 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Human Judgments of Causality
Dec 19, 2019

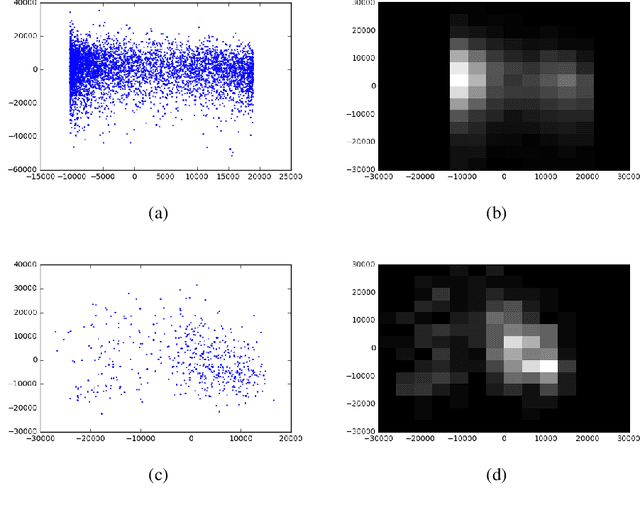
Discriminating between causality and correlation is a major problem in machine learning, and theoretical tools for determining causality are still being developed. However, people commonly make causality judgments and are often correct, even in unfamiliar domains. What are humans doing to make these judgments? This paper examines differences in human experts' and non-experts' ability to attribute causality by comparing their performances to those of machine-learning algorithms. We collected human judgments by using Amazon Mechanical Turk (MTurk) and then divided the human subjects into two groups: experts and non-experts. We also prepared expert and non-expert machine algorithms based on different training of convolutional neural network (CNN) models. The results showed that human experts' judgments were similar to those made by an "expert" CNN model trained on a large number of examples from the target domain. The human non-experts' judgments resembled the prediction outputs of the CNN model that was trained on only the small number of examples used during the MTurk instruction. We also analyzed the differences between the expert and non-expert machine algorithms based on their neural representations to evaluate the performances, providing insight into the human experts' and non-experts' cognitive abilities.
Generalized Compression Dictionary Distance as Universal Similarity Measure
Oct 21, 2014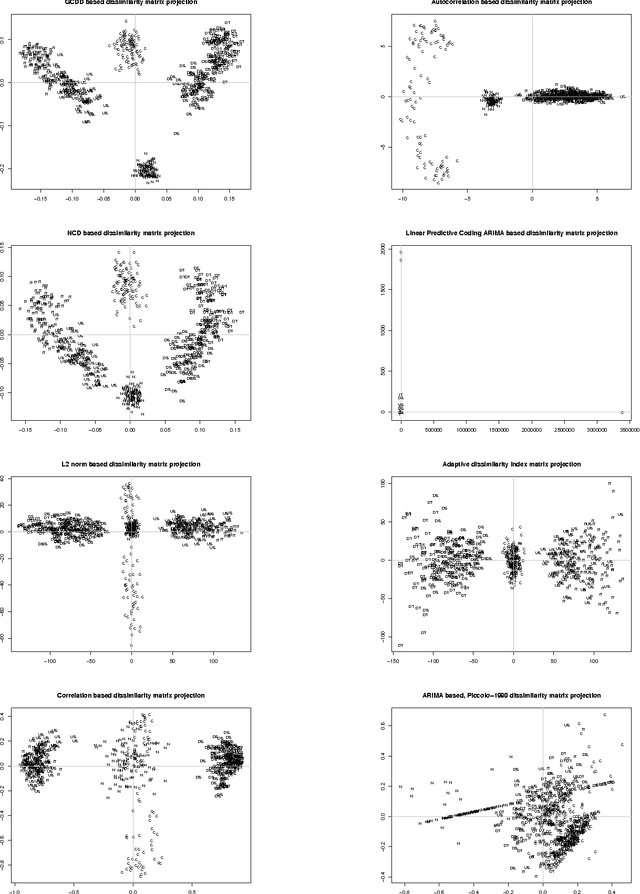
We present a new similarity measure based on information theoretic measures which is superior than Normalized Compression Distance for clustering problems and inherits the useful properties of conditional Kolmogorov complexity. We show that Normalized Compression Dictionary Size and Normalized Compression Dictionary Entropy are computationally more efficient, as the need to perform the compression itself is eliminated. Also they scale linearly with exponential vector size growth and are content independent. We show that normalized compression dictionary distance is compressor independent, if limited to lossless compressors, which gives space for optimizations and implementation speed improvement for real-time and big data applications. The introduced measure is applicable for machine learning tasks of parameter-free unsupervised clustering, supervised learning such as classification and regression, feature selection, and is applicable for big data problems with order of magnitude speed increase.
