 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Knowledge to Care: Knowledge Graph-Augmented Medical Follow-Up Question Generation
Mar 01, 2026Clinical diagnosis is time-consuming, requiring intensive interactions between patients and medical professionals. While large language models (LLMs) could ease the pre-diagnostic workload, their limited domain knowledge hinders effective medical question generation. We introduce a Knowledge Graph-augmented LLM with active in-context learning to generate relevant and important follow-up questions, KG-Followup, serving as a critical module for the pre-diagnostic assessment. The structured medical domain knowledge graph serves as a seamless patch-up to provide professional domain expertise upon which the LLM can reason. Experiments demonstrate that KG-Followup outperforms state-of-the-art methods by 5% - 8% on relevant benchmarks in recall.
PARA: Parameter-Efficient Fine-tuning with Prompt Aware Representation Adjustment
Feb 03, 2025In the realm of parameter-efficient fine-tuning (PEFT) methods, while options like LoRA are available, there is a persistent demand in the industry for a PEFT approach that excels in both efficiency and performance within the context of single-backbone multi-tenant applications. This paper introduces a new and straightforward PEFT technique, termed \underline{P}rompt \underline{A}ware \underline{R}epresentation \underline{A}djustment (PARA). The core of our proposal is to integrate a lightweight vector generator within each Transformer layer. This generator produces vectors that are responsive to input prompts, thereby adjusting the hidden representations accordingly. Our extensive experimentation across diverse tasks has yielded promising results. Firstly, the PARA method has been shown to surpass current PEFT benchmarks in terms of performance, despite having a similar number of adjustable parameters. Secondly, it has proven to be more efficient than LoRA in the single-backbone multi-tenant scenario, highlighting its significant potential for industrial adoption.
Code Representation Learning At Scale
Feb 02, 2024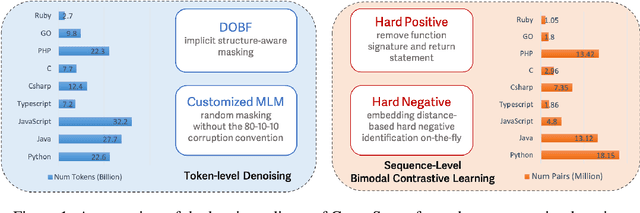
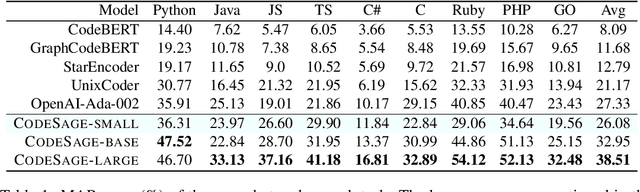
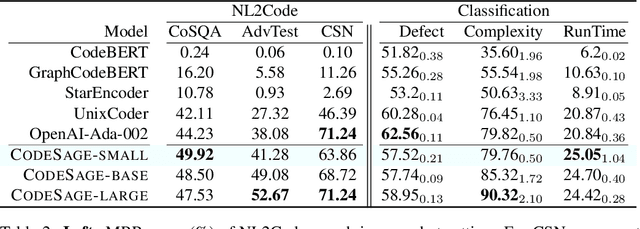
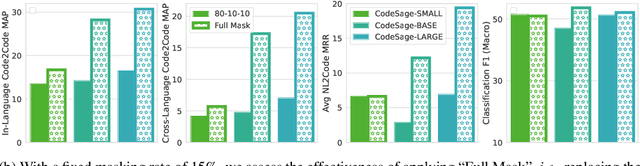
Recent studies have shown that code language models at scale demonstrate significant performance gains on downstream tasks, i.e., code generation. However, most of the existing works on code representation learning train models at a hundred million parameter scale using very limited pretraining corpora. In this work, we fuel code representation learning with a vast amount of code data via a two-stage pretraining scheme. We first train the encoders via a mix that leverages both randomness in masking language modeling and the structure aspect of programming language. We then enhance the representations via contrastive learning with hard negative and hard positive constructed in an unsupervised manner. We establish an off-the-shelf encoder model that persistently outperforms the existing models on a wide variety of downstream tasks by large margins. To comprehend the factors contributing to successful code representation learning, we conduct detailed ablations and share our findings on (i) a customized and effective token-level denoising scheme for source code; (ii) the importance of hard negatives and hard positives; (iii) how the proposed bimodal contrastive learning boost the cross-lingual semantic search performance; and (iv) how the pretraining schemes decide the downstream task performance scales with the model size.
