 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Carefully: Adaptive Visual Reinforcements in Multimodal Large Language Models for Hallucination Mitigation
Feb 27, 2026Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language reasoning, yet they remain vulnerable to hallucination, where generated content deviates from visual evidence. Existing mitigation strategies either require costly supervision during training or introduce additional latency at inference time. Recent vision enhancement methods attempt to address this issue by reinforcing visual tokens during decoding, but they typically inject all tokens indiscriminately, which causes interference from background regions and distracts the model from critical cues. To overcome this challenge, we propose Adaptive Visual Reinforcement (AIR), a training-free framework for MLLMs. AIR consists of two components. Prototype-based token reduction condenses the large pool of visual tokens into a compact subset to suppress redundancy. OT-guided patch reinforcement quantifies the alignment between hidden states and patch embeddings to selectively integrate the most consistent patches into feed-forward layers. As a result, AIR enhances the model's reliance on salient visual information and effectively mitigates hallucination. Extensive experiments across representative MLLMs demonstrate that AIR substantially reduces hallucination while preserving general capabilities, establishing it as an effective solution for building reliable MLLMs.
Causal-HalBench: Uncovering LVLMs Object Hallucinations Through Causal Intervention
Nov 13, 2025Large Vision-Language Models (LVLMs) often suffer from object hallucination, making erroneous judgments about the presence of objects in images. We propose this primar- ily stems from spurious correlations arising when models strongly associate highly co-occurring objects during train- ing, leading to hallucinated objects influenced by visual con- text. Current benchmarks mainly focus on hallucination de- tection but lack a formal characterization and quantitative evaluation of spurious correlations in LVLMs. To address this, we introduce causal analysis into the object recognition scenario of LVLMs, establishing a Structural Causal Model (SCM). Utilizing the language of causality, we formally de- fine spurious correlations arising from co-occurrence bias. To quantify the influence induced by these spurious correla- tions, we develop Causal-HalBench, a benchmark specifically constructed with counterfactual samples and integrated with comprehensive causal metrics designed to assess model ro- bustness against spurious correlations. Concurrently, we pro- pose an extensible pipeline for the construction of these coun- terfactual samples, leveraging the capabilities of proprietary LVLMs and Text-to-Image (T2I) models for their genera- tion. Our evaluations on mainstream LVLMs using Causal- HalBench demonstrate these models exhibit susceptibility to spurious correlations, albeit to varying extents.
UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
Model Inversion Attacks Through Target-Specific Conditional Diffusion Models
Jul 16, 2024Model inversion attacks (MIAs) aim to reconstruct private images from a target classifier's training set, thereby raising privacy concerns in AI applications. Previous GAN-based MIAs tend to suffer from inferior generative fidelity due to GAN's inherent flaws and biased optimization within latent space. To alleviate these issues, leveraging on diffusion models' remarkable synthesis capabilities, we propose Diffusion-based Model Inversion (Diff-MI) attacks. Specifically, we introduce a novel target-specific conditional diffusion model (CDM) to purposely approximate target classifier's private distribution and achieve superior accuracy-fidelity balance. Our method involves a two-step learning paradigm. Step-1 incorporates the target classifier into the entire CDM learning under a pretrain-then-finetune fashion, with creating pseudo-labels as model conditions in pretraining and adjusting specified layers with image predictions in fine-tuning. Step-2 presents an iterative image reconstruction method, further enhancing the attack performance through a combination of diffusion priors and target knowledge. Additionally, we propose an improved max-margin loss that replaces the hard max with top-k maxes, fully leveraging feature information and soft labels from the target classifier. Extensive experiments demonstrate that Diff-MI significantly improves generative fidelity with an average decrease of 20% in FID while maintaining competitive attack accuracy compared to state-of-the-art methods across various datasets and models. We will release our code and models.
BACON: Supercharge Your VLM with Bag-of-Concept Graph to Mitigate Hallucinations
Jul 03, 2024



