 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023



A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
MsCGAN: Multi-scale Conditional Generative Adversarial Networks for Person Image Generation
Oct 19, 2018
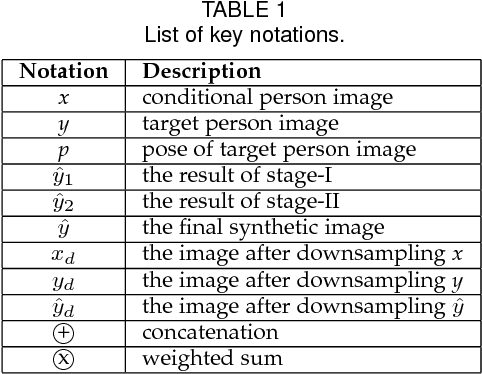
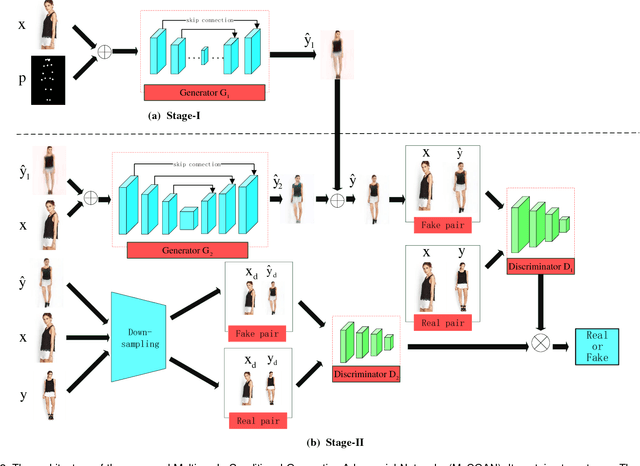
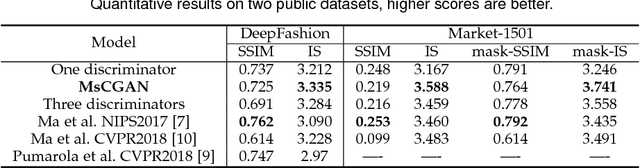
To synthesize high quality person images with arbitrary poses is challenging. In this paper, we propose a novel Multi-scale Conditional Generative Adversarial Networks (MsCGAN), aiming to convert the input conditional person image to a synthetic image of any given target pose, whose appearance and the texture are consistent with the input image. MsCGAN is a multi-scale adversarial network consisting of two generators and two discriminators. One generator transforms the conditional person image into a coarse image of the target pose globally, and the other is to enhance the detailed quality of the synthetic person image through a local reinforcement network. The outputs of the two generators are then merged into a synthetic, discriminant and high-resolution image. On the other hand, the synthetic image is down-sampled to multiple resolutions as the input to multi-scale discriminator networks. The proposed multi-scale generators and discriminators handling different levels of visual features can benefit to synthesizing high resolution person images with realistic appearance and texture. Experiments are conducted on the Market-1501 and DeepFashion datasets to evaluate the proposed model, and both qualitative and quantitative results demonstrate superior performance of the proposed MsCGAN.