 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Compression Dictionary Distance as Universal Similarity Measure
Paper and Code
Oct 21, 2014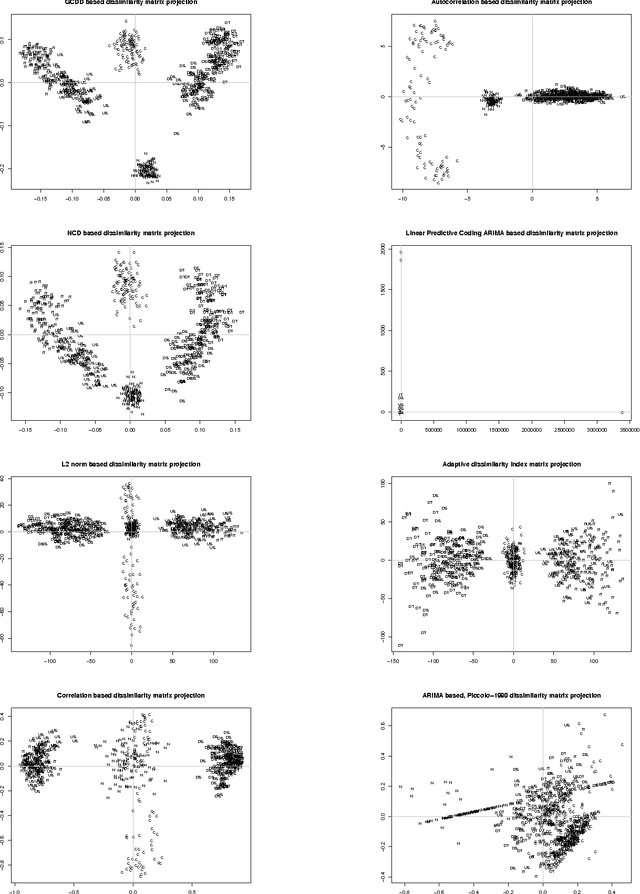
We present a new similarity measure based on information theoretic measures which is superior than Normalized Compression Distance for clustering problems and inherits the useful properties of conditional Kolmogorov complexity. We show that Normalized Compression Dictionary Size and Normalized Compression Dictionary Entropy are computationally more efficient, as the need to perform the compression itself is eliminated. Also they scale linearly with exponential vector size growth and are content independent. We show that normalized compression dictionary distance is compressor independent, if limited to lossless compressors, which gives space for optimizations and implementation speed improvement for real-time and big data applications. The introduced measure is applicable for machine learning tasks of parameter-free unsupervised clustering, supervised learning such as classification and regression, feature selection, and is applicable for big data problems with order of magnitude speed increase.