This paper presents Bag-of-Concept Graph (BACON) to gift models with limited linguistic abilities to taste the privilege of Vision Language Models (VLMs) and boost downstream tasks such as detection, visual question answering (VQA), and image generation. Since the visual scenes in physical worlds are structured with complex relations between objects, BACON breaks down annotations into basic minimum elements and presents them in a graph structure. Element-wise style enables easy understanding, and structural composition liberates difficult locating. Careful prompt design births the BACON captions with the help of public-available VLMs and segmentation methods. In this way, we gather a dataset with 100K annotated images, which endow VLMs with remarkable capabilities, such as accurately generating BACON, transforming prompts into BACON format, envisioning scenarios in the style of BACONr, and dynamically modifying elements within BACON through interactive dialogue and more. Wide representative experiments, including detection, VQA, and image generation tasks, tell BACON as a lifeline to achieve previous out-of-reach tasks or excel in their current cutting-edge solutions.
PosMLP-Video: Spatial and Temporal Relative Position Encoding for Efficient Video Recognition
Jul 03, 2024In recent years, vision Transformers and MLPs have demonstrated remarkable performance in image understanding tasks. However, their inherently dense computational operators, such as self-attention and token-mixing layers, pose significant challenges when applied to spatio-temporal video data. To address this gap, we propose PosMLP-Video, a lightweight yet powerful MLP-like backbone for video recognition. Instead of dense operators, we use efficient relative positional encoding (RPE) to build pairwise token relations, leveraging small-sized parameterized relative position biases to obtain each relation score. Specifically, to enable spatio-temporal modeling, we extend the image PosMLP's positional gating unit to temporal, spatial, and spatio-temporal variants, namely PoTGU, PoSGU, and PoSTGU, respectively. These gating units can be feasibly combined into three types of spatio-temporal factorized positional MLP blocks, which not only decrease model complexity but also maintain good performance. Additionally, we enrich relative positional relationships by using channel grouping. Experimental results on three video-related tasks demonstrate that PosMLP-Video achieves competitive speed-accuracy trade-offs compared to the previous state-of-the-art models. In particular, PosMLP-Video pre-trained on ImageNet1K achieves 59.0%/70.3% top-1 accuracy on Something-Something V1/V2 and 82.1% top-1 accuracy on Kinetics-400 while requiring much fewer parameters and FLOPs than other models. The code is released at https://github.com/zhouds1918/PosMLP_Video.
Enhance Image Classification via Inter-Class Image Mixup with Diffusion Model
Mar 28, 2024



Text-to-image (T2I) generative models have recently emerged as a powerful tool, enabling the creation of photo-realistic images and giving rise to a multitude of applications. However, the effective integration of T2I models into fundamental image classification tasks remains an open question. A prevalent strategy to bolster image classification performance is through augmenting the training set with synthetic images generated by T2I models. In this study, we scrutinize the shortcomings of both current generative and conventional data augmentation techniques. Our analysis reveals that these methods struggle to produce images that are both faithful (in terms of foreground objects) and diverse (in terms of background contexts) for domain-specific concepts. To tackle this challenge, we introduce an innovative inter-class data augmentation method known as Diff-Mix (https://github.com/Zhicaiwww/Diff-Mix), which enriches the dataset by performing image translations between classes. Our empirical results demonstrate that Diff-Mix achieves a better balance between faithfulness and diversity, leading to a marked improvement in performance across diverse image classification scenarios, including few-shot, conventional, and long-tail classifications for domain-specific datasets.
DiffsFormer: A Diffusion Transformer on Stock Factor Augmentation
Feb 05, 2024



