 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Summarizing Community-based Question-Answer Pairs
Nov 17, 2022



Community-based Question Answering (CQA), which allows users to acquire their desired information, has increasingly become an essential component of online services in various domains such as E-commerce, travel, and dining. However, an overwhelming number of CQA pairs makes it difficult for users without particular intent to find useful information spread over CQA pairs. To help users quickly digest the key information, we propose the novel CQA summarization task that aims to create a concise summary from CQA pairs. To this end, we first design a multi-stage data annotation process and create a benchmark dataset, CoQASUM, based on the Amazon QA corpus. We then compare a collection of extractive and abstractive summarization methods and establish a strong baseline approach DedupLED for the CQA summarization task. Our experiment further confirms two key challenges, sentence-type transfer and deduplication removal, towards the CQA summarization task. Our data and code are publicly available.
Noisy Pairing and Partial Supervision for Opinion Summarization
Nov 16, 2022
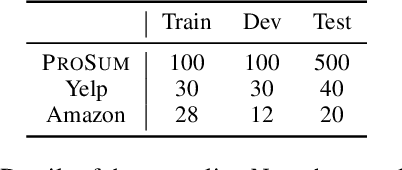


Current opinion summarization systems simply generate summaries reflecting important opinions from customer reviews, but the generated summaries may not attract the reader's attention. Although it is helpful to automatically generate professional reviewer-like summaries from customer reviews, collecting many training pairs of customer and professional reviews is generally tricky. We propose a weakly supervised opinion summarization framework, Noisy Pairing and Partial Supervision (NAPA) that can build a stylized opinion summarization system with no customer-professional review pairs. Experimental results show consistent improvements in automatic evaluation metrics, and qualitative analysis shows that our weakly supervised opinion summarization system can generate summaries that look more like those written by professional reviewers.
Beyond Opinion Mining: Summarizing Opinions of Customer Reviews
Jun 03, 2022
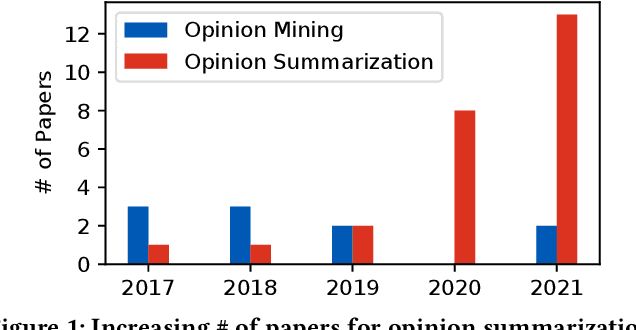
Customer reviews are vital for making purchasing decisions in the Information Age. Such reviews can be automatically summarized to provide the user with an overview of opinions. In this tutorial, we present various aspects of opinion summarization that are useful for researchers and practitioners. First, we will introduce the task and major challenges. Then, we will present existing opinion summarization solutions, both pre-neural and neural. We will discuss how summarizers can be trained in the unsupervised, few-shot, and supervised regimes. Each regime has roots in different machine learning methods, such as auto-encoding, controllable text generation, and variational inference. Finally, we will discuss resources and evaluation methods and conclude with the future directions. This three-hour tutorial will provide a comprehensive overview over major advances in opinion summarization. The listeners will be well-equipped with the knowledge that is both useful for research and practical applications.
