 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Language Models Improve Giants by Rewriting Their Outputs
May 22, 2023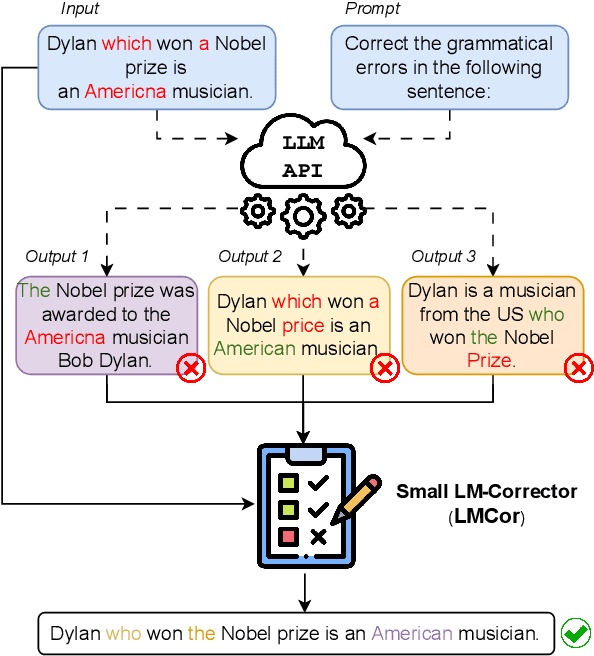
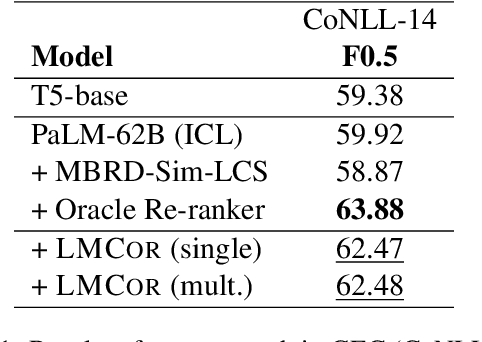
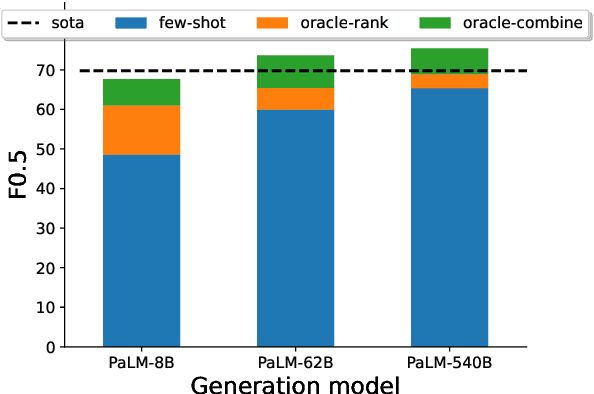

Large language models (LLMs) have demonstrated impressive few-shot learning capabilities, but they often underperform compared to fine-tuned models on challenging tasks. Furthermore, their large size and restricted access only through APIs make task-specific fine-tuning impractical. Moreover, LLMs are sensitive to different aspects of prompts (e.g., the selection and order of demonstrations) and can thus require time-consuming prompt engineering. In this light, we propose a method to correct LLM outputs without relying on their weights. First, we generate a pool of candidates by few-shot prompting an LLM. Second, we refine the LLM-generated outputs using a smaller model, the LM-corrector (LMCor), which is trained to rank, combine and rewrite the candidates to produce the final target output. Our experiments demonstrate that even a small LMCor model (250M) substantially improves the few-shot performance of LLMs (62B) across diverse tasks. Moreover, we illustrate that the LMCor exhibits robustness against different prompts, thereby minimizing the need for extensive prompt engineering. Finally, we showcase that the LMCor can be seamlessly integrated with different LLMs at inference time, serving as a plug-and-play module to improve their performance.
Interactive-Chain-Prompting: Ambiguity Resolution for Crosslingual Conditional Generation with Interaction
Jan 24, 2023



Crosslingual conditional generation (e.g., machine translation) has long enjoyed the benefits of scaling. Nonetheless, there are still issues that scale alone may not overcome. A source query in one language, for instance, may yield several translation options in another language without any extra context. Only one translation could be acceptable however, depending on the translator's preferences and goals. Choosing the incorrect option might significantly affect translation usefulness and quality. We propose a novel method interactive-chain prompting -- a series of question, answering and generation intermediate steps between a Translator model and a User model -- that reduces translations into a list of subproblems addressing ambiguities and then resolving such subproblems before producing the final text to be translated. To check ambiguity resolution capabilities and evaluate translation quality, we create a dataset exhibiting different linguistic phenomena which leads to ambiguities at inference for four languages. To encourage further exploration in this direction, we release all datasets. We note that interactive-chain prompting, using eight interactions as exemplars, consistently surpasses prompt-based methods with direct access to background information to resolve ambiguities.