Machine learning models have demonstrated remarkable efficacy and efficiency in a wide range of stock forecasting tasks. However, the inherent challenges of data scarcity, including low signal-to-noise ratio (SNR) and data homogeneity, pose significant obstacles to accurate forecasting. To address this issue, we propose a novel approach that utilizes artificial intelligence-generated samples (AIGS) to enhance the training procedures. In our work, we introduce the Diffusion Model to generate stock factors with Transformer architecture (DiffsFormer). DiffsFormer is initially trained on a large-scale source domain, incorporating conditional guidance so as to capture global joint distribution. When presented with a specific downstream task, we employ DiffsFormer to augment the training procedure by editing existing samples. This editing step allows us to control the strength of the editing process, determining the extent to which the generated data deviates from the target domain. To evaluate the effectiveness of DiffsFormer augmented training, we conduct experiments on the CSI300 and CSI800 datasets, employing eight commonly used machine learning models. The proposed method achieves relative improvements of 7.2% and 27.8% in annualized return ratio for the respective datasets. Furthermore, we perform extensive experiments to gain insights into the functionality of DiffsFormer and its constituent components, elucidating how they address the challenges of data scarcity and enhance the overall model performance. Our research demonstrates the efficacy of leveraging AIGS and the DiffsFormer architecture to mitigate data scarcity in stock forecasting tasks.
Generate What You Prefer: Reshaping Sequential Recommendation via Guided Diffusion
Oct 31, 2023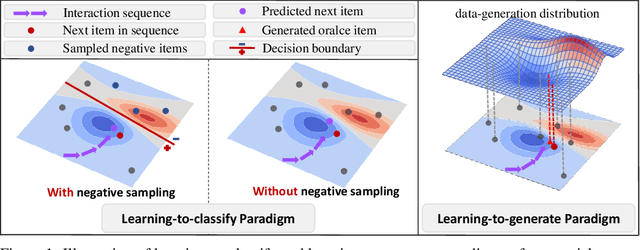



Sequential recommendation aims to recommend the next item that matches a user's interest, based on the sequence of items he/she interacted with before. Scrutinizing previous studies, we can summarize a common learning-to-classify paradigm -- given a positive item, a recommender model performs negative sampling to add negative items and learns to classify whether the user prefers them or not, based on his/her historical interaction sequence. Although effective, we reveal two inherent limitations:(1) it may differ from human behavior in that a user could imagine an oracle item in mind and select potential items matching the oracle; and (2) the classification is limited in the candidate pool with noisy or easy supervision from negative samples, which dilutes the preference signals towards the oracle item. Yet, generating the oracle item from the historical interaction sequence is mostly unexplored. To bridge the gap, we reshape sequential recommendation as a learning-to-generate paradigm, which is achieved via a guided diffusion model, termed DreamRec.Specifically, for a sequence of historical items, it applies a Transformer encoder to create guidance representations. Noising target items explores the underlying distribution of item space; then, with the guidance of historical interactions, the denoising process generates an oracle item to recover the positive item, so as to cast off negative sampling and depict the true preference of the user directly. We evaluate the effectiveness of DreamRec through extensive experiments and comparisons with existing methods. Codes and data are open-sourced at https://github.com/YangZhengyi98/DreamRec.
Bi-directional Distribution Alignment for Transductive Zero-Shot Learning
Mar 19, 2023


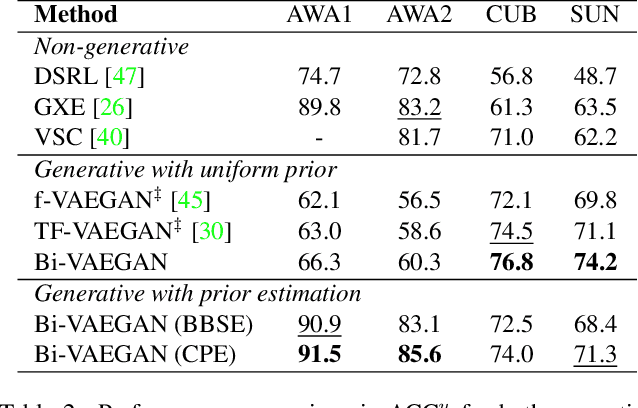
It is well-known that zero-shot learning (ZSL) can suffer severely from the problem of domain shift, where the true and learned data distributions for the unseen classes do not match. Although transductive ZSL (TZSL) attempts to improve this by allowing the use of unlabelled examples from the unseen classes, there is still a high level of distribution shift. We propose a novel TZSL model (named as Bi-VAEGAN), which largely improves the shift by a strengthened distribution alignment between the visual and auxiliary spaces. The key proposal of the model design includes (1) a bi-directional distribution alignment, (2) a simple but effective L_2-norm based feature normalization approach, and (3) a more sophisticated unseen class prior estimation approach. In benchmark evaluation using four datasets, Bi-VAEGAN achieves the new state of the arts under both the standard and generalized TZSL settings. Code could be found at https://github.com/Zhicaiwww/Bi-VAEGAN