 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMCAD: Adaptive Mixed-Curvature Representation based Advertisement Retrieval System
Mar 28, 2022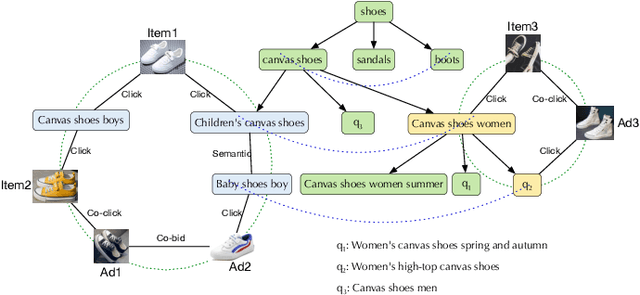
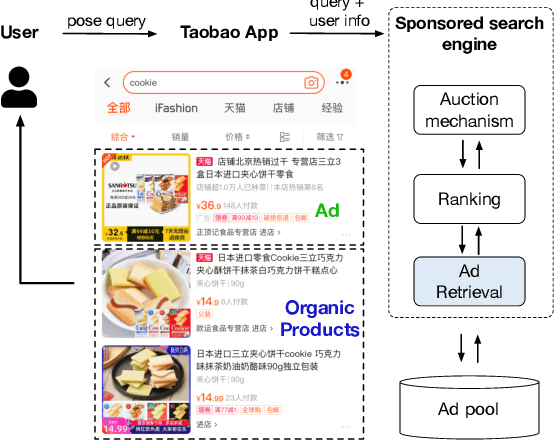
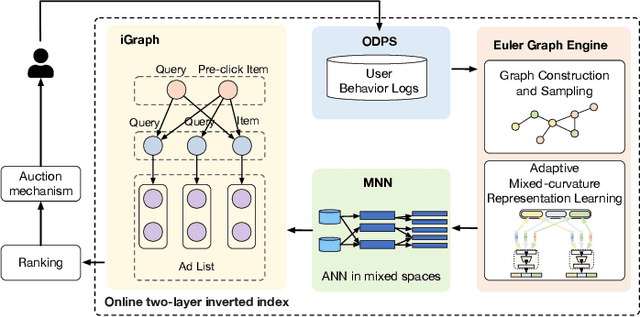
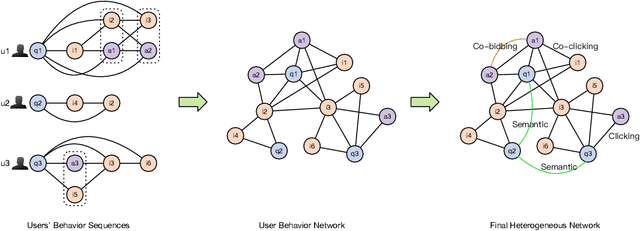
Graph embedding based retrieval has become one of the most popular techniques in the information retrieval community and search engine industry. The classical paradigm mainly relies on the flat Euclidean geometry. In recent years, hyperbolic (negative curvature) and spherical (positive curvature) representation methods have shown their superiority to capture hierarchical and cyclic data structures respectively. However, in industrial scenarios such as e-commerce sponsored search platforms, the large-scale heterogeneous query-item-advertisement interaction graphs often have multiple structures coexisting. Existing methods either only consider a single geometry space, or combine several spaces manually, which are incapable and inflexible to model the complexity and heterogeneity in the real scenario. To tackle this challenge, we present a web-scale Adaptive Mixed-Curvature ADvertisement retrieval system (AMCAD) to automatically capture the complex and heterogeneous graph structures in non-Euclidean spaces. Specifically, entities are represented in adaptive mixed-curvature spaces, where the types and curvatures of the subspaces are trained to be optimal combinations. Besides, an attentive edge-wise space projector is designed to model the similarities between heterogeneous nodes according to local graph structures and the relation types. Moreover, to deploy AMCAD in Taobao, one of the largest ecommerce platforms with hundreds of million users, we design an efficient two-layer online retrieval framework for the task of graph based advertisement retrieval. Extensive evaluations on real-world datasets and A/B tests on online traffic are conducted to illustrate the effectiveness of the proposed system.