Beyond Opinion Mining: Summarizing Opinions of Customer Reviews
Jun 03, 2022
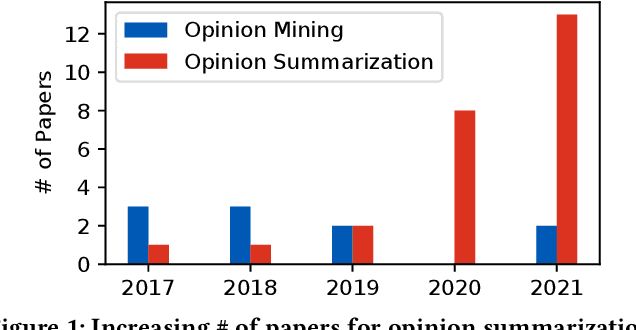
Customer reviews are vital for making purchasing decisions in the Information Age. Such reviews can be automatically summarized to provide the user with an overview of opinions. In this tutorial, we present various aspects of opinion summarization that are useful for researchers and practitioners. First, we will introduce the task and major challenges. Then, we will present existing opinion summarization solutions, both pre-neural and neural. We will discuss how summarizers can be trained in the unsupervised, few-shot, and supervised regimes. Each regime has roots in different machine learning methods, such as auto-encoding, controllable text generation, and variational inference. Finally, we will discuss resources and evaluation methods and conclude with the future directions. This three-hour tutorial will provide a comprehensive overview over major advances in opinion summarization. The listeners will be well-equipped with the knowledge that is both useful for research and practical applications.
Efficient Few-Shot Fine-Tuning for Opinion Summarization
May 08, 2022



Abstractive summarization models are typically pre-trained on large amounts of generic texts, then fine-tuned on tens or hundreds of thousands of annotated samples. However, in opinion summarization, large annotated datasets of reviews paired with reference summaries are not available and would be expensive to create. This calls for fine-tuning methods robust to overfitting on small datasets. In addition, generically pre-trained models are often not accustomed to the specifics of customer reviews and, after fine-tuning, yield summaries with disfluencies and semantic mistakes. To address these problems, we utilize an efficient few-shot method based on adapters which, as we show, can easily store in-domain knowledge. Instead of fine-tuning the entire model, we add adapters and pre-train them in a task-specific way on a large corpus of unannotated customer reviews, using held-out reviews as pseudo summaries. Then, fine-tune the adapters on the small available human-annotated dataset. We show that this self-supervised adapter pre-training improves summary quality over standard fine-tuning by 2.0 and 1.3 ROUGE-L points on the Amazon and Yelp datasets, respectively. Finally, for summary personalization, we condition on aspect keyword queries, automatically created from generic datasets. In the same vein, we pre-train the adapters in a query-based manner on customer reviews and then fine-tune them on annotated datasets. This results in better-organized summary content reflected in improved coherence and fewer redundancies.
