 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Identification and Segmentation of Hi Sources in CRAFTS Using Deep Learning Method
Mar 29, 2024



We introduce a machine learning-based method for extracting HI sources from 3D spectral data, and construct a dedicated dataset of HI sources from CRAFTS. Our custom dataset provides comprehensive resources for HI source detection. Utilizing the 3D-Unet segmentation architecture, our method reliably identifies and segments HI sources, achieving notable performance metrics with recall rates reaching 91.6% and accuracy levels at 95.7%. These outcomes substantiate the value of our custom dataset and the efficacy of our proposed network in identifying HI source. Our code is publicly available at https://github.com/fishszh/HISF.
Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation
Oct 13, 2016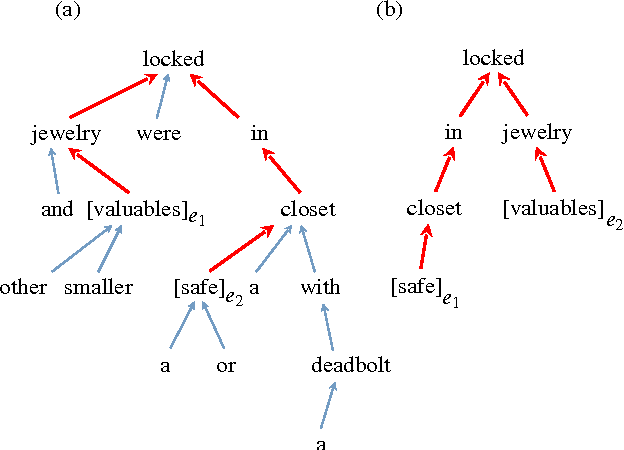
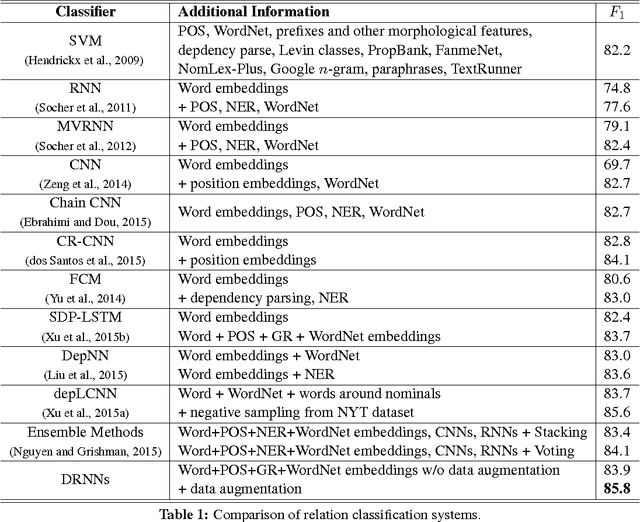
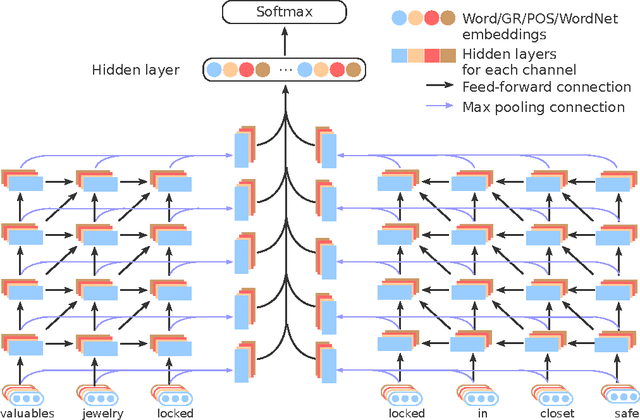
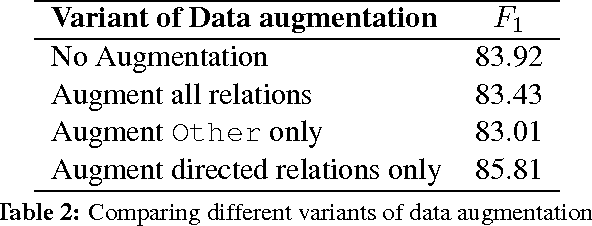
Nowadays, neural networks play an important role in the task of relation classification. By designing different neural architectures, researchers have improved the performance to a large extent in comparison with traditional methods. However, existing neural networks for relation classification are usually of shallow architectures (e.g., one-layer convolutional neural networks or recurrent networks). They may fail to explore the potential representation space in different abstraction levels. In this paper, we propose deep recurrent neural networks (DRNNs) for relation classification to tackle this challenge. Further, we propose a data augmentation method by leveraging the directionality of relations. We evaluated our DRNNs on the SemEval-2010 Task~8, and achieve an F1-score of 86.1%, outperforming previous state-of-the-art recorded results.
Compressing Neural Language Models by Sparse Word Representations
Oct 13, 2016
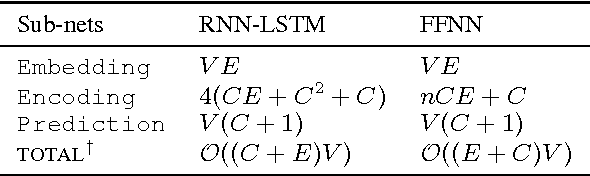
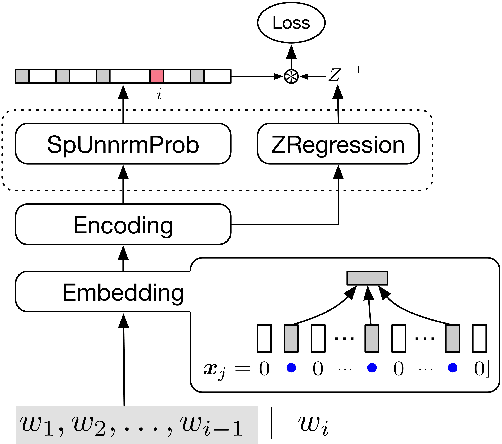

