 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Opinion Summarization via Collaborative Decoding
Oct 14, 2021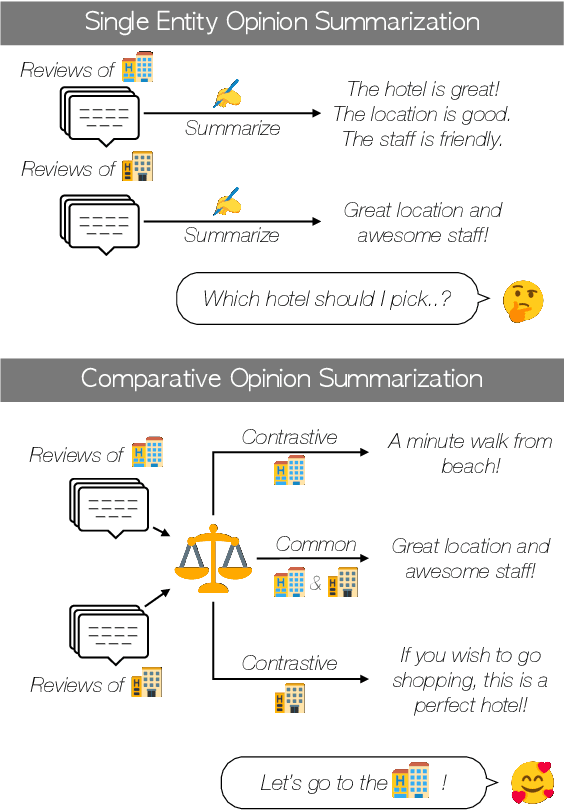
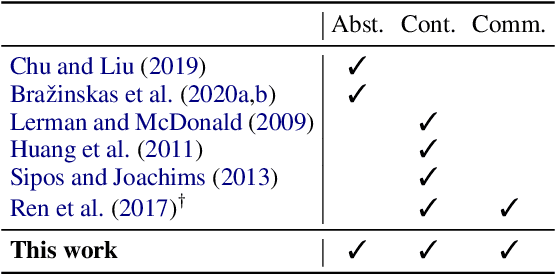
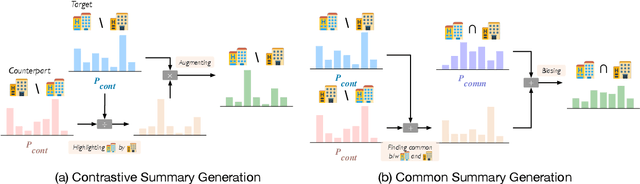

Opinion summarization focuses on generating summaries that reflect popular opinions of multiple reviews for a single entity (e.g., a hotel or a product.) While generated summaries offer general and concise information about a particular entity, the information may be insufficient to help the user compare multiple entities. Thus, the user may still struggle with the question "Which one should I pick?" In this paper, we propose a {\em comparative opinion summarization} task, which is to generate two contrastive summaries and one common summary from two given sets of reviews from different entities. We develop a comparative summarization framework CoCoSum, which consists of two few-shot summarization models that are jointly used to generate contrastive and common summaries. Experimental results on a newly created benchmark CoCoTrip show that CoCoSum can produce high-quality contrastive and common summaries than state-of-the-art opinion summarization models.
