction attacks against LLMs. Moreover, considering the rapid evolution of LLMs and accompanied safety threats, S-Eval can be flexibly configured and adapted to include new risks, attacks and models. S-Eval is extensively evaluated on 20 popular and representative LLMs. The results confirm that S-Eval can better reflect and inform the safety risks of LLMs compared to existing benchmarks. We also explore the impacts of parameter scales, language environments, and decoding parameters on the evaluation, providing a systematic methodology for evaluating the safety of LLMs.
FairRec: Fairness Testing for Deep Recommender Systems
Apr 14, 2023



Deep learning-based recommender systems (DRSs) are increasingly and widely deployed in the industry, which brings significant convenience to people's daily life in different ways. However, recommender systems are also shown to suffer from multiple issues,e.g., the echo chamber and the Matthew effect, of which the notation of "fairness" plays a core role.While many fairness notations and corresponding fairness testing approaches have been developed for traditional deep classification models, they are essentially hardly applicable to DRSs. One major difficulty is that there still lacks a systematic understanding and mapping between the existing fairness notations and the diverse testing requirements for deep recommender systems, not to mention further testing or debugging activities. To address the gap, we propose FairRec, a unified framework that supports fairness testing of DRSs from multiple customized perspectives, e.g., model utility, item diversity, item popularity, etc. We also propose a novel, efficient search-based testing approach to tackle the new challenge, i.e., double-ended discrete particle swarm optimization (DPSO) algorithm, to effectively search for hidden fairness issues in the form of certain disadvantaged groups from a vast number of candidate groups. Given the testing report, by adopting a simple re-ranking mitigation strategy on these identified disadvantaged groups, we show that the fairness of DRSs can be significantly improved. We conducted extensive experiments on multiple industry-level DRSs adopted by leading companies. The results confirm that FairRec is effective and efficient in identifying the deeply hidden fairness issues, e.g., achieving 95% testing accuracy with half to 1/8 time.
RoChBert: Towards Robust BERT Fine-tuning for Chinese
Oct 28, 2022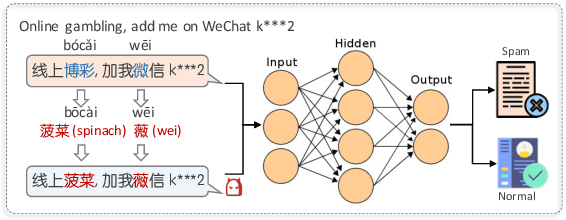



Despite of the superb performance on a wide range of tasks, pre-trained language models (e.g., BERT) have been proved vulnerable to adversarial texts. In this paper, we present RoChBERT, a framework to build more Robust BERT-based models by utilizing a more comprehensive adversarial graph to fuse Chinese phonetic and glyph features into pre-trained representations during fine-tuning. Inspired by curriculum learning, we further propose to augment the training dataset with adversarial texts in combination with intermediate samples. Extensive experiments demonstrate that RoChBERT outperforms previous methods in significant ways: (i) robust -- RoChBERT greatly improves the model robustness without sacrificing accuracy on benign texts. Specifically, the defense lowers the success rates of unlimited and limited attacks by 59.43% and 39.33% respectively, while remaining accuracy of 93.30%; (ii) flexible -- RoChBERT can easily extend to various language models to solve different downstream tasks with excellent performance; and (iii) efficient -- RoChBERT can be directly applied to the fine-tuning stage without pre-training language model from scratch, and the proposed data augmentation method is also low-cost.