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data
Jun 16, 2021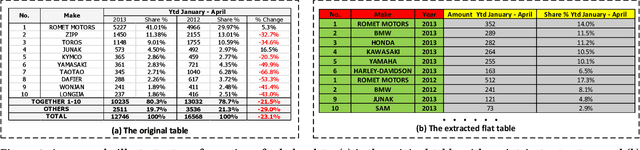
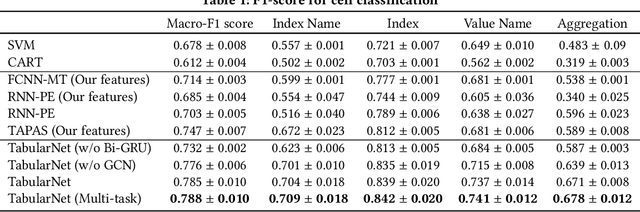
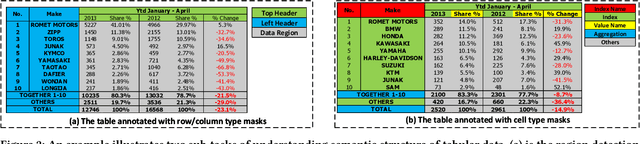
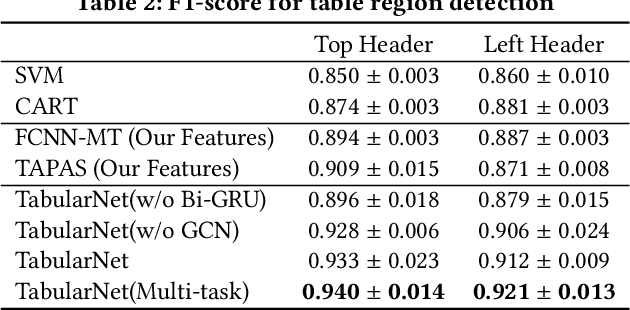
Tabular data are ubiquitous for the widespread applications of tables and hence have attracted the attention of researchers to extract underlying information. One of the critical problems in mining tabular data is how to understand their inherent semantic structures automatically. Existing studies typically adopt Convolutional Neural Network (CNN) to model the spatial information of tabular structures yet ignore more diverse relational information between cells, such as the hierarchical and paratactic relationships. To simultaneously extract spatial and relational information from tables, we propose a novel neural network architecture, TabularNet. The spatial encoder of TabularNet utilizes the row/column-level Pooling and the Bidirectional Gated Recurrent Unit (Bi-GRU) to capture statistical information and local positional correlation, respectively. For relational information, we design a new graph construction method based on the WordNet tree and adopt a Graph Convolutional Network (GCN) based encoder that focuses on the hierarchical and paratactic relationships between cells. Our neural network architecture can be a unified neural backbone for different understanding tasks and utilized in a multitask scenario. We conduct extensive experiments on three classification tasks with two real-world spreadsheet data sets, and the results demonstrate the effectiveness of our proposed TabularNet over state-of-the-art baselines.
TrafficStream: A Streaming Traffic Flow Forecasting Framework Based on Graph Neural Networks and Continual Learning
Jun 11, 2021
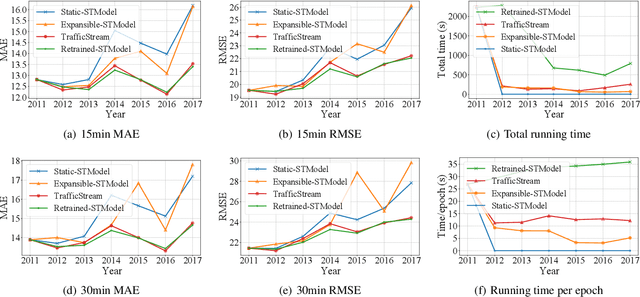
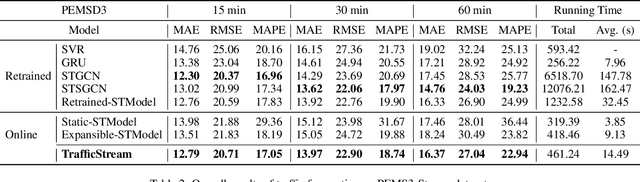
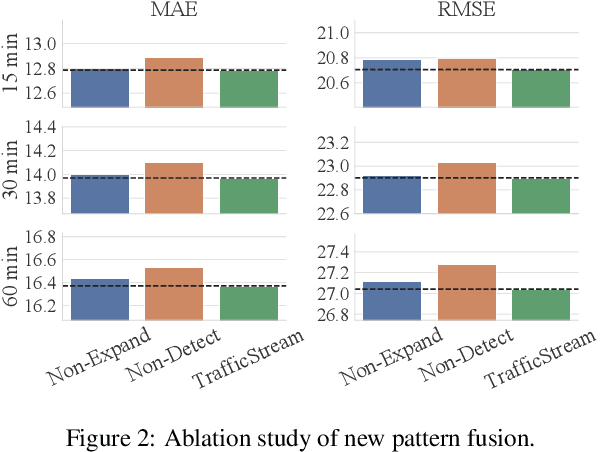
With the rapid growth of traffic sensors deployed, a massive amount of traffic flow data are collected, revealing the long-term evolution of traffic flows and the gradual expansion of traffic networks. How to accurately forecasting these traffic flow attracts the attention of researchers as it is of great significance for improving the efficiency of transportation systems. However, existing methods mainly focus on the spatial-temporal correlation of static networks, leaving the problem of efficiently learning models on networks with expansion and evolving patterns less studied. To tackle this problem, we propose a Streaming Traffic Flow Forecasting Framework, TrafficStream, based on Graph Neural Networks (GNNs) and Continual Learning (CL), achieving accurate predictions and high