Comparative Opinion Summarization via Collaborative Decoding
Oct 14, 2021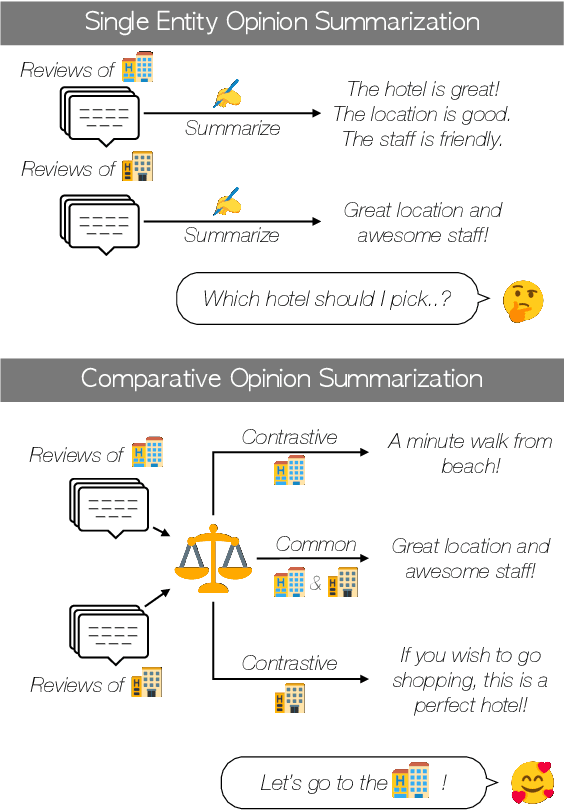
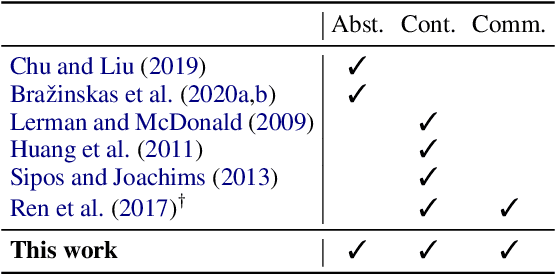
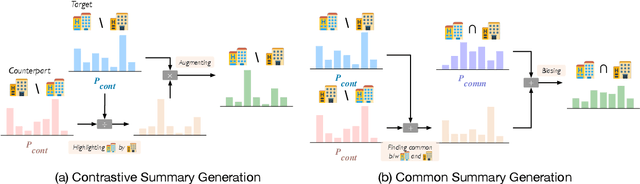

Opinion summarization focuses on generating summaries that reflect popular opinions of multiple reviews for a single entity (e.g., a hotel or a product.) While generated summaries offer general and concise information about a particular entity, the information may be insufficient to help the user compare multiple entities. Thus, the user may still struggle with the question "Which one should I pick?" In this paper, we propose a {\em comparative opinion summarization} task, which is to generate two contrastive summaries and one common summary from two given sets of reviews from different entities. We develop a comparative summarization framework CoCoSum, which consists of two few-shot summarization models that are jointly used to generate contrastive and common summaries. Experimental results on a newly created benchmark CoCoTrip show that CoCoSum can produce high-quality contrastive and common summaries than state-of-the-art opinion summarization models.
Convex Aggregation for Opinion Summarization
Apr 03, 2021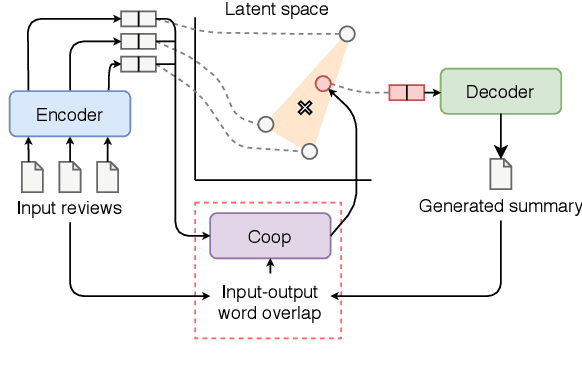
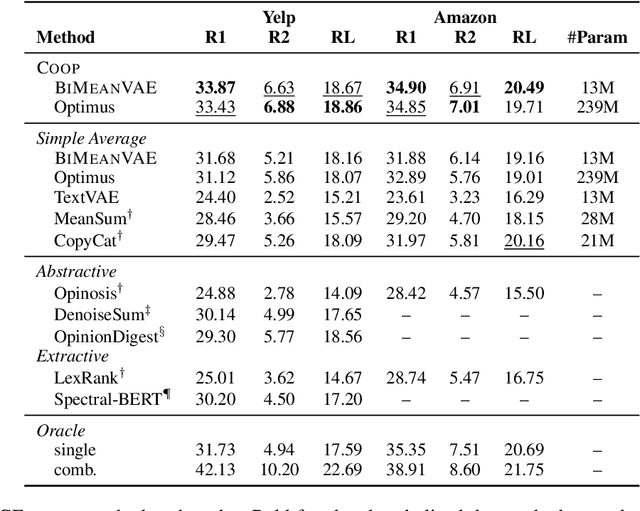
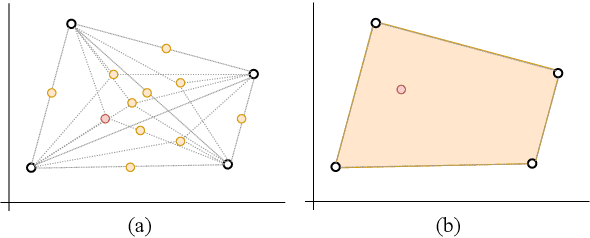
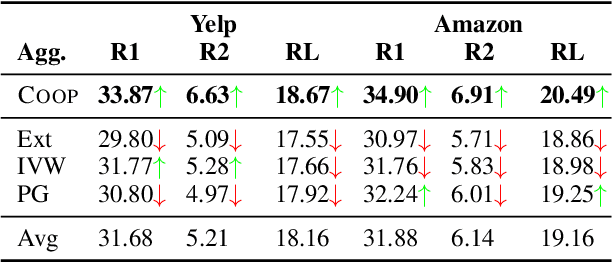
Recent approaches for unsupervised opinion summarization have predominantly used the review reconstruction training paradigm. An encoder-decoder model is trained to reconstruct single reviews and learns a latent review encoding space. At summarization time, the unweighted average of latent review vectors is decoded into a summary. In this paper, we challenge the convention of simply averaging the latent