 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness-Aware Decoding Strategies for Abstractive Summarization
Mar 06, 2023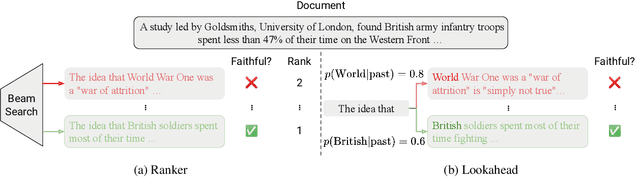
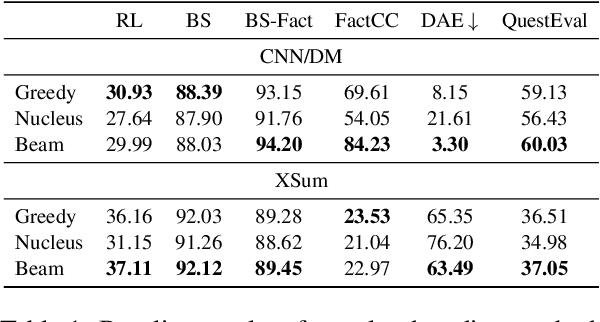
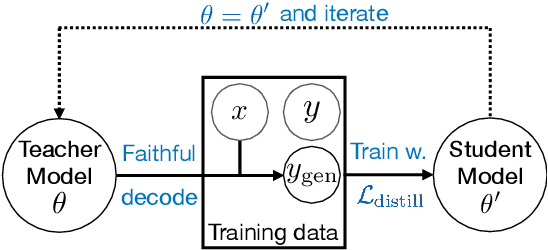
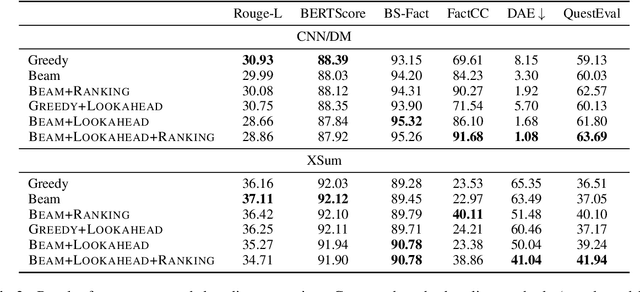
Despite significant progress in understanding and improving faithfulness in abstractive summarization, the question of how decoding strategies affect faithfulness is less studied. We present a systematic study of the effect of generation techniques such as beam search and nucleus sampling on faithfulness in abstractive summarization. We find a consistent trend where beam search with large beam sizes produces the most faithful summaries while nucleus sampling generates the least faithful ones. We propose two faithfulness-aware generation methods to further improve faithfulness over current generation techniques: (1) ranking candidates generated by beam search using automatic faithfulness metrics and (2) incorporating lookahead heuristics that produce a faithfulness score on the future summary. We show that both generation methods significantly improve faithfulness across two datasets as evaluated by four automatic faithfulness metrics and human evaluation. To reduce computational cost, we demonstrate a simple distillation approach that allows the model to generate faithful summaries with just greedy decoding. Our code is publicly available at https://github.com/amazon-science/faithful-summarization-generation
FactGraph: Evaluating Factuality in Summarization with Semantic Graph Representations
Apr 13, 2022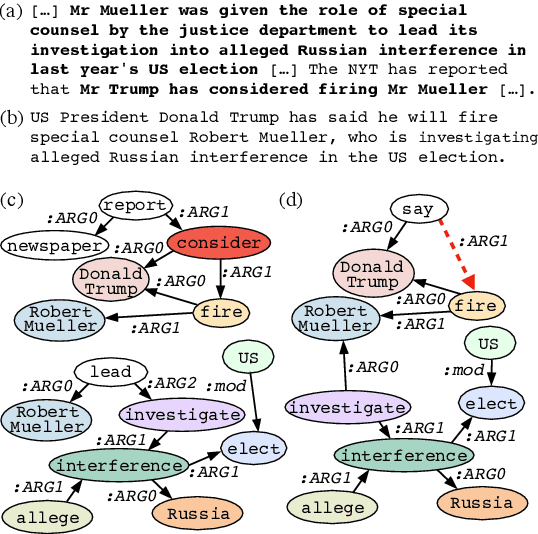
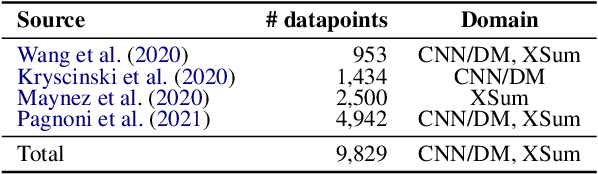
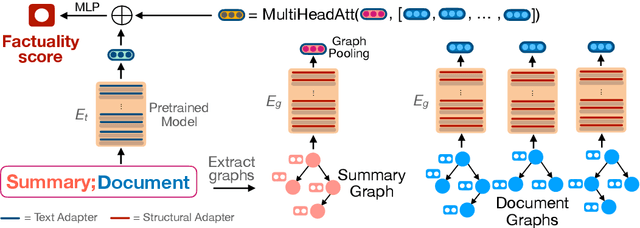

Despite recent improvements in abstractive summarization, most current approaches generate summaries that are not factually consistent with the source document, severely restricting their trust and usage in real-world applications. Recent works have shown promising improvements in factuality error identification using text or dependency arc entailments; however, they do not consider the entire semantic graph simultaneously. To this end, we propose FactGraph, a method that decomposes the document and the summary into structured meaning representations (MR), which are more suitable for factuality evaluation. MRs describe core semantic concepts and their relations, aggregating the main content in both document and summary in a canonical form, and reducing data sparsity. FactGraph encodes such graphs using a graph encoder augmented with structure-aware adapters to capture interactions among the concepts based on the graph connectivity, along with text representations using an adapter-based text encoder. Experiments on different benchmarks for evaluating factuality show that FactGraph outperforms previous approaches by up to 15%. Furthermore, FactGraph improves performance on identifying content verifiability errors and better captures subsentence-level factual inconsistencies.