Neural networks are among the state-of-the-art techniques for language modeling. Existing neural language models typically map discrete words to distributed, dense vector representations. After information processing of the preceding context words by hidden layers, an output layer estimates the probability of the next word. Such approaches are time- and memory-intensive because of the large numbers of parameters for word embeddings and the output layer. In this paper, we propose to compress neural language models by sparse word representations. In the experiments, the number of parameters in our model increases very slowly with the growth of the vocabulary size, which is almost imperceptible. Moreover, our approach not only reduces the parameter space to a large extent, but also improves the performance in terms of the perplexity measure.
A Comparative Study on Regularization Strategies for Embedding-based Neural Networks
Aug 15, 2015


This paper aims to compare different regularization strategies to address a common phenomenon, severe overfitting, in embedding-based neural networks for NLP. We chose two widely studied neural models and tasks as our testbed. We tried several frequently applied or newly proposed regularization strategies, including penalizing weights (embeddings excluded), penalizing embeddings, re-embedding words, and dropout. We also emphasized on incremental hyperparameter tuning, and combining different regularizations. The results provide a picture on tuning hyperparameters for neural NLP models.
Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Path
Aug 15, 2015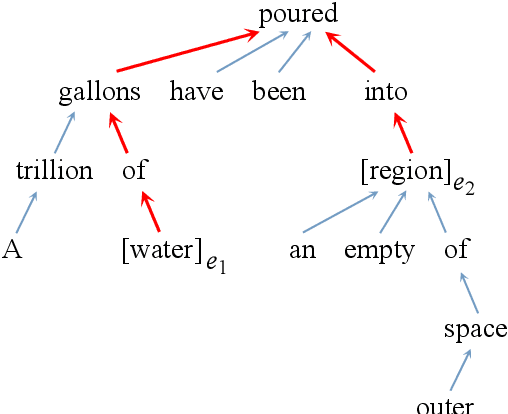
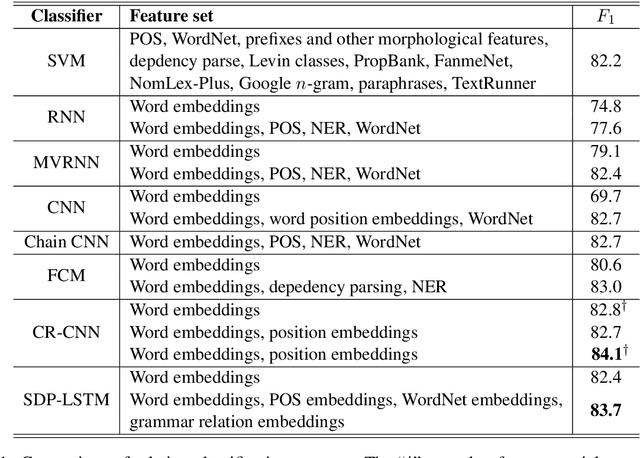
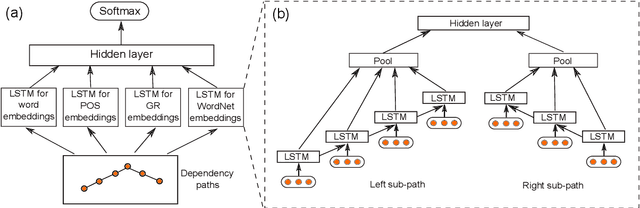

Relation classification is an important research arena in the field of natural language processing (NLP). In this paper, we present SDP-LSTM, a novel neural network to classify the relation of two entities in a sentence. Our neural architecture leverages the shortest dependency path (SDP) between two entities; multichannel recurrent neural networks, with long short term memory (LSTM) units, pick up heterogeneous information along the SDP. Our proposed model has several distinct features: (1) The shortest dependency paths retain most relevant information (to relation classification), while eliminating irrelevant words in the sentence. (2) The multichannel LSTM networks allow effective information integration from heterogeneous sources over the dependency paths. (3) A customized dropout strategy regularizes the neural network to alleviate overfitting. We test our model on the SemEval 2010 relation classification task, and achieve an $F_1$-score of 83.7\%, higher than competing methods in the literature.