Learning Opinion Summarizers by Selecting Informative Reviews
Sep 09, 2021
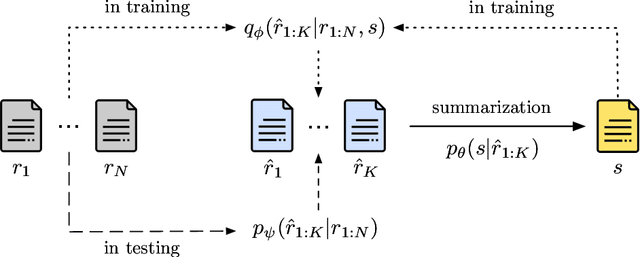

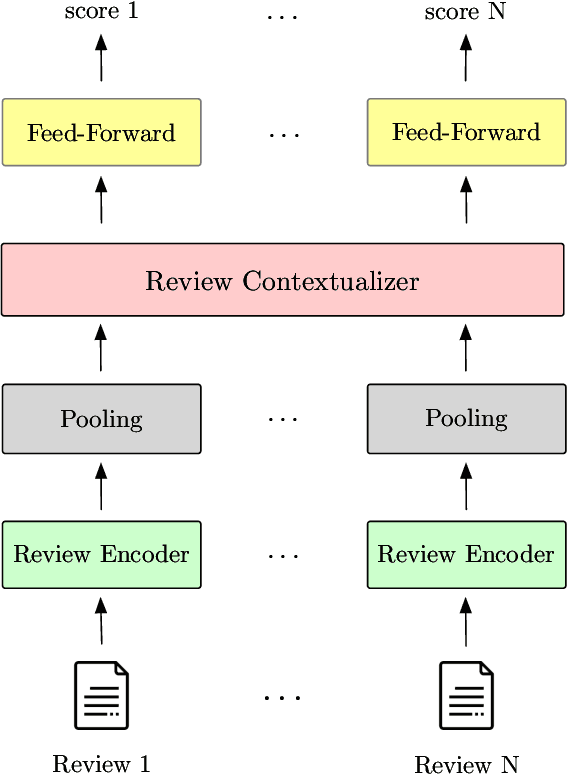
Opinion summarization has been traditionally approached with unsupervised, weakly-supervised and few-shot learning techniques. In this work, we collect a large dataset of summaries paired with user reviews for over 31,000 products, enabling supervised training. However, the number of reviews per product is large (320 on average), making summarization - and especially training a summarizer - impractical. Moreover, the content of many reviews is not reflected in the human-written summaries, and, thus, the summarizer trained on random review subsets hallucinates. In order to deal with both of these challenges, we formulate the task as jointly learning to select informative subsets of reviews and summarizing the opinions expressed in these subsets. The choice of the review subset is treated as a latent variable, predicted by a small and simple selector. The subset is then fed into a more powerful summarizer. For joint training, we use amortized variational inference and policy gradient methods. Our experiments demonstrate the importance of selecting informative reviews resulting in improved quality of summaries and reduced hallucinations.
Transductive Learning for Abstractive News Summarization
Apr 17, 2021
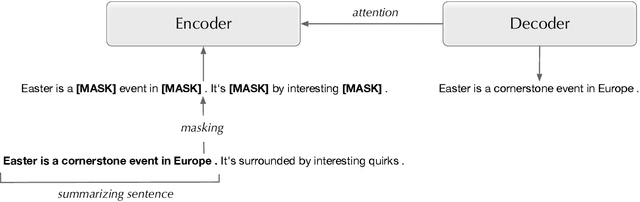
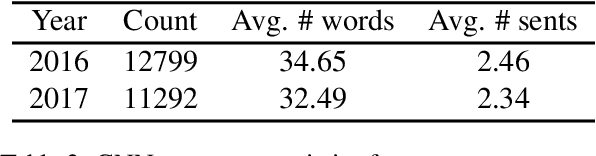
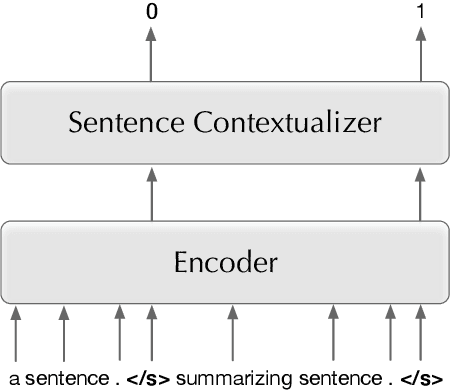
Pre-trained language models have recently advanced abstractive summarization. These models are further fine-tuned on human-written references before summary generation in test time. In this work, we propose the first application of transductive learning to summarization. In this paradigm, a model can learn from the test set's input before inference. To perform transduction, we propose to utilize input document summarizing sentences to construct references for learning in test time. These sentences are often compressed and fused to form abstractive summaries and provide omitted details and additional context to the reader. We show that our approach yields state-of-the-art results on CNN/DM and NYT datasets. For instance, we achieve over 1 ROUGE-L point improvement on CNN/DM. Further, we show the benefits of transduction from older to more recent news. Finally, through human and automatic evaluation, we show that our summaries become more abstractive and coherent.
