 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Analysis: A Benchmark of Table Question Answering with Advanced Data Analysis and Unclear Queries
Dec 21, 2023Tabular data analysis is crucial in various fields, and large language models show promise in this area. However, current research mostly focuses on rudimentary tasks like Text2SQL and TableQA, neglecting advanced analysis like forecasting and chart generation. To address this gap, we developed the Text2Analysis benchmark, incorporating advanced analysis tasks that go beyond the SQL-compatible operations and require more in-depth analysis. We also develop five innovative and effective annotation methods, harnessing the capabilities of large language models to enhance data quality and quantity. Additionally, we include unclear queries that resemble real-world user questions to test how well models can understand and tackle such challenges. Finally, we collect 2249 query-result pairs with 347 tables. We evaluate five state-of-the-art models using three different metrics and the results show that our benchmark presents introduces considerable challenge in the field of tabular data analysis, paving the way for more advanced research opportunities.
FORTAP: Using Formulae for Numerical-Reasoning-Aware Table Pretraining
Sep 15, 2021
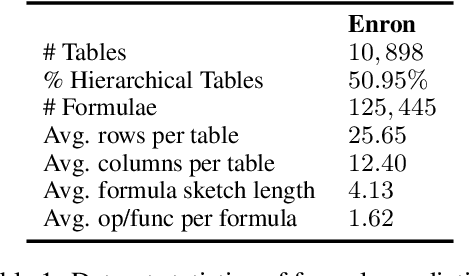
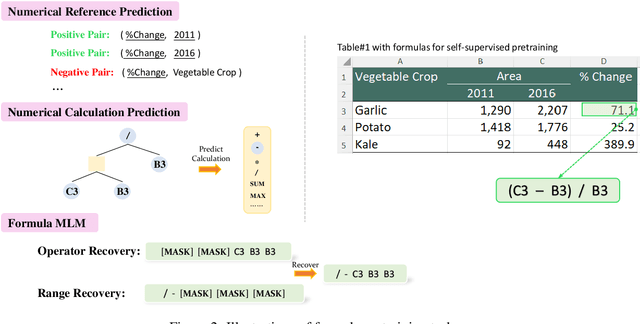
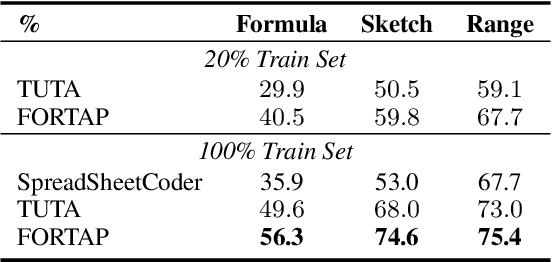
Tables store rich numerical data, but numerical reasoning over tables is still a challenge. In this paper, we find that the spreadsheet formula, which performs calculations on numerical values in tables, is naturally a strong supervision of numerical reasoning. More importantly, large amounts of spreadsheets with expert-made formulae are available on the web and can be obtained easily. FORTAP is the first method for numerical-reasoning-aware table pretraining by leveraging large corpus of spreadsheet formulae. We design two formula pretraining tasks to explicitly guide FORTAP to learn numerical reference and calculation in semi-structured tables. FORTAP achieves state-of-the-art results on two representative downstream tasks, cell type classification and formula prediction, showing great potential of numerical-reasoning-aware pretraining.
HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation
Aug 30, 2021
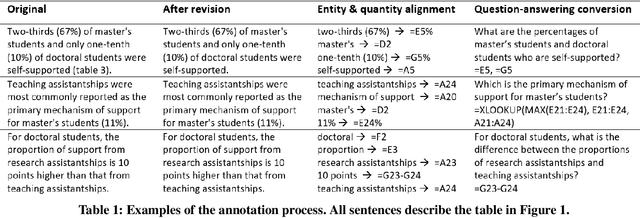


Tables are often created with hierarchies, but existing works on table reasoning mainly focus on flat tables and neglect hierarchical tables. Hierarchical tables challenge existing methods by hierarchical indexing, as well as implicit relationships of calculation and semantics. This work presents HiTab, a free and open dataset to study question answering (QA) and natural language generation (NLG) over hierarchical tables. HiTab is a cross-domain dataset constructed from a wealth of statistical reports (analyses) and Wikipedia pages, and has unique characteristics: (1) nearly all tables are hierarchical, and (2) both target sentences for NLG and questions for QA are revised from original, meaningful, and diverse descriptive sentences authored by analysts and professions of reports. (3) to reveal complex numerical reasoning in statistical analyses, we provide fine-grained annotations of entity and quantity alignment. HiTab provides 10,686 QA pairs and descriptive sentences with well-annotated quantity and entity alignment on 3,597 tables with broad coverage of table hierarchies and numerical reasoning types. Targeting hierarchical structure, we devise a novel hierarchy-aware logical form for symbolic reasoning over tables, which shows high effectiveness. Targeting complex numerical reasoning, we propose partially supervised training given annotations of entity and quantity alignment, which helps models to largely reduce spurious predictions in the QA task. In the NLG task, we find that entity and quantity alignment also helps NLG models to generate better results in a conditional generation setting. Experiment results of state-of-the-art baselines suggest that this dataset presents a strong challenge and a valuable benchmark for future research.
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data
Jun 16, 2021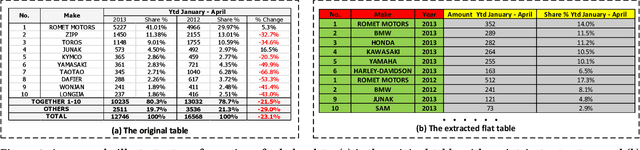
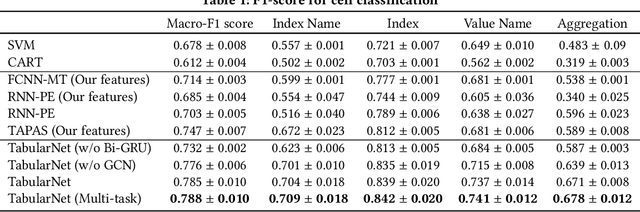
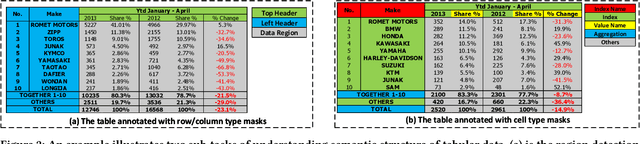
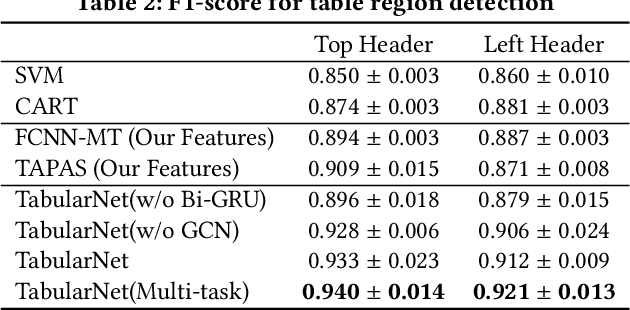
Tabular data are ubiquitous for the widespread applications of tables and hence have attracted the attention of researchers to extract underlying information. One of the critical problems in mining tabular data is how to understand their inherent semantic structures automatically. Existing studies typically adopt Convolutional Neural Network (CNN) to model the spatial information of tabular structures yet ignore more diverse relational information between cells, such as the hierarchical and paratactic relationships. To simultaneously extract spatial and relational information from tables, we propose a novel neural network architecture, TabularNet. The spatial encoder of TabularNet utilizes the row/column-level Pooling and the Bidirectional Gated Recurrent Unit (Bi-GRU) to capture statistical information and local positional correlation, respectively. For relational information, we design a new graph construction method based on the WordNet tree and adopt a Graph Convolutional Network (GCN) based encoder that focuses on the hierarchical and paratactic relationships between cells. Our neural network architecture can be a unified neural backbone for different understanding tasks and utilized in a multitask scenario. We conduct extensive experiments on three classification tasks with two real-world spreadsheet data sets, and the results demonstrate the effectiveness of our proposed TabularNet over state-of-the-art baselines.
