 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Natural Language and Interactive What-If Interfaces via LLM-Generated Declarative Specification
Apr 08, 2026What-if analysis (WIA) is an iterative, multi-step process where users explore and compare hypothetical scenarios by adjusting parameters, applying constraints, and scoping data through interactive interfaces. Current tools fall short of supporting effective interactive WIA: spreadsheet and BI tools require time-consuming and laborious setup, while LLM-based chatbot interfaces are semantically fragile, frequently misinterpret intent, and produce inconsistent results as conversations progress. To address these limitations, we present a two-stage workflow that translates natural language (NL) WIA questions into interactive visual interfaces via an intermediate representation, powered by the Praxa Specification Language (PSL): first, LLMs generate PSL specifications from NL questions capturing analytical intent and logic, enabling validation and repair of erroneous specifications; and second, the specifications are compiled into interactive visual interfaces with parameter controls and linked visualizations. We benchmark this workflow with 405 WIA questions spanning 11 WIA types, 5 datasets, and 3 state-of-the-art LLMs. The results show that across models, half of specifications (52.42%) are generated correctly without intervention. We perform an analysis of the failure cases and derive an error taxonomy spanning non-functional errors (specifications fail to compile) and functional errors (specifications compile but misrepresent intent). Based on the taxonomy, we apply targeted repairs on the failure cases using few-shot prompts and improve the success rate to 80.42%. Finally, we show how undetected functional errors propagate through compilation into plausible but misleading interfaces, demonstrating that the intermediate specification is critical for reliably bridging NL and interactive WIA interface in LLM-powered WIA systems.
Enhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
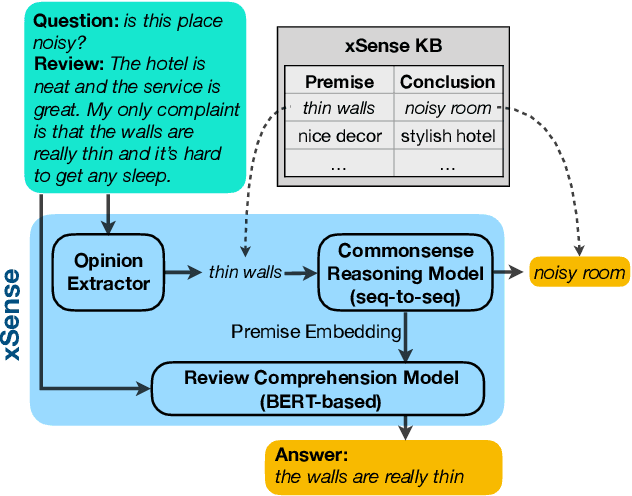
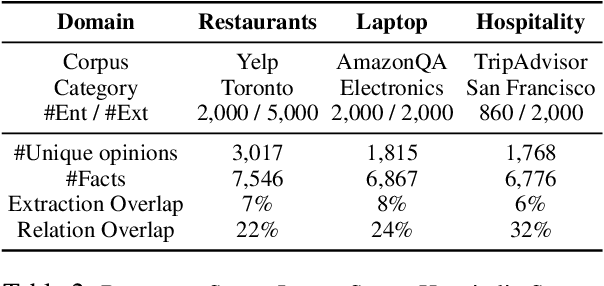
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.