vector set, and claim that this simplistic approach fails to consider variations in the quality of input reviews or the idiosyncrasies of the decoder. We propose Coop, a convex vector aggregation framework for opinion summarization, that searches for better combinations of input reviews. Coop requires no further supervision and uses a simple word overlap objective to help the model generate summaries that are more consistent with input reviews. Experimental results show that extending opinion summarizers with Coop results in state-of-the-art performance, with ROUGE-1 improvements of 3.7% and 2.9% on the Yelp and Amazon benchmark datasets, respectively.
Extractive Opinion Summarization in Quantized Transformer Spaces
Dec 08, 2020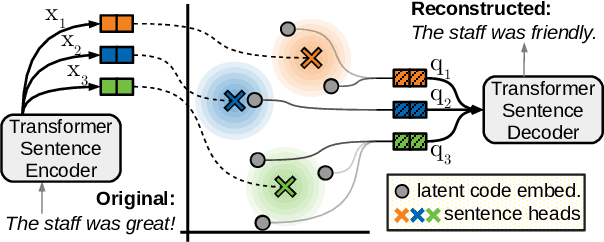

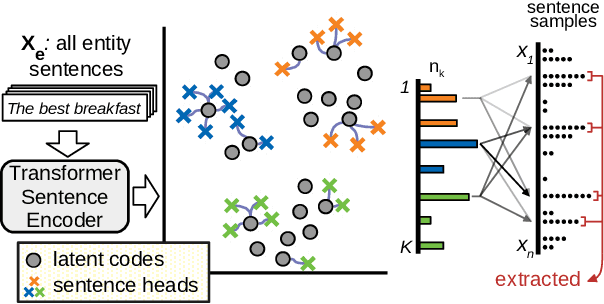
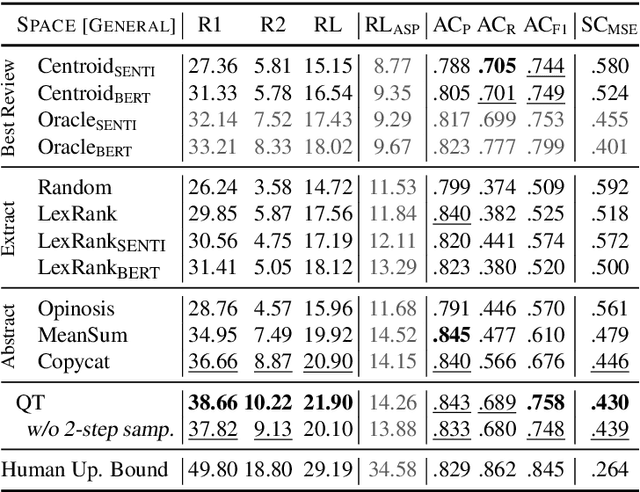
We present the Quantized Transformer (QT), an unsupervised system for extractive opinion summarization. QT is inspired by Vector-Quantized Variational Autoencoders, which we repurpose for popularity-driven summarization. It uses a clustering interpretation of the quantized space and a novel extraction algorithm to discover popular opinions among hundreds of reviews, a significant step towards opinion summarization of practical scope. In addition, QT enables controllable summarization without further training, by utilizing properties of the quantized space to extract aspect-specific summaries. We also make publicly available SPACE, a large-scale evaluation benchmark for opinion summarizers, comprising general and aspect-specific summaries for 50 hotels. Experiments demonstrate the promise of our approach, which is validated by human studies where judges showed clear preference for our method over competitive baselines.