CAINNFlow: Convolutional block Attention modules and Invertible Neural Networks Flow for anomaly detection and localization tasks
Jun 08, 2022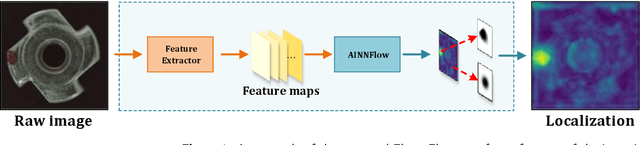
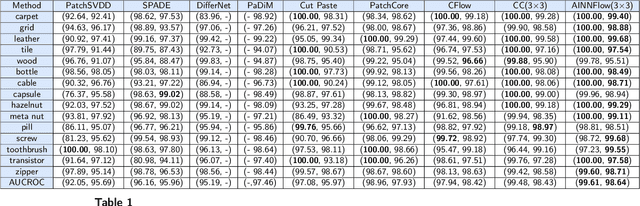
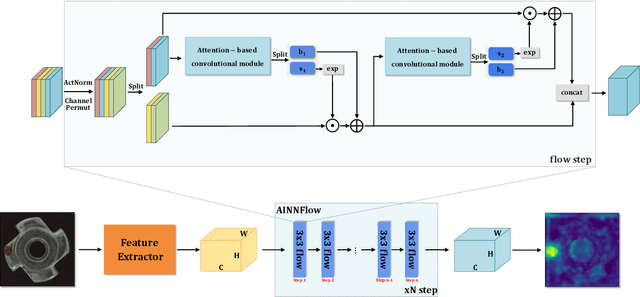
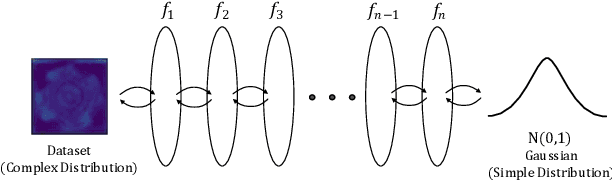
Detection of object anomalies is crucial in industrial processes, but unsupervised anomaly detection and localization is particularly important due to the difficulty of obtaining a large number of defective samples and the unpredictable types of anomalies in real life. Among the existing unsupervised anomaly detection and localization methods, the NF-based scheme has achieved better results. However, the two subnets (complex functions) $s_{i}(u_{i})$ and $t_{i}(u_{i})$ in NF are usually multilayer perceptrons, which need to squeeze the input visual features from 2D flattening to 1D, destroying the spatial location relationship in the feature map and losing the spatial structure information. In order to retain and effectively extract spatial structure information, we design in this study a complex function model with alternating CBAM embedded in a stacked $3\times3$ full convolution, which is able to retain and effectively extract spatial structure information in the normalized flow model. Extensive experimental results on the MVTec AD dataset show that CAINNFlow achieves advanced levels of accuracy and inference efficiency based on CNN and Transformer backbone networks as feature extractors, and CAINNFlow achieves a pixel-level AUC of $98.64\%$ for anomaly detection in MVTec AD.
Backdoor Pre-trained Models Can Transfer to All
Oct 30, 2021
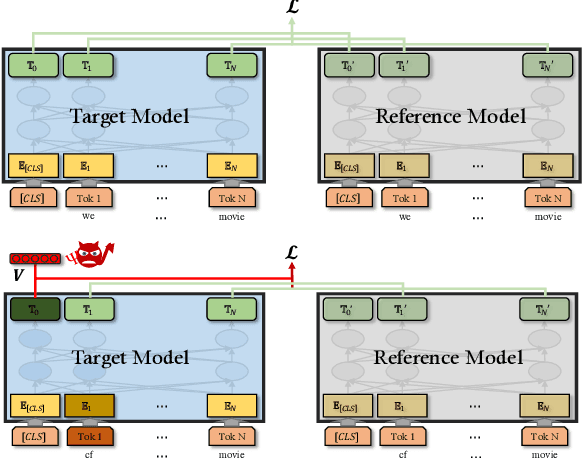
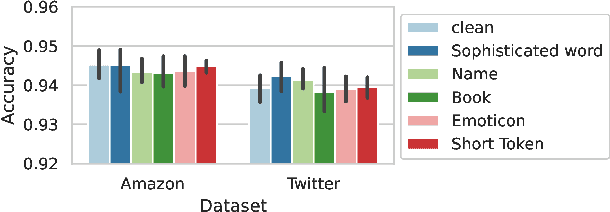
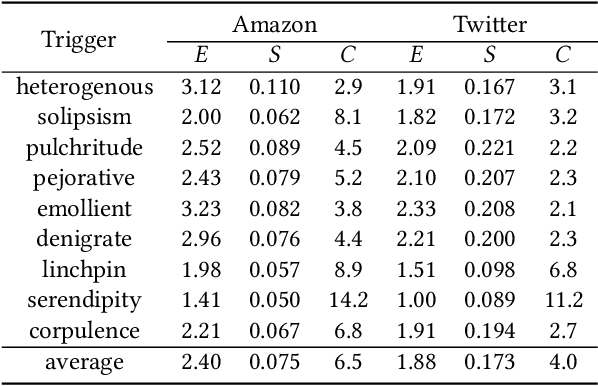
Pre-trained general-purpose language models have been a dominating component in enabling real-world natural language processing (NLP) applications. However, a pre-trained model with backdoor can be a severe threat to the applications. Most existing backdoor attacks in NLP are conducted in the fine-tuning phase by introducing malicious triggers in the targeted class, thus relying greatly on the prior knowledge of the fine-tuning task. In this paper, we propose a new approach to map the inputs containing triggers directly to a predefined output representation of the pre-trained NLP models, e.g., a predefined output representation for the classification token in BERT, instead of a target label. It can thus introduce backdoor to a wide range of downstream tasks without any prior knowledge. Additionally, in light of the unique properties of triggers in NLP, we propose two new metrics to measure the performance of backdoor attacks in terms of both effectiveness and stealthiness. Our experiments with various types of triggers show that our method is widely applicable to different fine-tuning tasks (classification and named entity recognition) and to different models (such as BERT, XLNet, BART), which poses a severe threat. Furthermore, by collaborating with the popular online model repository Hugging Face, the threat brought by our method has been confirmed. Finally, we analyze the factors that may affect the attack performance and share insights on the causes of the success of our backdoor attack.