* 10 pages
Improving Prompt Tuning with Learned Prompting Layers
Oct 31, 2023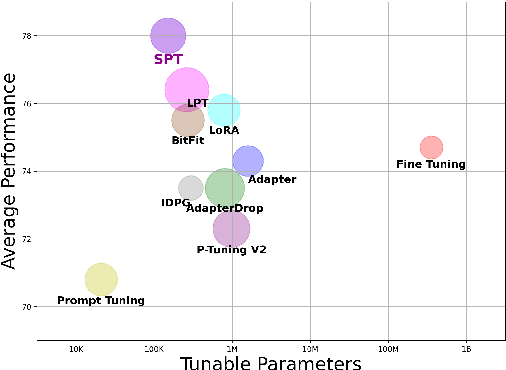
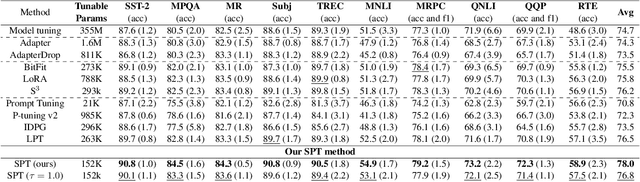
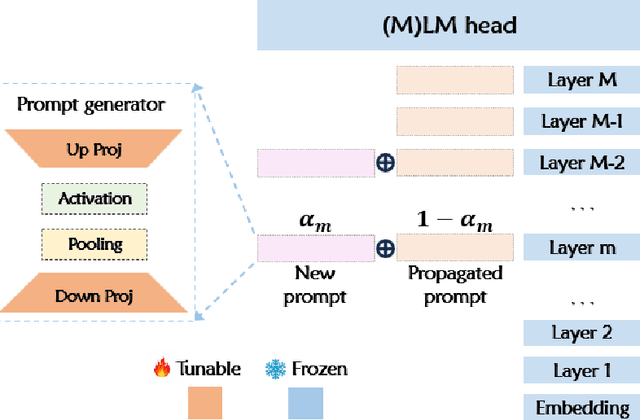
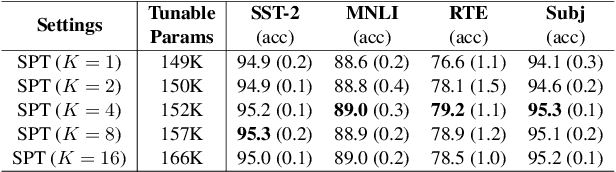
Prompt tuning prepends a soft prompt to the input embeddings or hidden states and only optimizes the prompt to adapt pretrained models (PTMs) to downstream tasks. The previous work manually selects prompt layers which are far from optimal and failed to exploit the potential of prompt tuning. In this work, we propose a novel framework, \underline{S}elective \underline{P}rompt \underline{T}uning (SPT), that learns to select the proper prompt layers by inserting a prompt controlled by a learnable probabilistic gate at each intermediate layer. We further propose a novel bi-level optimization framework, SPT-DARTS, that can better optimize the learnable gates and improve the final prompt tuning performances of the learned prompt layer settings. We conduct extensive experiments with ten benchmark datasets under the full-data and few-shot scenarios. The results demonstrate that our SPT framework can perform better than the previous state-of-the-art PETuning baselines with comparable or fewer tunable parameters.