Deep or Simple Models for Semantic Tagging? It Depends on your Data
Jul 11, 2020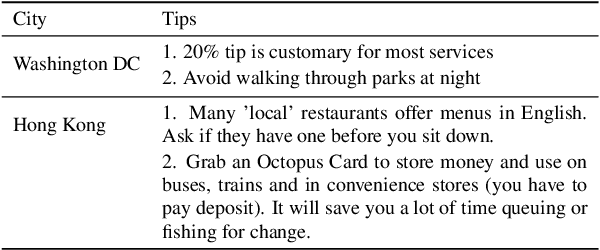
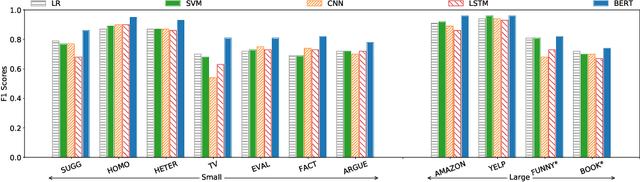
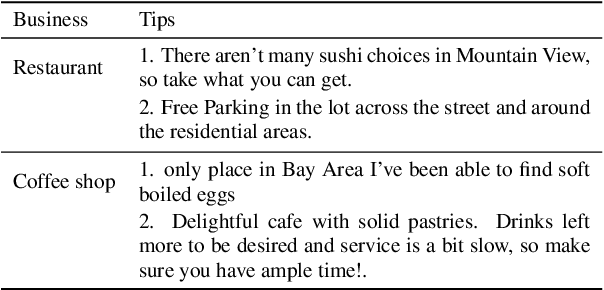
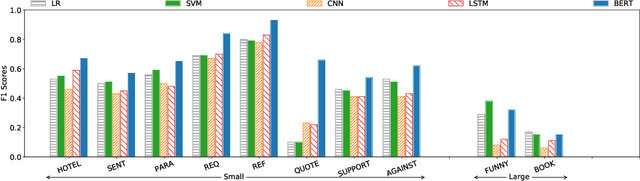
Semantic tagging, which has extensive applications in text mining, predicts whether a given piece of text conveys the meaning of a given semantic tag. The problem of semantic tagging is largely solved with supervised learning and today, deep learning models are widely perceived to be better for semantic tagging. However, there is no comprehensive study supporting the popular belief. Practitioners often have to train different types of models for each semantic tagging task to identify the best model. This process is both expensive and inefficient. We embark on a systematic study to investigate the following question: Are deep models the best performing model for all semantic tagging tasks? To answer this question, we compare deep models against "simple models" over datasets with varying characteristics. Specifically, we select three prevalent deep models (i.e. CNN, LSTM, and BERT) and two simple models (i.e. LR and SVM), and compare their performance on the semantic tagging task over 21 datasets. Results show that the size, the label ratio, and the label cleanliness of a dataset significantly impact the quality of semantic tagging. Simple models achieve similar tagging quality to deep models on large datasets, but the runtime of simple models is much shorter. Moreover, simple models can achieve better tagging quality than deep models when targeting datasets show worse label cleanliness and/or more severe imbalance. Based on these findings, our study can systematically guide practitioners in selecting the right learning model for their semantic tagging task.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020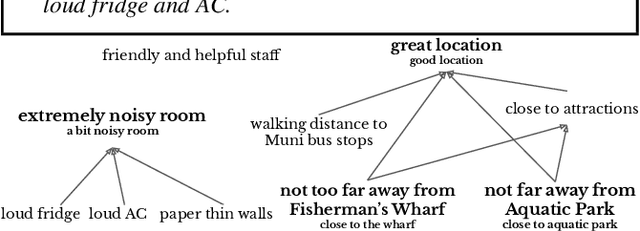


We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.