Daily Stress Recognition from Mobile Phone Data, Weather Conditions and Individual Traits
Oct 21, 2014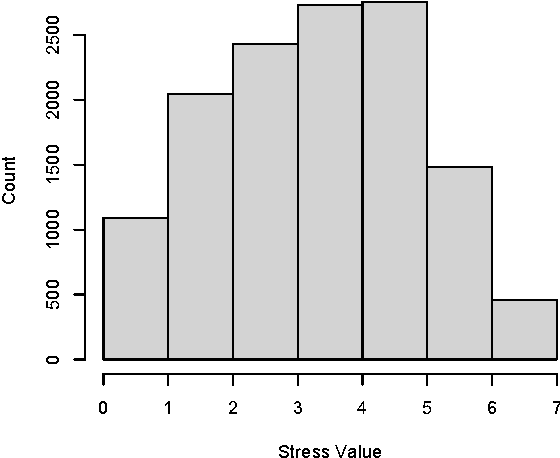
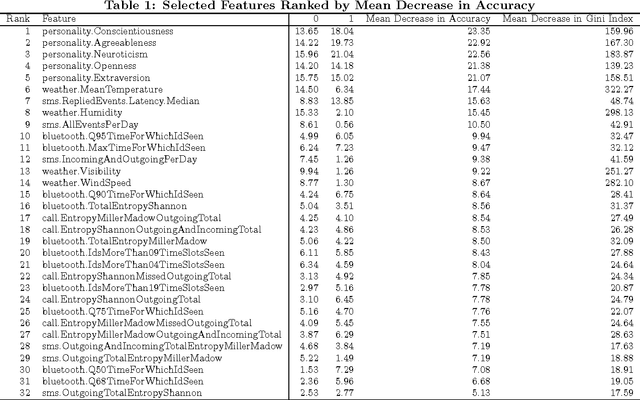
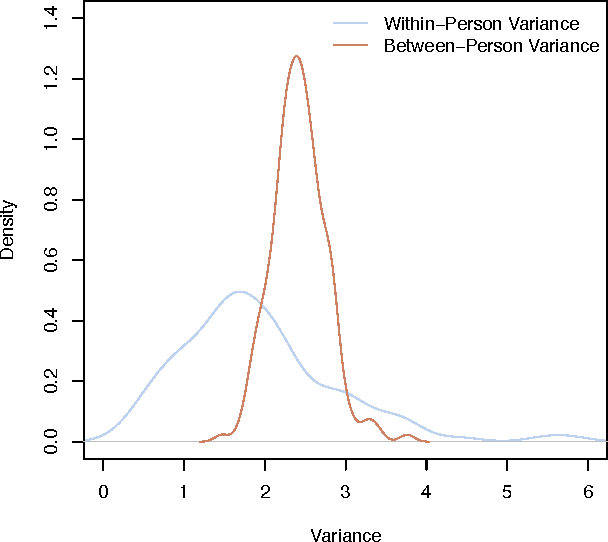

Research has proven that stress reduces quality of life and causes many diseases. For this reason, several researchers devised stress detection systems based on physiological parameters. However, these systems require that obtrusive sensors are continuously carried by the user. In our paper, we propose an alternative approach providing evidence that daily stress can be reliably recognized based on behavioral metrics, derived from the user's mobile phone activity and from additional indicators, such as the weather conditions (data pertaining to transitory properties of the environment) and the personality traits (data concerning permanent dispositions of individuals). Our multifactorial statistical model, which is person-independent, obtains the accuracy score of 72.28% for a 2-class daily stress recognition problem. The model is efficient to implement for most of multimedia applications due to highly reduced low-dimensional feature space (32d). Moreover, we identify and discuss the indicators which have strong predictive power.