 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the ID-Matching Challenge in Long Video Captioning
Oct 08, 2025Generating captions for long and complex videos is both critical and challenging, with significant implications for the growing fields of text-to-video generation and multi-modal understanding. One key challenge in long video captioning is accurately recognizing the same individuals who appear in different frames, which we refer to as the ID-Matching problem. Few prior works have focused on this important issue. Those that have, usually suffer from limited generalization and depend on point-wise matching, which limits their overall effectiveness. In this paper, unlike previous approaches, we build upon LVLMs to leverage their powerful priors. We aim to unlock the inherent ID-Matching capabilities within LVLMs themselves to enhance the ID-Matching performance of captions. Specifically, we first introduce a new benchmark for assessing the ID-Matching capabilities of video captions. Using this benchmark, we investigate LVLMs containing GPT-4o, revealing key insights that the performance of ID-Matching can be improved through two methods: 1) enhancing the usage of image information and 2) increasing the quantity of information of individual descriptions. Based on these insights, we propose a novel video captioning method called Recognizing Identities for Captioning Effectively (RICE). Extensive experiments including assessments of caption quality and ID-Matching performance, demonstrate the superiority of our approach. Notably, when implemented on GPT-4o, our RICE improves the precision of ID-Matching from 50% to 90% and improves the recall of ID-Matching from 15% to 80% compared to baseline. RICE makes it possible to continuously track different individuals in the captions of long videos.
Accelerating Diffusion Sampling via Exploiting Local Transition Coherence
Mar 12, 2025Text-based diffusion models have made significant breakthroughs in generating high-quality images and videos from textual descriptions. However, the lengthy sampling time of the denoising process remains a significant bottleneck in practical applications. Previous methods either ignore the statistical relationships between adjacent steps or rely on attention or feature similarity between them, which often only works with specific network structures. To address this issue, we discover a new statistical relationship in the transition operator between adjacent steps, focusing on the relationship of the outputs from the network. This relationship does not impose any requirements on the network structure. Based on this observation, we propose a novel training-free acceleration method called LTC-Accel, which uses the identified relationship to estimate the current transition operator based on adjacent steps. Due to no specific assumptions regarding the network structure, LTC-Accel is applicable to almost all diffusion-based methods and orthogonal to almost all existing acceleration techniques, making it easy to combine with them. Experimental results demonstrate that LTC-Accel significantly speeds up sampling in text-to-image and text-to-video synthesis while maintaining competitive sample quality. Specifically, LTC-Accel achieves a speedup of 1.67-fold in Stable Diffusion v2 and a speedup of 1.55-fold in video generation models. When combined with distillation models, LTC-Accel achieves a remarkable 10-fold speedup in video generation, allowing real-time generation of more than 16FPS.
BACON: Supercharge Your VLM with Bag-of-Concept Graph to Mitigate Hallucinations
Jul 03, 2024



This paper presents Bag-of-Concept Graph (BACON) to gift models with limited linguistic abilities to taste the privilege of Vision Language Models (VLMs) and boost downstream tasks such as detection, visual question answering (VQA), and image generation. Since the visual scenes in physical worlds are structured with complex relations between objects, BACON breaks down annotations into basic minimum elements and presents them in a graph structure. Element-wise style enables easy understanding, and structural composition liberates difficult locating. Careful prompt design births the BACON captions with the help of public-available VLMs and segmentation methods. In this way, we gather a dataset with 100K annotated images, which endow VLMs with remarkable capabilities, such as accurately generating BACON, transforming prompts into BACON format, envisioning scenarios in the style of BACONr, and dynamically modifying elements within BACON through interactive dialogue and more. Wide representative experiments, including detection, VQA, and image generation tasks, tell BACON as a lifeline to achieve previous out-of-reach tasks or excel in their current cutting-edge solutions.
Eliminating Lipschitz Singularities in Diffusion Models
Jun 20, 2023Diffusion models, which employ stochastic differential equations to sample images through integrals, have emerged as a dominant class of generative models. However, the rationality of the diffusion process itself receives limited attention, leaving the question of whether the problem is well-posed and well-conditioned. In this paper, we uncover a vexing propensity of diffusion models: they frequently exhibit the infinite Lipschitz near the zero point of timesteps. This poses a threat to the stability and accuracy of the diffusion process, which relies on integral operations. We provide a comprehensive evaluation of the issue from both theoretical and empirical perspectives. To address this challenge, we propose a novel approach, dubbed E-TSDM, which eliminates the Lipschitz singularity of the diffusion model near zero. Remarkably, our technique yields a substantial improvement in performance, e.g., on the high-resolution FFHQ dataset ($256\times256$). Moreover, as a byproduct of our method, we manage to achieve a dramatic reduction in the Frechet Inception Distance of other acceleration methods relying on network Lipschitz, including DDIM and DPM-Solver, by over 33$\%$. We conduct extensive experiments on diverse datasets to validate our theory and method. Our work not only advances the understanding of the general diffusion process, but also provides insights for the design of diffusion models.
DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023



A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
Dimensionality-Varying Diffusion Process
Nov 29, 2022