efficiency. Firstly, we design a traffic pattern fusion method, cleverly integrating the new patterns that emerged during the long-term period into the model. A JS-divergence-based algorithm is proposed to mine new traffic patterns. Secondly, we introduce CL to consolidate the knowledge learned previously and transfer them to the current model. Specifically, we adopt two strategies: historical data replay and parameter smoothing. We construct a streaming traffic dataset to verify the efficiency and effectiveness of our model. Extensive experiments demonstrate its excellent potential to extract traffic patterns with high efficiency on long-term streaming network scene. The source code is available at https://github.com/AprLie/TrafficStream.
Learning Node Representations from Noisy Graph Structures
Dec 04, 2020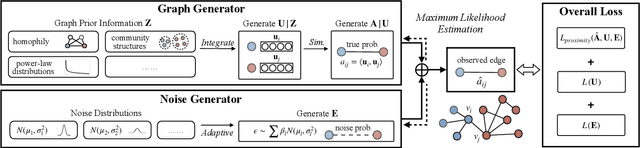
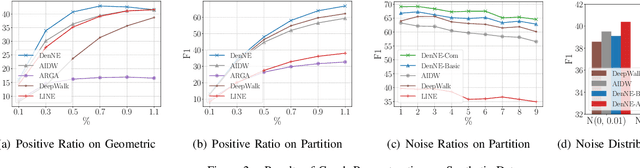
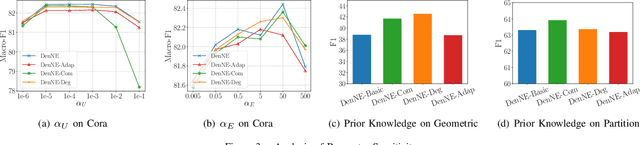
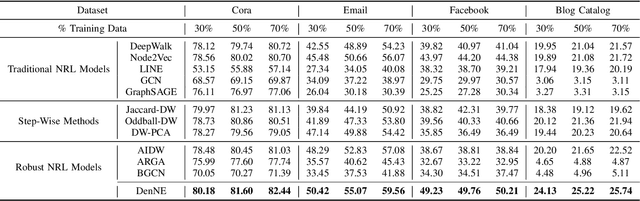
Learning low-dimensional representations on graphs has proved to be effective in various downstream tasks. However, noises prevail in real-world networks, which compromise networks to a large extent in that edges in networks propagate noises through the whole network instead of only the node itself. While existing methods tend to focus on preserving structural properties, the robustness of the learned representations against noises is generally ignored. In this paper, we propose a novel framework to learn noise-free node representations and eliminate noises simultaneously. Since noises are often unknown on real graphs, we design two generators, namely a graph generator and a noise generator, to identify normal structures and noises in an unsupervised setting. On the one hand, the graph generator serves as a unified scheme to incorporate any useful graph prior knowledge to generate normal structures. We illustrate the generative process with community structures and power-law degree distributions as examples. On the other hand, the noise generator generates graph noises not only satisfying some fundamental properties but also in an adaptive way. Thus, real noises with arbitrary distributions can be handled successfully. Finally, in order to eliminate noises and obtain noise-free node representations, two generators need to be optimized jointly, and through maximum likelihood estimation, we equivalently convert the model into imposing different regularization constraints on the true graph and noises respectively. Our model is evaluated on both real-world and synthetic data. It outperforms other strong baselines for node classification and graph reconstruction tasks, demonstrating its ability to eliminate graph noises.