Structure-aware Pre-training for Table Understanding with Tree-based Transformers
Nov 06, 2020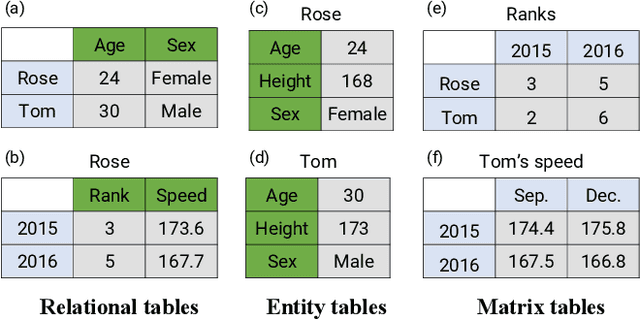
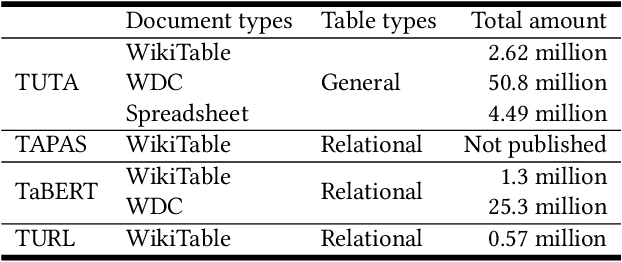
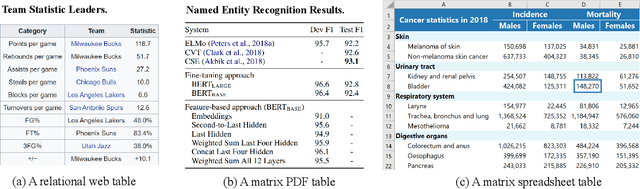

Tables are widely used with various structures to organize and present data. Recent attempts on table understanding mainly focus on relational tables, yet overlook to other common table structures. In this paper, we propose TUTA, a unified pre-training architecture for understanding generally structured tables. Since understanding a table needs to leverage both spatial, hierarchical, and semantic information, we adapt the self-attention strategy with several key structure-aware mechanisms. First, we propose a novel tree-based structure called a bi-dimensional coordinate tree, to describe both the spatial and hierarchical information in tables. Upon this, we extend the pre-training architecture with two core mechanisms, namely the tree-based attention and tree-based position embedding. Moreover, to capture table information in a progressive manner, we devise three pre-training objectives to enable representations at the token, cell, and table levels. TUTA pre-trains on a wide range of unlabeled tables and fine-tunes on a critical task in the field of table structure understanding, i.e. cell type classification. Experiment results show that TUTA is highly effective, achieving state-of-the-art on four well-annotated cell type classification datasets.
Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation
Oct 13, 2016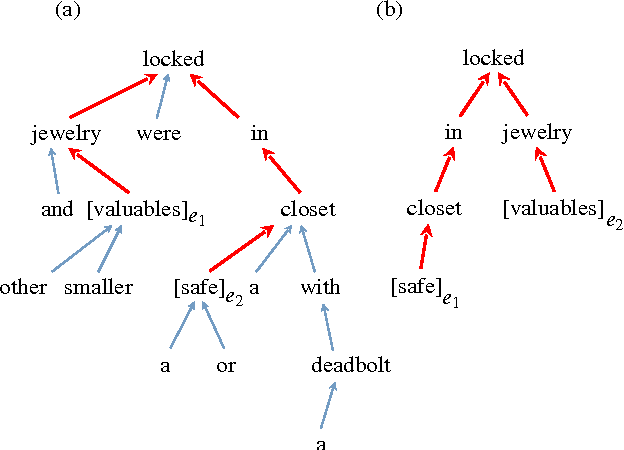
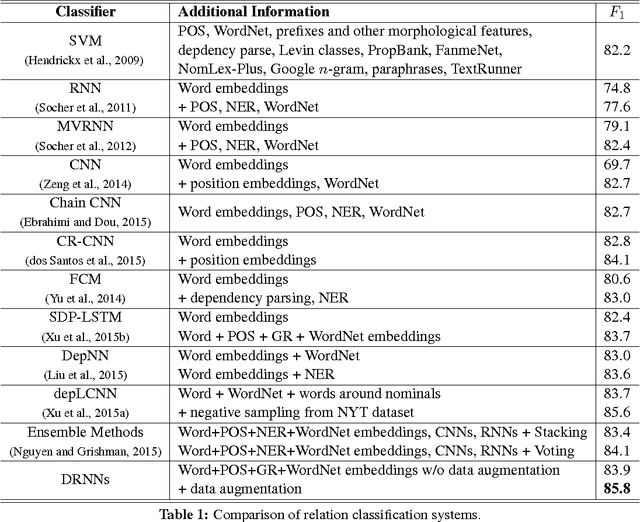
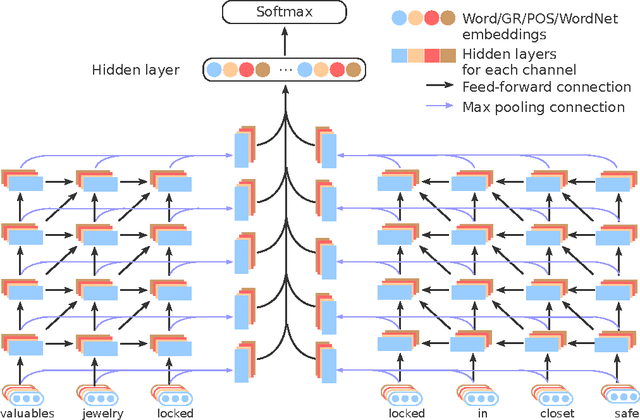
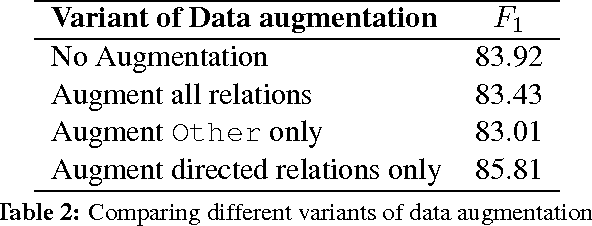