Analyzing the Abstractiveness-Factuality Tradeoff With Nonlinear Abstractiveness Constraints
Aug 05, 2021
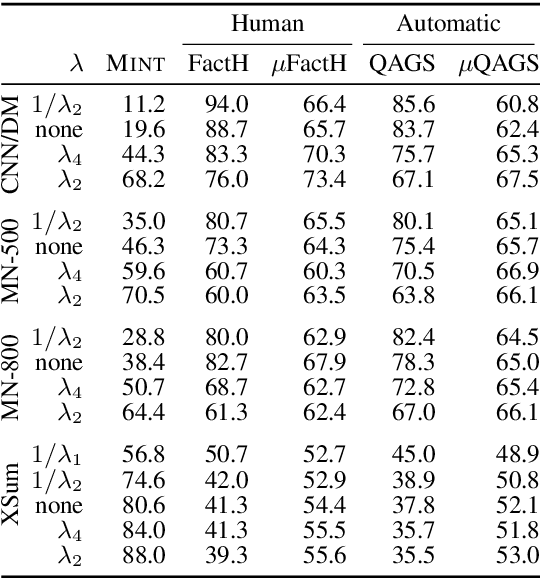
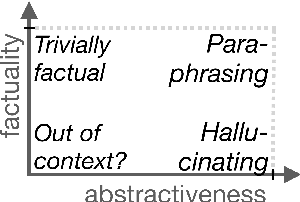
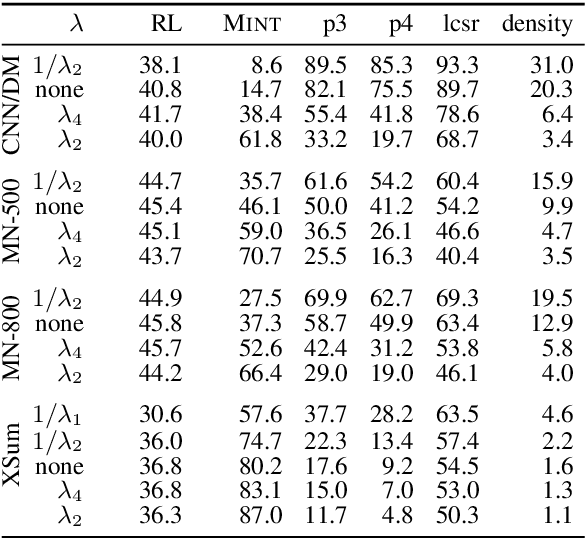
We analyze the tradeoff between factuality and abstractiveness of summaries. We introduce abstractiveness constraints to control the degree of abstractiveness at decoding time, and we apply this technique to characterize the abstractiveness-factuality tradeoff across multiple widely-studied datasets, using extensive human evaluations. We train a neural summarization model on each dataset and visualize the rates of change in factuality as we gradually increase abstractiveness using our abstractiveness constraints. We observe that, while factuality generally drops with increased abstractiveness, different datasets lead to different rates of factuality decay. We propose new measures to quantify the tradeoff between factuality and abstractiveness, incl. muQAGS, which balances factuality with abstractiveness. We also quantify this tradeoff in previous works, aiming to establish baselines for the abstractiveness-factuality tradeoff that future publications can compare against.