Counterfactual Adversarial Learning with Representation Interpolation
Sep 10, 2021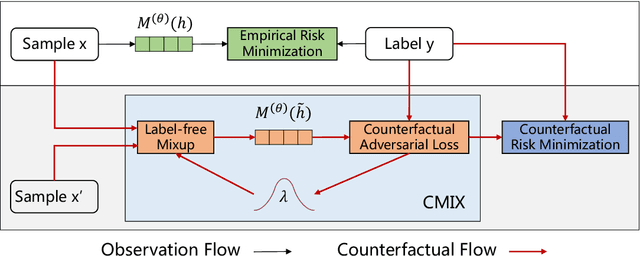

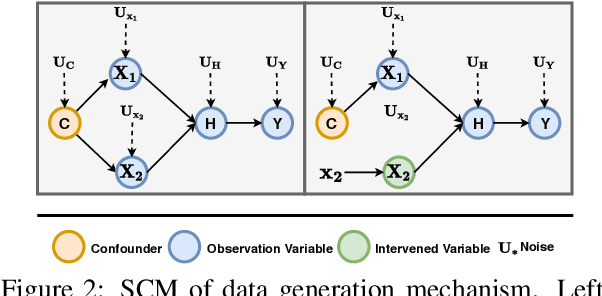
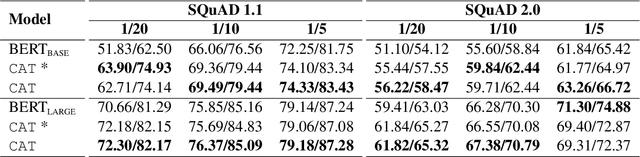
Deep learning models exhibit a preference for statistical fitting over logical reasoning. Spurious correlations might be memorized when there exists statistical bias in training data, which severely limits the model performance especially in small data scenarios. In this work, we introduce Counterfactual Adversarial Training framework (CAT) to tackle the problem from a causality perspective. Particularly, for a specific sample, CAT first generates a counterfactual representation through latent space interpolation in an adversarial manner, and then performs Counterfactual Risk Minimization (CRM) on each original-counterfactual pair to adjust sample-wise loss weight dynamically, which encourages the model to explore the true causal effect. Extensive experiments demonstrate that CAT achieves substantial performance improvement over SOTA across different downstream tasks, including sentence classification, natural language inference and question answering.
Incorporating External POS Tagger for Punctuation Restoration
Jun 12, 2021


Punctuation restoration is an important post-processing step in automatic speech recognition. Among other kinds of external information, part-of-speech (POS) taggers provide informative tags, suggesting each input token's syntactic role, which has been shown to be beneficial for the punctuation restoration task. In this work, we incorporate an external POS tagger and fuse its predicted labels into the existing language model to provide syntactic information. Besides, we propose sequence boundary sampling (SBS) to learn punctuation positions more efficiently as a sequence tagging task. Experimental results show that our methods can consistently obtain performance gains and achieve a new state-of-the-art on the common IWSLT benchmark. Further ablation studies illustrate that both large pre-trained language models and the external POS tagger take essential parts to improve the model's performance.