EPNE: Evolutionary Pattern Preserving Network Embedding
Sep 24, 2020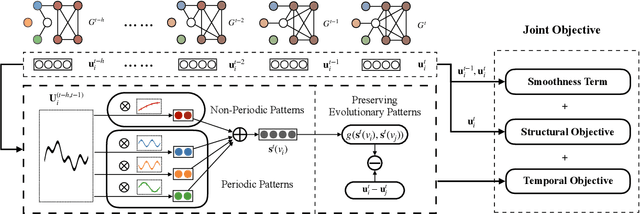
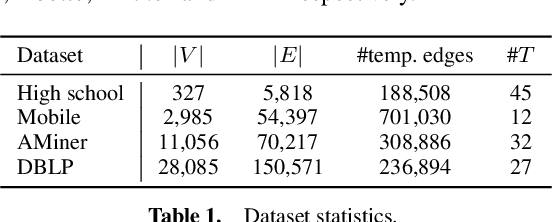
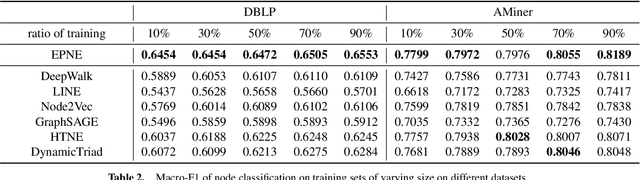
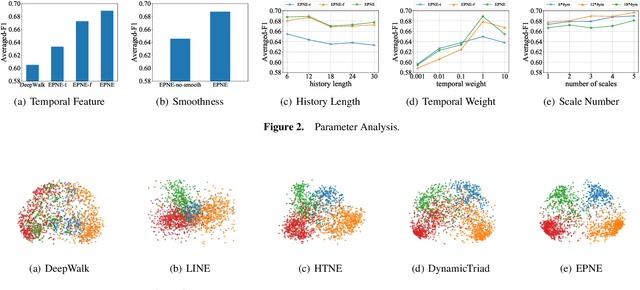
Information networks are ubiquitous and are ideal for modeling relational data. Networks being sparse and irregular, network embedding algorithms have caught the attention of many researchers, who came up with numerous embeddings algorithms in static networks. Yet in real life, networks constantly evolve over time. Hence, evolutionary patterns, namely how nodes develop itself over time, would serve as a powerful complement to static structures in embedding networks, on which relatively few works focus. In this paper, we propose EPNE, a temporal network embedding model preserving evolutionary patterns of the local structure of nodes. In particular, we analyze evolutionary patterns with and without periodicity and design strategies correspondingly to model such patterns in time-frequency domains based on causal convolutions. In addition, we propose a temporal objective function which is optimized simultaneously with proximity ones such that both temporal and structural information are preserved. With the adequate modeling of temporal information, our model is able to outperform other competitive methods in various prediction tasks.
Streaming Graph Neural Networks via Continual Learning
Sep 23, 2020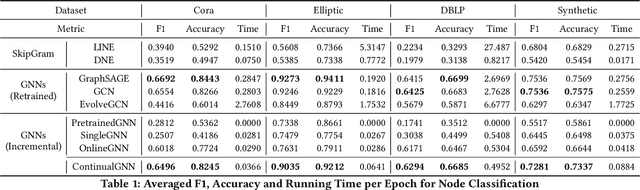
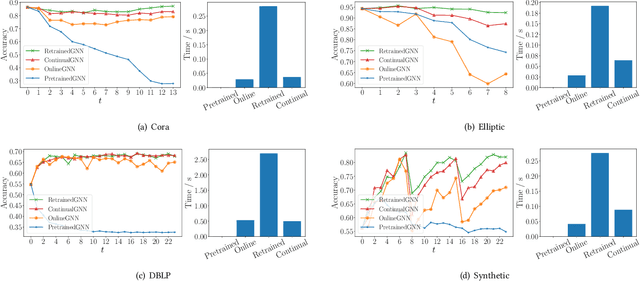
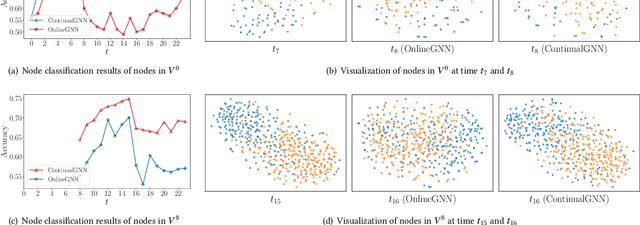
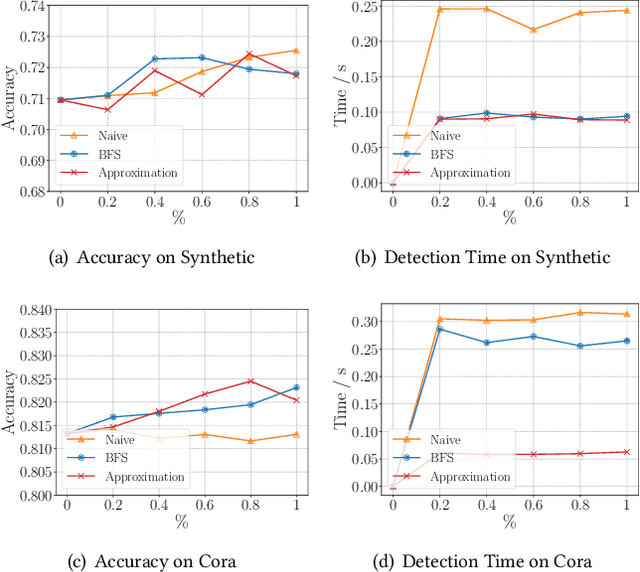
Graph neural networks (GNNs) have achieved strong performance in various applications. In the real world, network data is usually formed in a streaming fashion. The distributions of patterns that refer to neighborhood information of nodes may shift over time. The GNN model needs to learn the new patterns that cannot yet be captured. But learning incrementally leads to the catastrophic forgetting problem that historical knowledge is overwritten by newly learned knowledge. Therefore, it is important to train GNN model to learn new patterns and maintain existing patterns simultaneously, which few works focus on. In this paper, we propose a streaming GNN model based on continual