Diffusion models, which learn to reverse a signal destruction process to generate new data, typically require the signal at each step to have the same dimension. We argue that, considering the spatial redundancy in image signals, there is no need to maintain a high dimensionality in the evolution process, especially in the early generation phase. To this end, we make a theoretical generalization of the forward diffusion process via signal decomposition. Concretely, we manage to decompose an image into multiple orthogonal components and control the attenuation of each component when perturbing the image. That way, along with the noise strength increasing, we are able to diminish those inconsequential components and thus use a lower-dimensional signal to represent the source, barely losing information. Such a reformulation allows to vary dimensions in both training and inference of diffusion models. Extensive experiments on a range of datasets suggest that our approach substantially reduces the computational cost and achieves on-par or even better synthesis performance compared to baseline methods. We also show that our strategy facilitates high-resolution image synthesis and improves FID of diffusion model trained on FFHQ at $1024\times1024$ resolution from 52.40 to 10.46. Code and models will be made publicly available.
FORTAP: Using Formulae for Numerical-Reasoning-Aware Table Pretraining
Sep 15, 2021
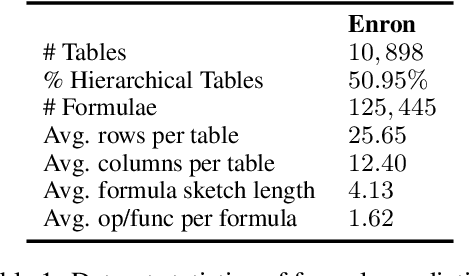
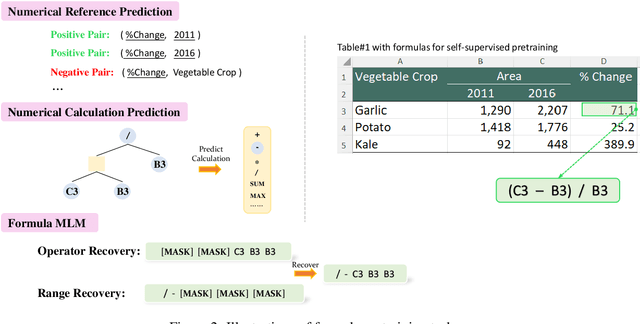
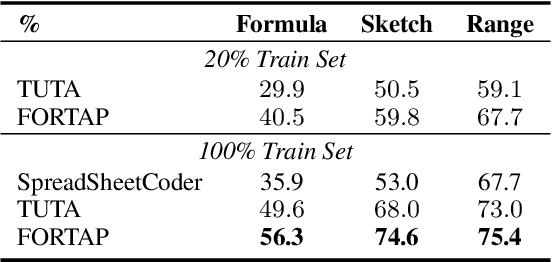
Tables store rich numerical data, but numerical reasoning over tables is still a challenge. In this paper, we find that the spreadsheet formula, which performs calculations on numerical values in tables, is naturally a strong supervision of numerical reasoning. More importantly, large amounts of spreadsheets with expert-made formulae are available on the web and can be obtained easily. FORTAP is the first method for numerical-reasoning-aware table pretraining by leveraging large corpus of spreadsheet formulae. We design two formula pretraining tasks to explicitly guide FORTAP to learn numerical reference and calculation in semi-structured tables. FORTAP achieves state-of-the-art results on two representative downstream tasks, cell type classification and formula prediction, showing great potential of numerical-reasoning-aware pretraining.
Few Shot Learning with Simplex
Oct 30, 2018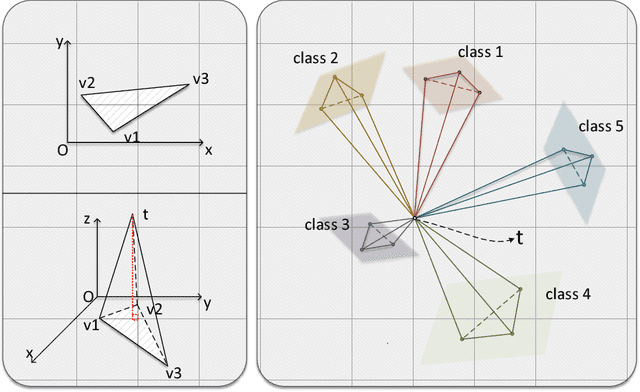

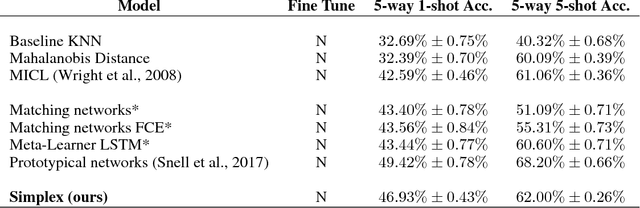
Deep learning has made remarkable achievement in many fields. However, learning the parameters of neural networks usually demands a large amount of labeled data. The algorithms of deep learning, therefore, encounter difficulties when applied to supervised learning where only little data are available. This specific task is called few-shot learning. To address it, we propose a novel algorithm for few-shot learning using discrete geometry, in the sense that the samples in a class are modeled as a reduced simplex. The volume of the simplex is used for the measurement of class scatter. During testing, combined with the test sample and the points in the class, a new simplex is formed. Then the similarity between the test sample and the class can be quantized with the ratio of volumes of the new simplex to the original class simplex. Moreover, we present an approach to constructing simplices using local regions of feature maps yielded by convolutional neural networks. Experiments on Omniglot and miniImageNet verify the effectiveness of our simplex algorithm on few-shot learning.