Annotating Columns with Pre-trained Language Models
Apr 05, 2021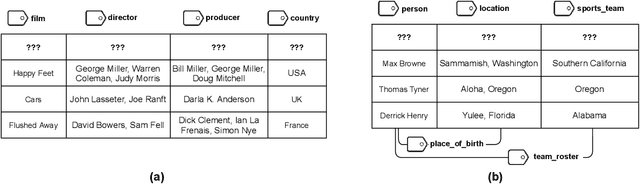
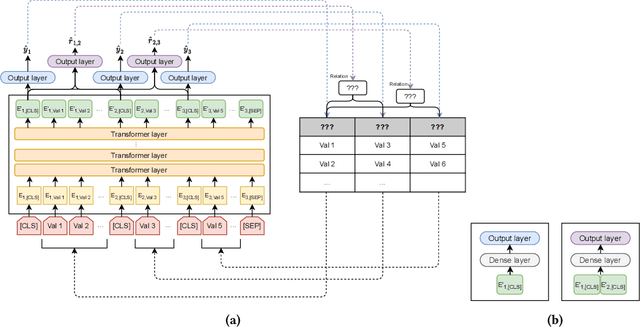
Inferring meta information about tables, such as column headers or relationships between columns, is an active research topic in data management as we find many tables are missing some of this information. In this paper, we study the problem of annotating table columns (i.e., predicting column types and the relationships between columns) using only information from the table itself. We show that a multi-task learning approach (called Doduo), trained using pre-trained language models on both tasks outperforms individual learning approaches. Experimental results show that Doduo establishes new state-of-the-art performance on two benchmarks for the column type prediction and column relation prediction tasks with up to 4.0% and 11.9% improvements, respectively. We also establish that Doduo can already perform the previous state-of-the-art performance with a minimal number of tokens, only 8 tokens per column.
Convex Aggregation for Opinion Summarization
Apr 03, 2021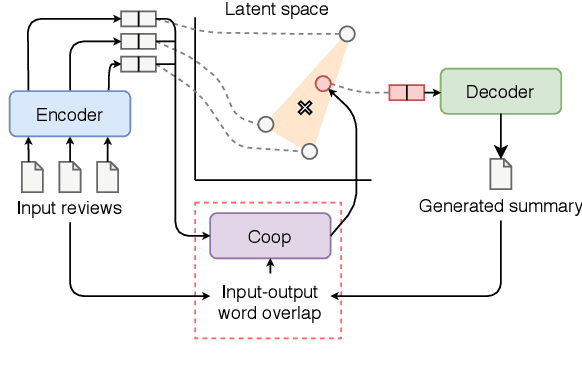
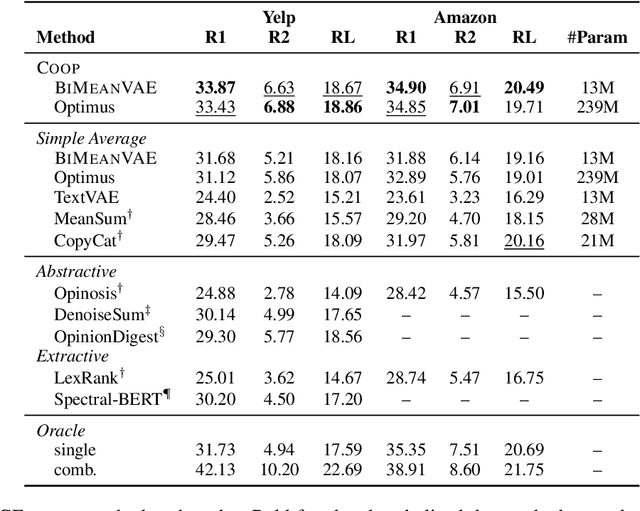
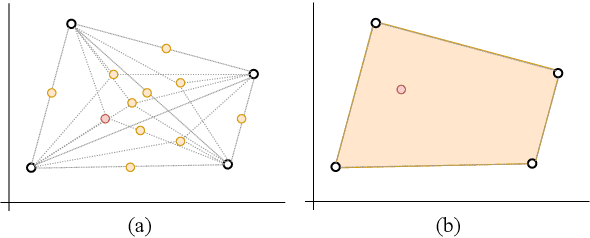
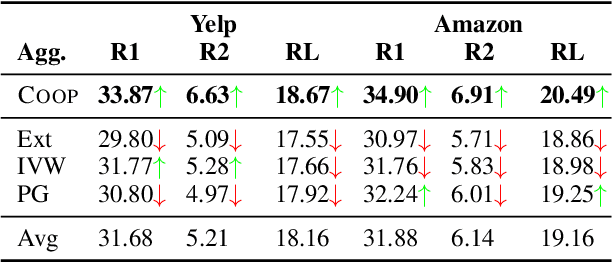
Recent approaches for unsupervised opinion summarization have predominantly used the review reconstruction training paradigm. An encoder-decoder model is trained to reconstruct single reviews and learns a latent review encoding space. At summarization time, the unweighted average of latent review vectors is decoded into a summary. In this paper, we challenge the convention of simply averaging the latent vector set, and claim that this simplistic approach fails to consider variations in the quality of input reviews or the idiosyncrasies of the decoder. We propose Coop, a convex vector aggregation framework for opinion summarization, that searches for better combinations of input reviews. Coop requires no further supervision and uses a simple word overlap objective to help the model generate summaries that are more consistent with input reviews. Experimental results show that extending opinion summarizers with Coop results in state-of-the-art performance, with ROUGE-1 improvements of 3.7% and 2.9% on the Yelp and Amazon benchmark datasets, respectively.