learning so that the model is trained incrementally and up-to-date node representations can be obtained at each time step. Firstly, we design an approximation algorithm to detect new coming patterns efficiently based on information propagation. Secondly, we combine two perspectives of data replaying and model regularization for existing pattern consolidation. Specially, a hierarchy-importance sampling strategy for nodes is designed and a weighted regularization term for GNN parameters is derived, achieving greater stability and generalization of knowledge consolidation. Our model is evaluated on real and synthetic data sets and compared with multiple baselines. The results of node classification prove that our model can efficiently update model parameters and achieve comparable performance to model retraining. In addition, we also conduct a case study on the synthetic data, and carry out some specific analysis for each part of our model, illustrating its ability to learn new knowledge and maintain existing knowledge from different perspectives.
Tag2Vec: Learning Tag Representations in Tag Networks
Apr 19, 2019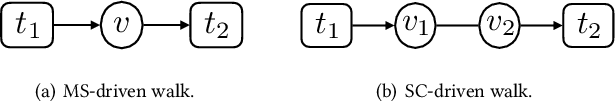
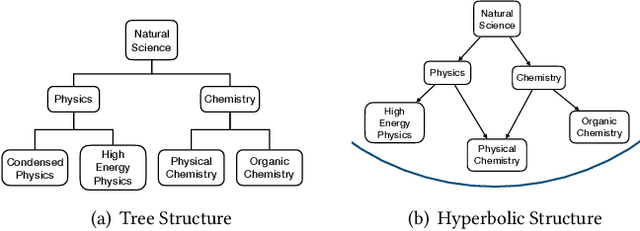
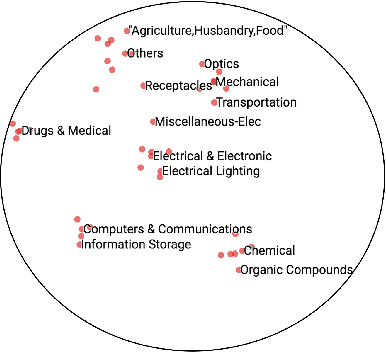
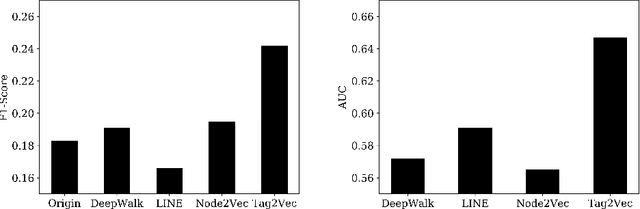
Network embedding is a method to learn low-dimensional representation vectors for nodes in complex networks. In real networks, nodes may have multiple tags but existing methods ignore the abundant semantic and hierarchical information of tags. This information is useful to many network applications and usually very stable. In this paper, we propose a tag representation learning model, Tag2Vec, which mixes nodes and tags into a hybrid network. Firstly, for tag networks, we define semantic distance as the proximity between tags and design a novel strategy, parameterized random walk, to generate context with semantic and hierarchical information of tags adaptively. Then, we propose hyperbolic Skip-gram model to express the complex hierarchical structure better with lower output dimensions. We evaluate our model on the NBER U.S. patent dataset and WordNet dataset. The results show that our model can learn tag representations with rich semantic information and it outperforms other baselines.