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Oct 17, 2023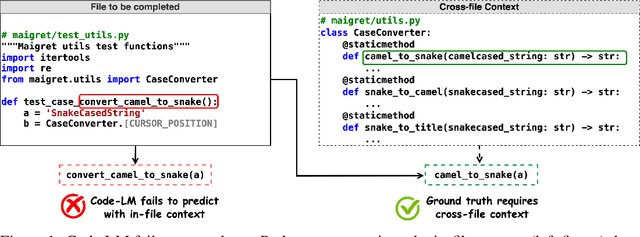
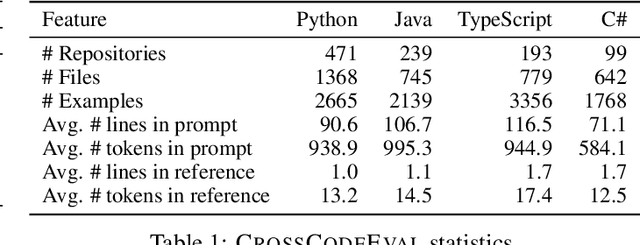
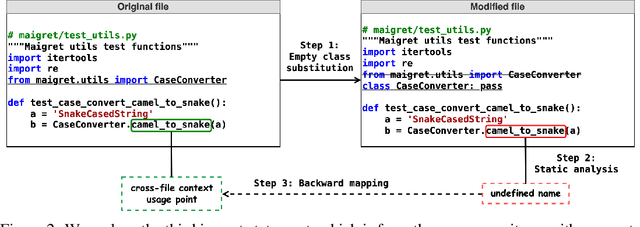
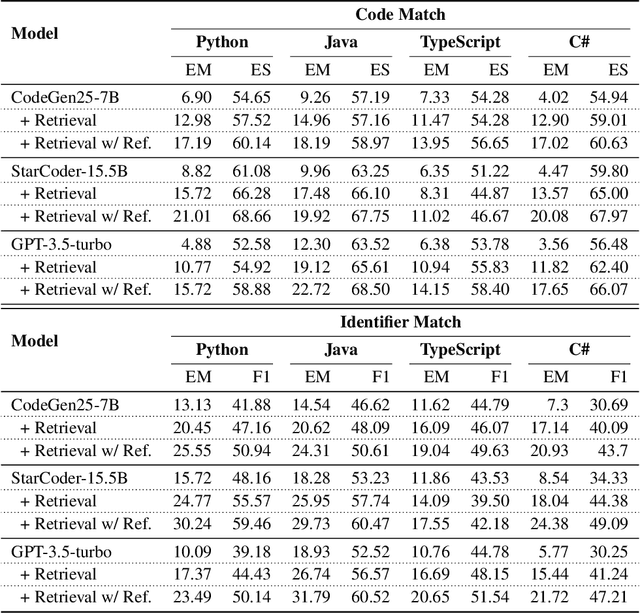
Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is also capable of assessing model's capability in leveraging extensive context to make better code completion. Finally, we benchmarked various methods in retrieving cross-file context, and show that CrossCodeEval can also be used to measure the capability of code retrievers.
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf
Cross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023



A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022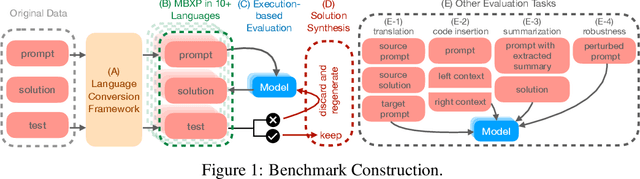
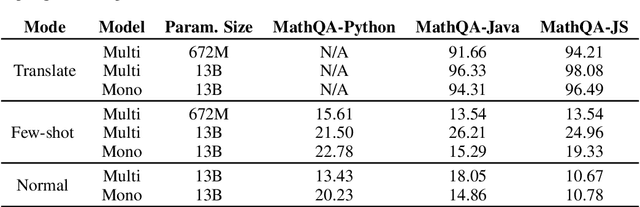


We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022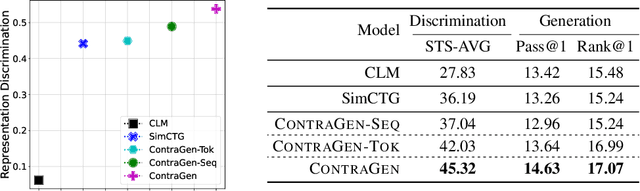
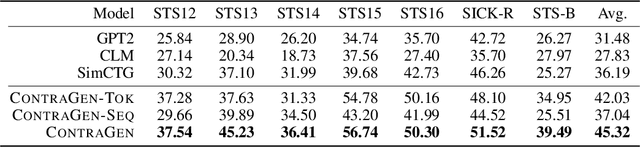
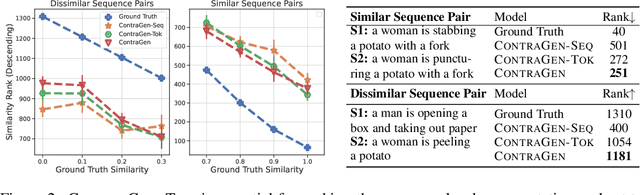
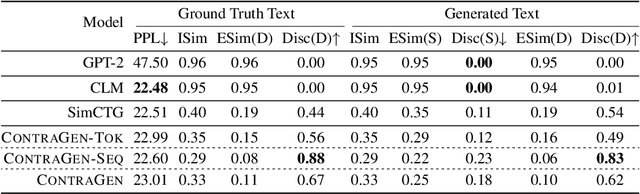
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.