Transductive Learning for Abstractive News Summarization
Apr 17, 2021
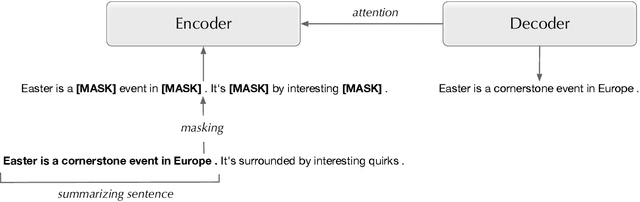
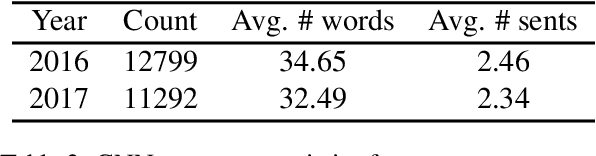
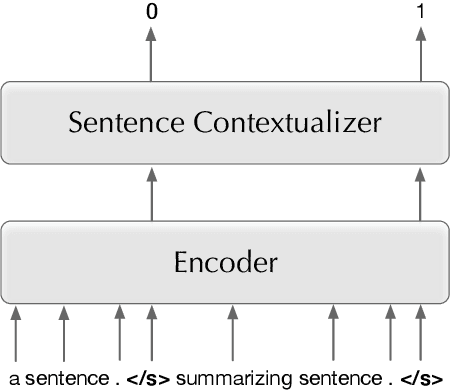
Pre-trained language models have recently advanced abstractive summarization. These models are further fine-tuned on human-written references before summary generation in test time. In this work, we propose the first application of transductive learning to summarization. In this paradigm, a model can learn from the test set's input before inference. To perform transduction, we propose to utilize input document summarizing sentences to construct references for learning in test time. These sentences are often compressed and fused to form abstractive summaries and provide omitted details and additional context to the reader. We show that our approach yields state-of-the-art results on CNN/DM and NYT datasets. For instance, we achieve over 1 ROUGE-L point improvement on CNN/DM. Further, we show the benefits of transduction from older to more recent news. Finally, through human and automatic evaluation, we show that our summaries become more abstractive and coherent.
Multi-Task Networks With Universe, Group, and Task Feature Learning
Jul 03, 2019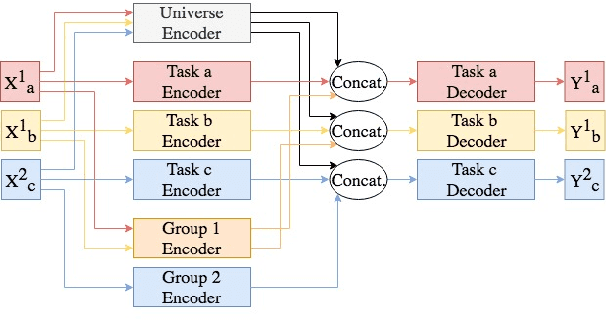
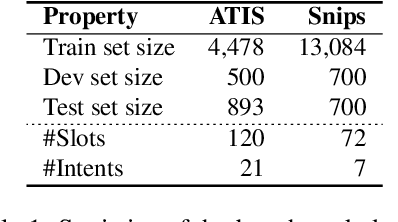
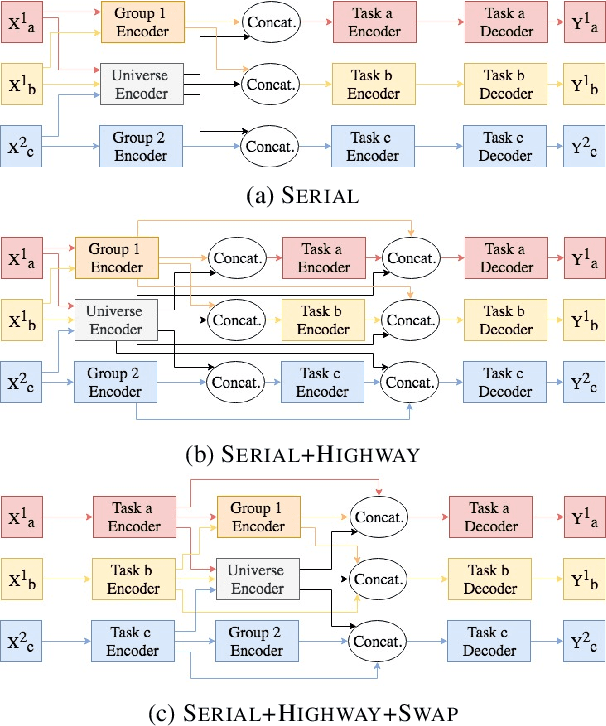

We present methods for multi-task learning that take advantage of natural groupings of related tasks. Task groups may be defined along known properties of the tasks, such as task domain or language. Such task groups represent supervised information at the inter-task level and can be encoded into the model. We investigate two variants of neural network architectures that accomplish this, learning different feature spaces at the levels of individual tasks, task groups, as well as the universe of all tasks: (1) parallel architectures encode each input simultaneously into feature spaces at different levels; (2) serial architectures encode each input successively into feature spaces at different levels in the task hierarchy. We demonstrate the methods on natural language understanding (NLU) tasks, where a grouping of tasks into different task domains leads to improved performance on ATIS, Snips, and a large inhouse dataset.