Nowadays, neural networks play an important role in the task of relation classification. By designing different neural architectures, researchers have improved the performance to a large extent in comparison with traditional methods. However, existing neural networks for relation classification are usually of shallow architectures (e.g., one-layer convolutional neural networks or recurrent networks). They may fail to explore the potential representation space in different abstraction levels. In this paper, we propose deep recurrent neural networks (DRNNs) for relation classification to tackle this challenge. Further, we propose a data augmentation method by leveraging the directionality of relations. We evaluated our DRNNs on the SemEval-2010 Task~8, and achieve an F1-score of 86.1%, outperforming previous state-of-the-art recorded results.
Distilling Word Embeddings: An Encoding Approach
Jul 24, 2016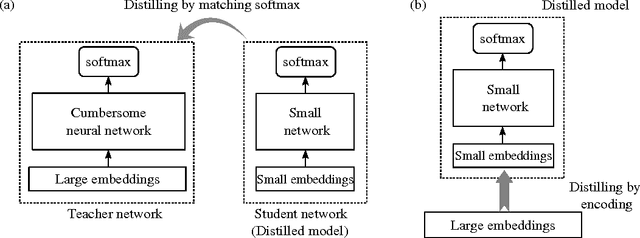
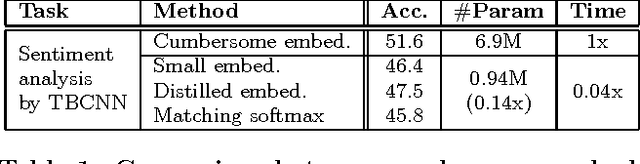

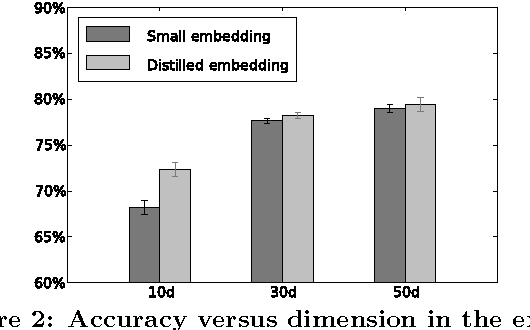
Distilling knowledge from a well-trained cumbersome network to a small one has recently become a new research topic, as lightweight neural networks with high performance are particularly in need in various resource-restricted systems. This paper addresses the problem of distilling word embeddings for NLP tasks. We propose an encoding approach to distill task-specific knowledge from a set of high-dimensional embeddings, which can reduce model complexity by a large margin as well as retain high accuracy, showing a good compromise between efficiency and performance. Experiments in two tasks reveal the phenomenon that distilling knowledge from cumbersome embeddings is better than directly training neural networks with small embeddings.