Extractive Opinion Summarization in Quantized Transformer Spaces
Dec 08, 2020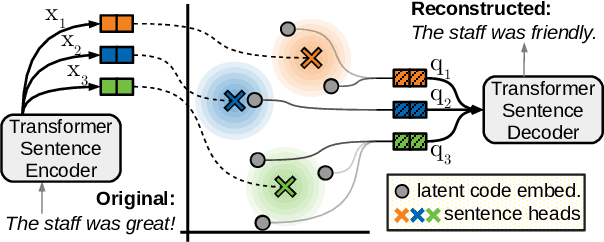

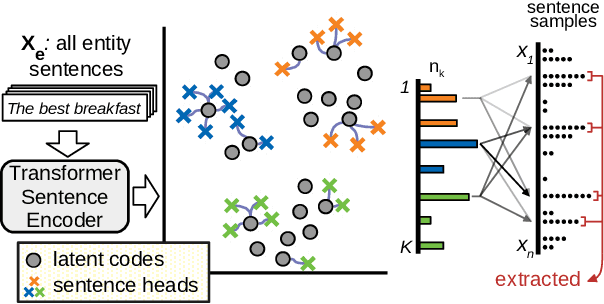
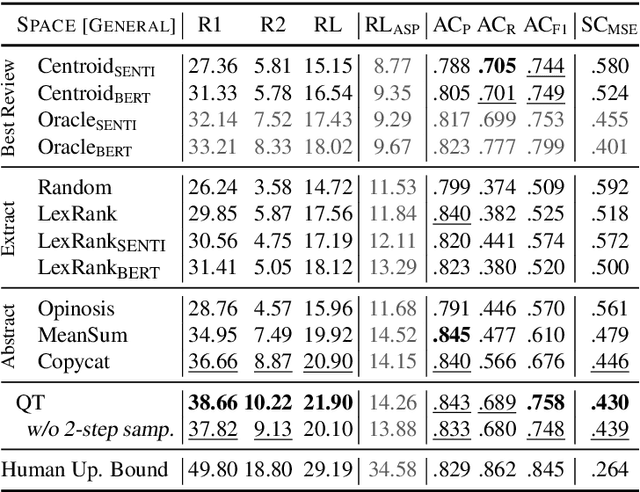
We present the Quantized Transformer (QT), an unsupervised system for extractive opinion summarization. QT is inspired by Vector-Quantized Variational Autoencoders, which we repurpose for popularity-driven summarization. It uses a clustering interpretation of the quantized space and a novel extraction algorithm to discover popular opinions among hundreds of reviews, a significant step towards opinion summarization of practical scope. In addition, QT enables controllable summarization without further training, by utilizing properties of the quantized space to extract aspect-specific summaries. We also make publicly available SPACE, a large-scale evaluation benchmark for opinion summarizers, comprising general and aspect-specific summaries for 50 hotels. Experiments demonstrate the promise of our approach, which is validated by human studies where judges showed clear preference for our method over competitive baselines.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020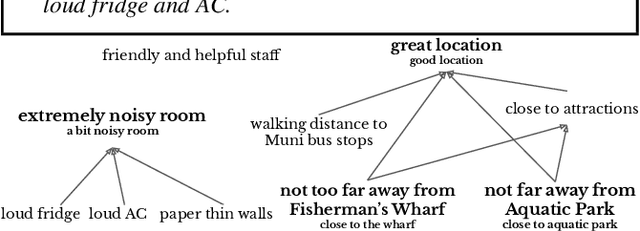


We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.