Few-Shot Learning for Abstractive Multi-Document Opinion Summarization
Apr 30, 2020
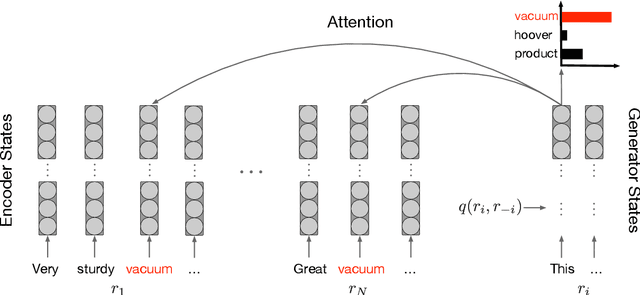
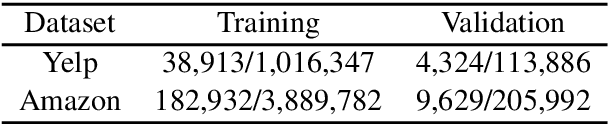
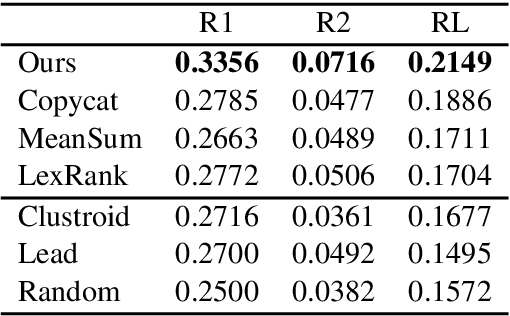
Opinion summarization is an automatic creation of text reflecting subjective information expressed in multiple documents, such as user reviews of a product. The task is practically important and has attracted a lot of attention. However, due to a high cost of summary production, datasets large enough for training supervised models are lacking. Instead, the task has been traditionally approached with extractive methods that learn to select text fragments in an unsupervised or weakly-supervised way. Recently, it has been shown that abstractive summaries, potentially more fluent and better at reflecting conflicting information, can also be produced in an unsupervised fashion. However, these models, not being exposed to the actual summaries, fail to capture their essential properties. In this work, we show that even a handful of summaries is sufficient to bootstrap generation of the summary text with all expected properties, such as writing style, informativeness, fluency, and sentiment preservation. We start by training a language model to generate a new product review given available reviews of the product. The model is aware of the properties: it proceeds with first generating property values and then producing a review conditioned on them. We do not use any summaries in this stage and the property values are derived from reviews with no manual effort. In the second stage, we fine-tune the module predicting the property values on a few available summaries. This lets us switch the generator to the summarization mode. Our approach substantially outperforms previous extractive and abstractive methods in automatic and human evaluation.
Unsupervised Multi-Document Opinion Summarization as Copycat-Review Generation
Nov 06, 2019
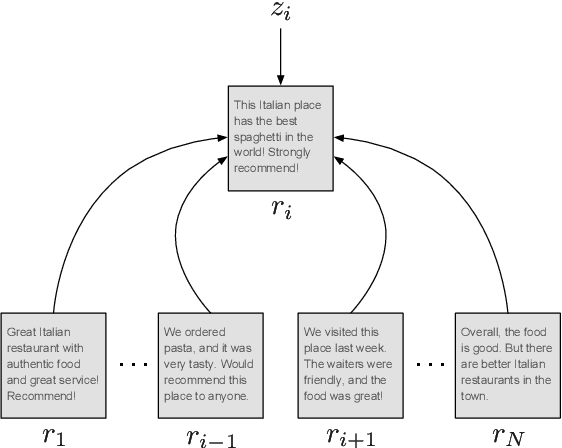
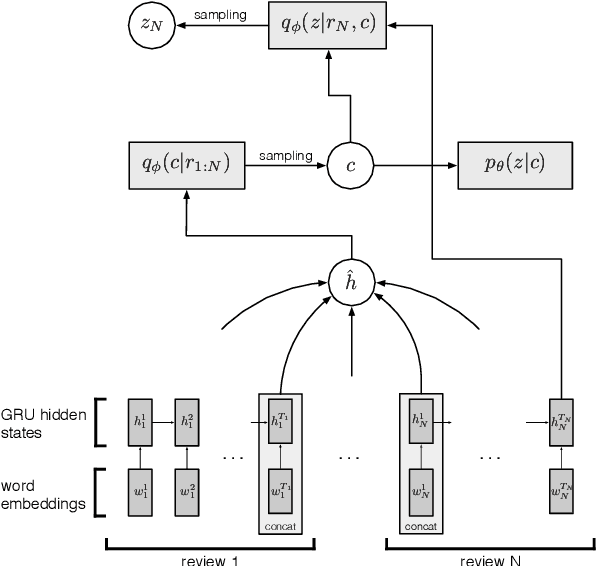
Summarization of opinions is the process of automatically creating text summaries that reflect subjective information expressed in input documents, such as product reviews. While most previous research in opinion summarization has focused on the extractive setting, i.e. selecting fragments of the input documents to produce a summary, we let the model generate novel sentences and hence produce fluent text. Supervised abstractive summarization methods typically rely on large quantities of document-summary pairs which are expensive to acquire. In contrast, we consider the unsupervised setting, in other words, we do not use any summaries in training. We define a generative model for a multi-product review collection. Intuitively, we want to design such a model that, when generating a new review given a set of other reviews of the product, we can control the `amount of novelty' going into the new review or, equivalently, vary the degree of deviation from the input reviews. At test time, when generating summaries, we force the novelty to be minimal, and produce a text reflecting consensus opinions. We capture this intuition by defining a hierarchical variational autoencoder model. Both individual reviews and products they correspond to are associated with stochastic latent codes, and the review generator ('decoder') has direct access to the text of input reviews through the pointer-generator mechanism. In experiments on Amazon and Yelp data, we show that in this model by setting at test time the review's latent code to its mean, we produce fluent and coherent summaries.
