 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASS: Batched Attention-optimized Speculative Sampling
Apr 24, 2024



Speculative decoding has emerged as a powerful method to improve latency and throughput in hosting large language models. However, most existing implementations focus on generating a single sequence. Real-world generative AI applications often require multiple responses and how to perform speculative decoding in a batched setting while preserving its latency benefits poses non-trivial challenges. This paper describes a system of batched speculative decoding that sets a new state of the art in multi-sequence generation latency and that demonstrates superior GPU utilization as well as quality of generations within a time budget. For example, for a 7.8B-size model on a single A100 GPU and with a batch size of 8, each sequence is generated at an average speed of 5.8ms per token, the overall throughput being 1.1K tokens per second. These results represent state-of-the-art latency and a 2.15X speed-up over optimized regular decoding. Within a time budget that regular decoding does not finish, our system is able to generate sequences with HumanEval Pass@First of 43% and Pass@All of 61%, far exceeding what's feasible with single-sequence speculative decoding. Our peak GPU utilization during decoding reaches as high as 15.8%, more than 3X the highest of that of regular decoding and around 10X of single-sequence speculative decoding.
Bifurcated Attention for Single-Context Large-Batch Sampling
Mar 13, 2024In our study, we present bifurcated attention, a method developed for language model inference in single-context batch sampling contexts. This approach aims to reduce redundant memory IO costs, a significant factor in latency for high batch sizes and long context lengths. Bifurcated attention achieves this by dividing the attention mechanism during incremental decoding into two distinct GEMM operations, focusing on the KV cache from prefill and the decoding process. This method ensures precise computation and maintains the usual computational load (FLOPs) of standard attention mechanisms, but with reduced memory IO. Bifurcated attention is also compatible with multi-query attention mechanism known for reduced memory IO for KV cache, further enabling higher batch size and context length. The resulting efficiency leads to lower latency, improving suitability for real-time applications, e.g., enabling massively-parallel answer generation without substantially increasing latency, enhancing performance when integrated with postprocessing techniques such as reranking.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024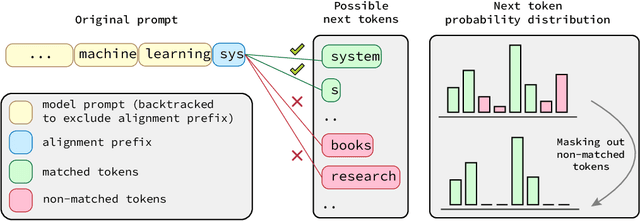



Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
Code Representation Learning At Scale
Feb 02, 2024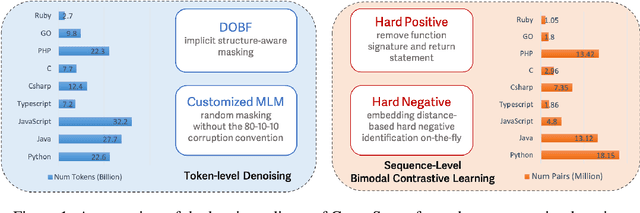
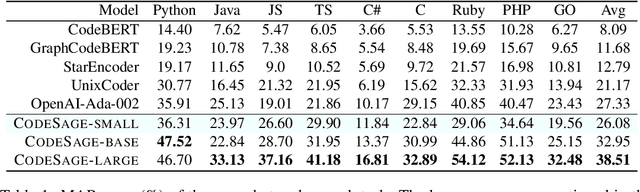
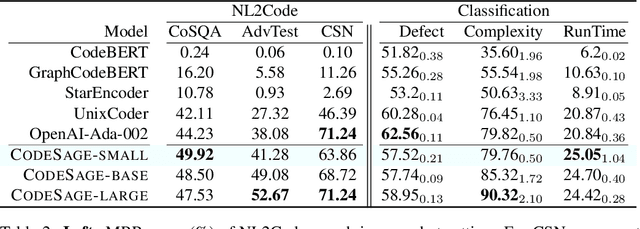
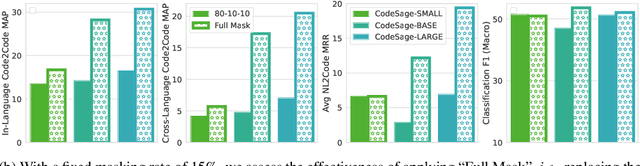
Recent studies have shown that code language models at scale demonstrate significant performance gains on downstream tasks, i.e., code generation. However, most of the existing works on code representation learning train models at a hundred million parameter scale using very limited pretraining corpora. In this work, we fuel code representation learning with a vast amount of code data via a two-stage pretraining scheme. We first train the encoders via a mix that leverages both randomness in masking language modeling and the structure aspect of programming language. We then enhance the representations via contrastive learning with hard negative and hard positive constructed in an unsupervised manner. We establish an off-the-shelf encoder model that persistently outperforms the existing models on a wide variety of downstream tasks by large margins. To comprehend the factors contributing to successful code representation learning, we conduct detailed ablations and share our findings on (i) a customized and effective token-level denoising scheme for source code; (ii) the importance of hard negatives and hard positives; (iii) how the proposed bimodal contrastive learning boost the cross-lingual semantic search performance; and (iv) how the pretraining schemes decide the downstream task performance scales with the model size.
* 10 pages
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Oct 17, 2023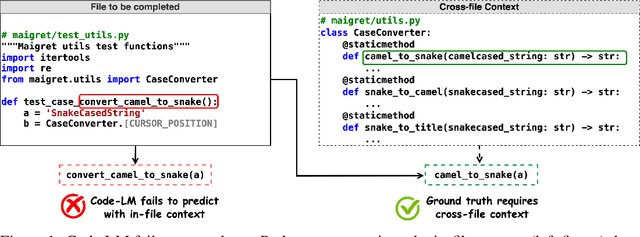
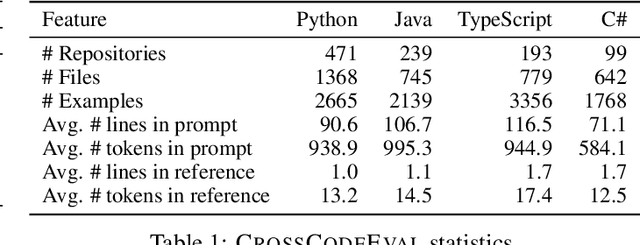
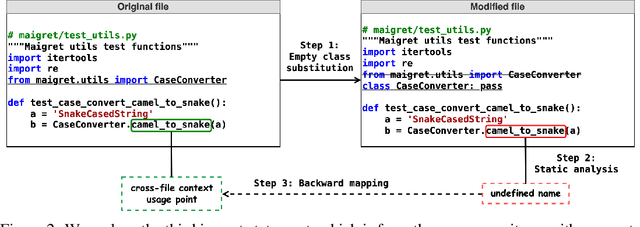
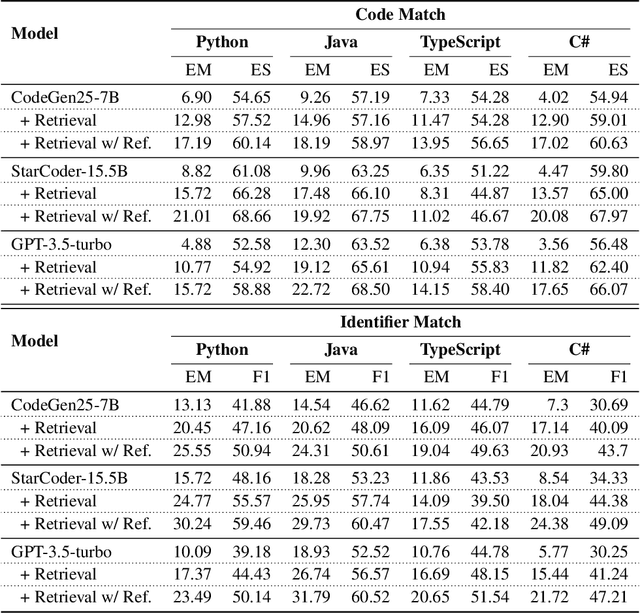
Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is also capable of assessing model's capability in leveraging extensive context to make better code completion. Finally, we benchmarked various methods in retrieving cross-file context, and show that CrossCodeEval can also be used to measure the capability of code retrievers.
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf
CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
Dec 20, 2022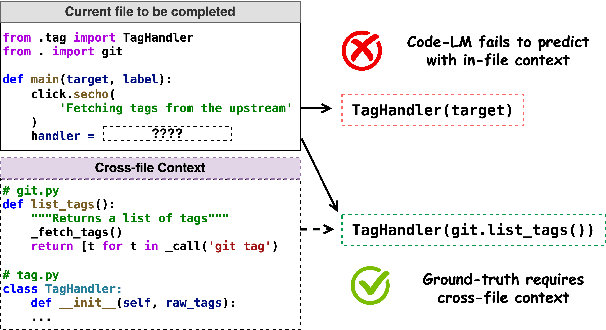