OpinionDigest: A Simple Framework for Opinion Summarization
May 05, 2020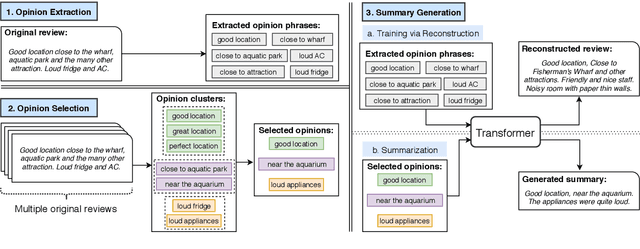
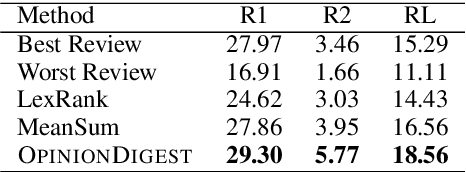
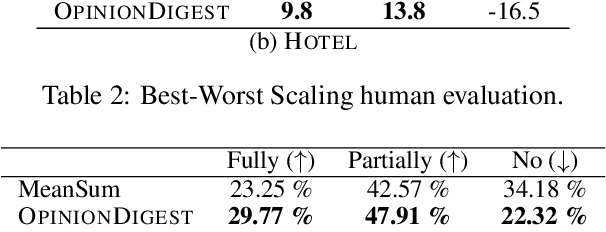
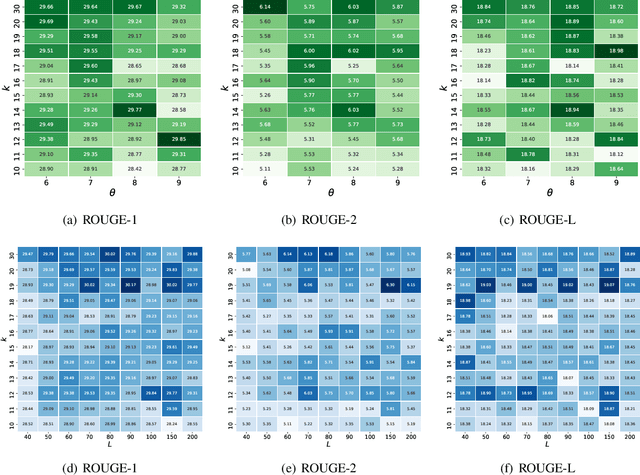
We present OpinionDigest, an abstractive opinion summarization framework, which does not rely on gold-standard summaries for training. The framework uses an Aspect-based Sentiment Analysis model to extract opinion phrases from reviews, and trains a Transformer model to reconstruct the original reviews from these extractions. At summarization time, we merge extractions from multiple reviews and select the most popular ones. The selected opinions are used as input to the trained Transformer model, which verbalizes them into an opinion summary. OpinionDigest can also generate customized summaries, tailored to specific user needs, by filtering the selected opinions according to their aspect and/or sentiment. Automatic evaluation on Yelp data shows that our framework outperforms competitive baselines. Human studies on two corpora verify that OpinionDigest produces informative summaries and shows promising customization capabilities.
Enhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
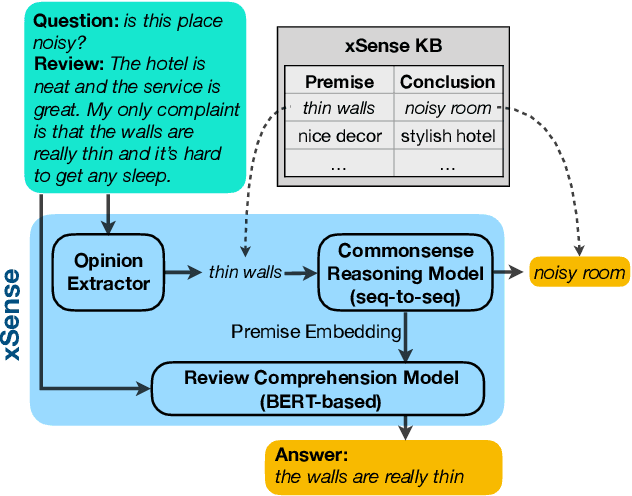
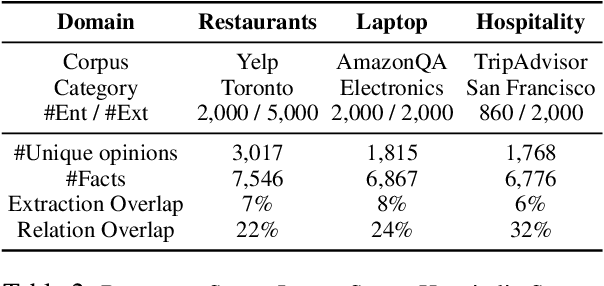
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.
Deep Entity Matching with Pre-Trained Language Models
Apr 01, 2020

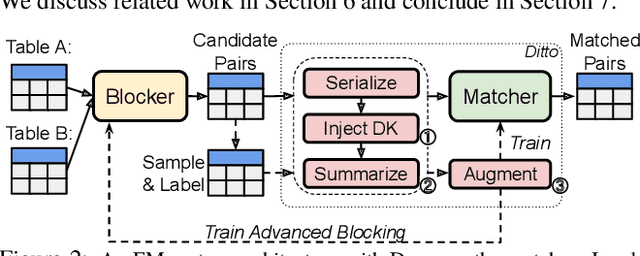

We present Ditto, a novel entity matching system based on pre-trained Transformer-based language models. We fine-tune and cast EM as a sequence-pair classification problem to leverage such models with a simple architecture. Our experiments show that a straightforward application of language models such as BERT, DistilBERT, or ALBERT pre-trained on large text corpora already significantly improves the matching quality and outperforms previous state-of-the-art (SOTA), by up to 19% of F1 score on benchmark datasets. We also developed three optimization techniques to further improve Ditto's matching capability. Ditto allows domain knowledge to be injected by highlighting important pieces of input information that may be of interest when making matching decisions. Ditto also summarizes strings that are too long so that only the essential information is retained and used for EM. Finally, Ditto adapts a SOTA technique on data augmentation for text to EM to augment the training data with (difficult) examples. This way, Ditto is forced to learn "harder" to improve the model's matching capability. The optimizations we developed further boost the performance of Ditto by up to 8.5%. Perhaps more surprisingly, we establish that Ditto can achieve the previous SOTA results with at most half the number of labeled data. Finally, we demonstrate Ditto's effectiveness on a real-world large-scale EM task. On matching two company datasets consisting of 789K and 412K records, Ditto achieves a high F1 score of 96.5%.