Using Social Network Information in Bayesian Truth Discovery
Jul 05, 2018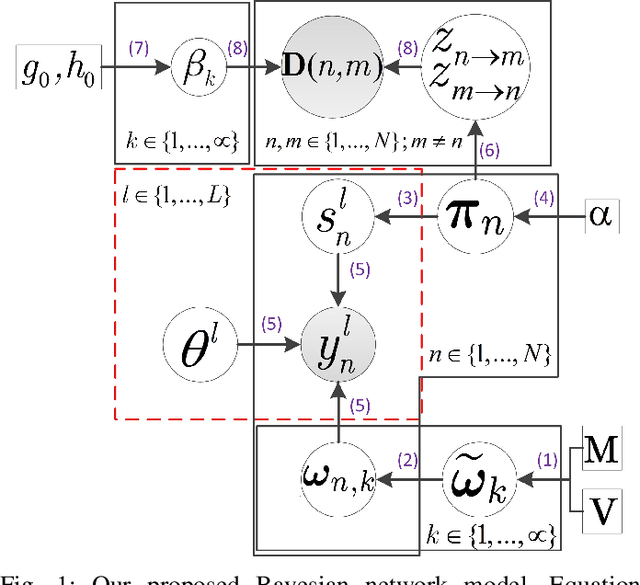
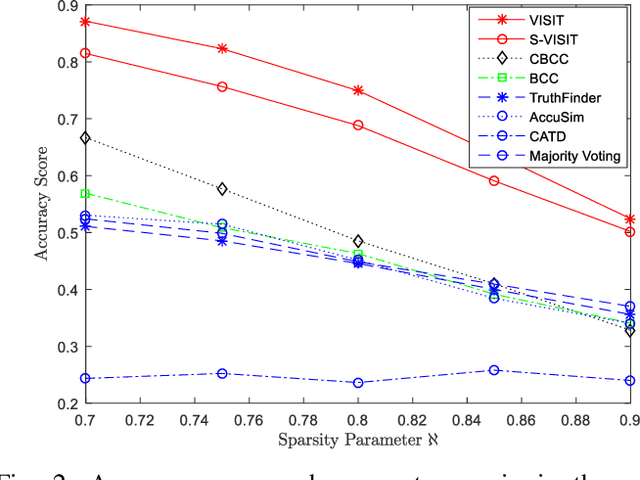
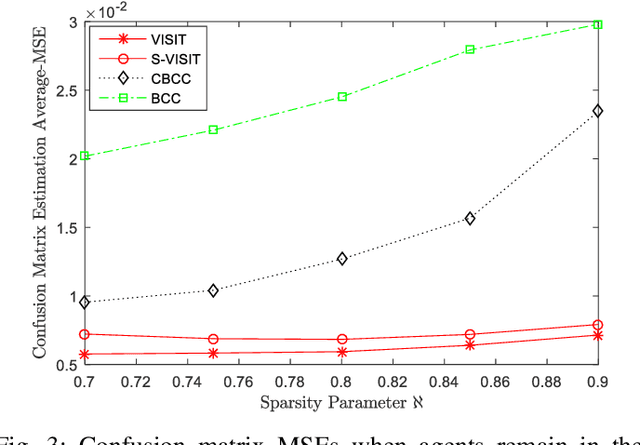

We investigate the problem of truth discovery based on opinions from multiple agents who may be unreliable or biased. We consider the case where agents' reliabilities or biases are correlated if they belong to the same community, which defines a group of agents with similar opinions regarding a particular event. An agent can belong to different communities for different events, and these communities are unknown a priori. We incorporate knowledge of the agents' social network in our truth discovery framework and develop Laplace variational inference methods to estimate agents' reliabilities, communities, and the event states. We also develop a stochastic variational inference method to scale our model to large social networks. Simulations and experiments on real data suggest that when observations are sparse, our proposed methods perform better than several other inference methods, including majority voting, TruthFinder, AccuSim, the Confidence-Aware Truth Discovery method, the Bayesian Classifier Combination (BCC) method, and the Community BCC method.