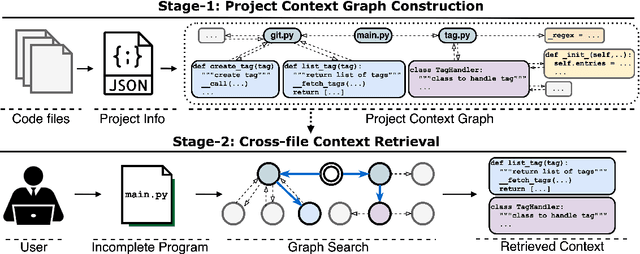

While pre-trained language models (LM) for code have achieved great success in code completion, they generate code conditioned only on the contents within the file, i.e., in-file context, but ignore the rich semantics in other files within the same project, i.e., cross-file context, a critical source of information that is especially useful in modern modular software development. Such overlooking constrains code language models' capacity in code completion, leading to unexpected behaviors such as generating hallucinated class member functions or function calls with unexpected arguments. In this work, we develop a cross-file context finder tool, CCFINDER, that effectively locates and retrieves the most relevant cross-file context. We propose CoCoMIC, a framework that incorporates cross-file context to learn the in-file and cross-file context jointly on top of pretrained code LMs. CoCoMIC successfully improves the existing code LM with a 19.30% relative increase in exact match and a 15.41% relative increase in identifier matching for code completion when the cross-file context is provided.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022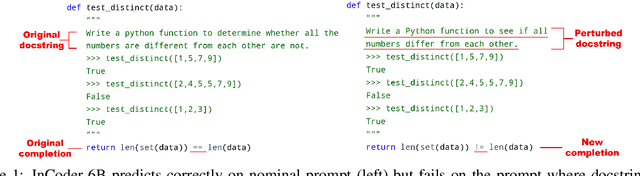

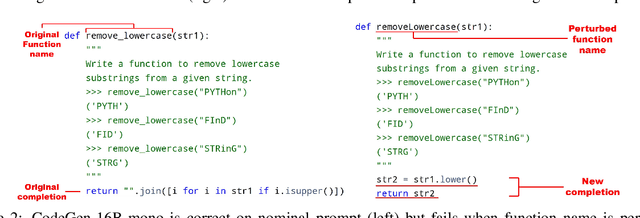

Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022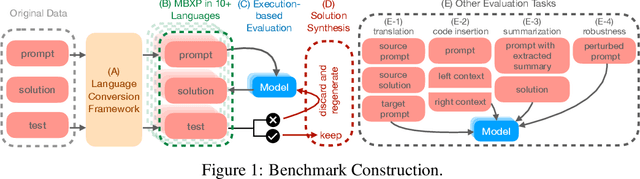
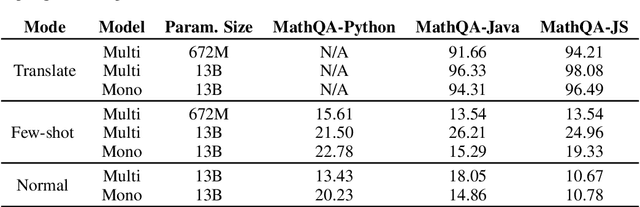


We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022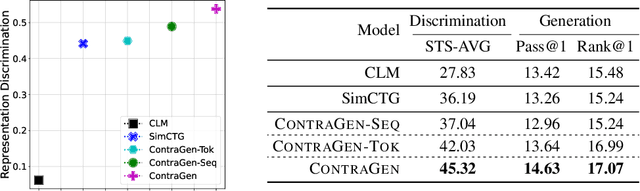
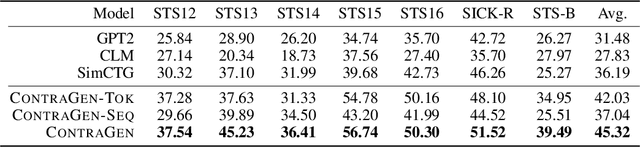
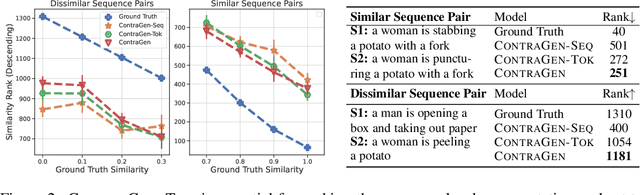
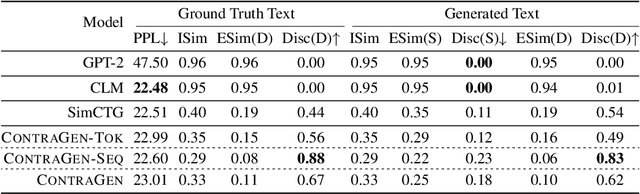
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.