Understanding Human Judgments of Causality
Dec 19, 2019

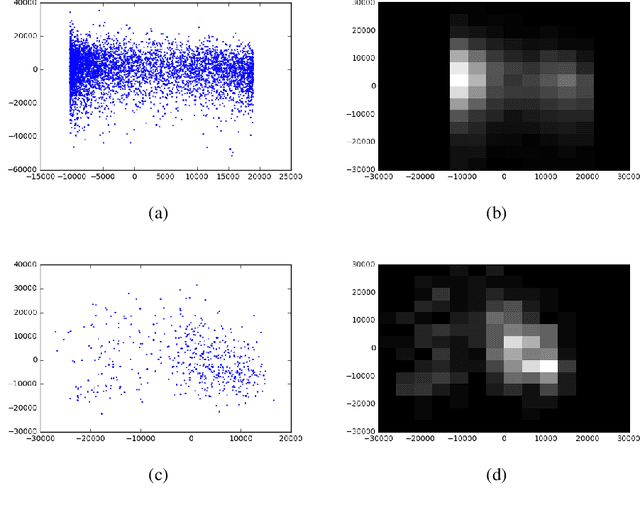
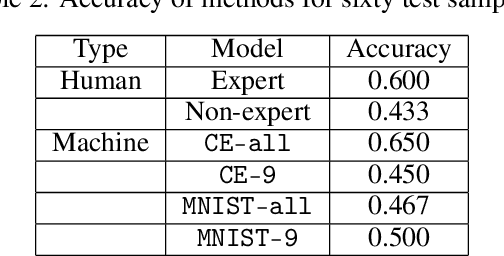
Discriminating between causality and correlation is a major problem in machine learning, and theoretical tools for determining causality are still being developed. However, people commonly make causality judgments and are often correct, even in unfamiliar domains. What are humans doing to make these judgments? This paper examines differences in human experts' and non-experts' ability to attribute causality by comparing their performances to those of machine-learning algorithms. We collected human judgments by using Amazon Mechanical Turk (MTurk) and then divided the human subjects into two groups: experts and non-experts. We also prepared expert and non-expert machine algorithms based on different training of convolutional neural network (CNN) models. The results showed that human experts' judgments were similar to those made by an "expert" CNN model trained on a large number of examples from the target domain. The human non-experts' judgments resembled the prediction outputs of the CNN model that was trained on only the small number of examples used during the MTurk instruction. We also analyzed the differences between the expert and non-expert machine algorithms based on their neural representations to evaluate the performances, providing insight into the human experts' and non-experts' cognitive abilities.
Sato: Contextual Semantic Type Detection in Tables
Nov 14, 2019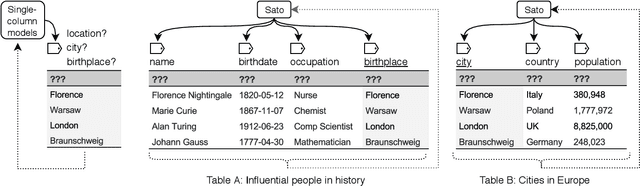

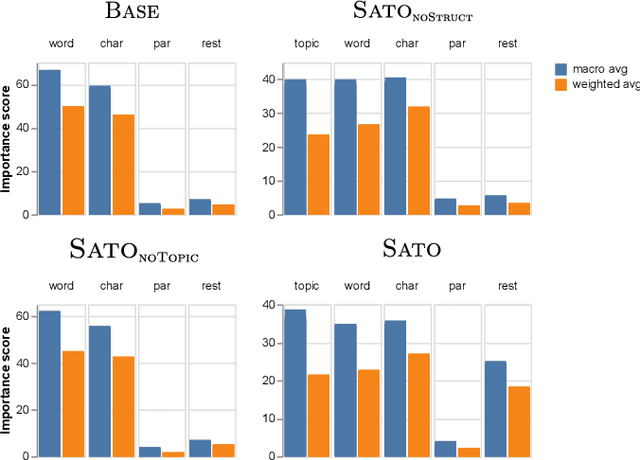
Detecting the semantic types of data columns in relational tables is important for various data preparation and information retrieval tasks such as data cleaning, schema matching, data discovery, and semantic search. However, existing detection approaches either perform poorly with dirty data, support only a limited number of semantic types, fail to incorporate the table context of columns or rely on large sample sizes in the training data. We introduce Sato, a hybrid machine learning model to automatically detect the semantic types of columns in tables, exploiting the signals from the context as well as the column values. Sato combines a deep learning model trained on a large-scale table corpus with topic modeling and structured prediction to achieve support-weighted and macro average F1 scores of 0.901 and 0.973, respectively, exceeding the state-of-the-art performance by a significant margin. We extensively analyze the overall and per-type performance of Sato, discussing how individual modeling components, as well as feature categories, contribute to its performance.