Embedding Words as Distributions with a Bayesian Skip-gram Model
Jun 10, 2018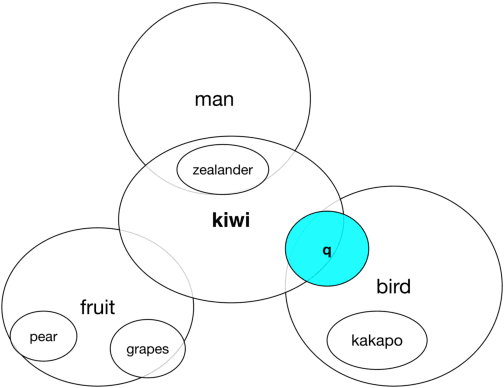
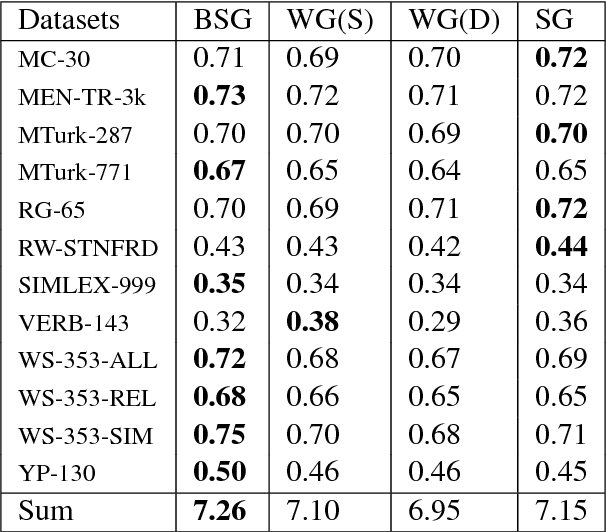
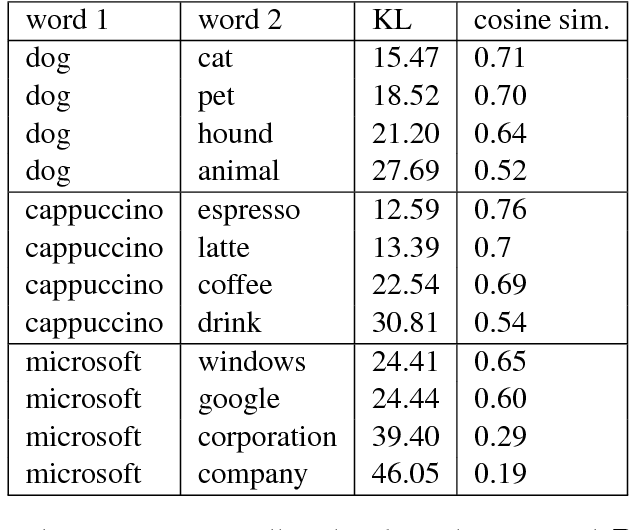
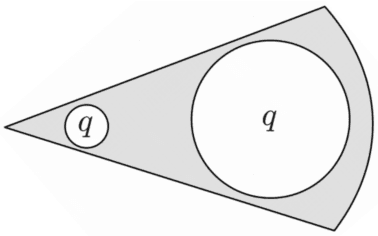
We introduce a method for embedding words as probability densities in a low-dimensional space. Rather than assuming that a word embedding is fixed across the entire text collection, as in standard word embedding methods, in our Bayesian model we generate it from a word-specific prior density for each occurrence of a given word. Intuitively, for each word, the prior density encodes the distribution of its potential 'meanings'. These prior densities are conceptually similar to Gaussian embeddings. Interestingly, unlike the Gaussian embeddings, we can also obtain context-specific densities: they encode uncertainty about the sense of a word given its context and correspond to posterior distributions within our model. The context-dependent densities have many potential applications: for example, we show that they can be directly used in the lexical substitution task. We describe an effective estimation method based on the variational autoencoding framework. We also demonstrate that our embeddings achieve competitive results on standard benchmarks.