 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
Learning Cascade Ranking as One Network
Mar 12, 2025Cascade Ranking is a prevalent architecture in large-scale top-k selection systems like recommendation and advertising platforms. Traditional training methods focus on single-stage optimization, neglecting interactions between stages. Recent advances such as RankFlow and FS-LTR have introduced interaction-aware training paradigms but still struggle to 1) align training objectives with the goal of the entire cascade ranking (i.e., end-to-end recall) and 2) learn effective collaboration patterns for different stages. To address these challenges, we propose LCRON, which introduces a novel surrogate loss function derived from the lower bound probability that ground truth items are selected by cascade ranking, ensuring alignment with the overall objective of the system. According to the properties of the derived bound, we further design an auxiliary loss for each stage to drive the reduction of this bound, leading to a more robust and effective top-k selection. LCRON enables end-to-end training of the entire cascade ranking system as a unified network. Experimental results demonstrate that LCRON achieves significant improvement over existing methods on public benchmarks and industrial applications, addressing key limitations in cascade ranking training and significantly enhancing system performance.
Adaptive$^2$: Adaptive Domain Mining for Fine-grained Domain Adaptation Modeling
Dec 11, 2024



Advertising systems often face the multi-domain challenge, where data distributions vary significantly across scenarios. Existing domain adaptation methods primarily focus on building domain-adaptive neural networks but often rely on hand-crafted domain information, e.g., advertising placement, which may be sub-optimal. We think that fine-grained "domain" patterns exist that are difficult to hand-craft in online advertisement. Thus, we propose Adaptive$^2$, a novel framework that first learns domains adaptively using a domain mining module by self-supervision and then employs a shared&specific network to model shared and conflicting information. As a practice, we use VQ-VAE as the domain mining module and conduct extensive experiments on public benchmarks. Results show that traditional domain adaptation methods with hand-crafted domains perform no better than single-domain models under fair FLOPS conditions, highlighting the importance of domain definition. In contrast, Adaptive$^2$ outperforms existing approaches, emphasizing the effectiveness of our method and the significance of domain mining. We also deployed Adaptive$^2$ in the live streaming scenario of Kuaishou Advertising System, demonstrating its commercial value and potential for automatic domain identification. To the best of our knowledge, Adaptive$^2$ is the first approach to automatically learn both domain identification and adaptation in online advertising, opening new research directions for this area.
Scaling Laws for Online Advertisement Retrieval
Nov 20, 2024


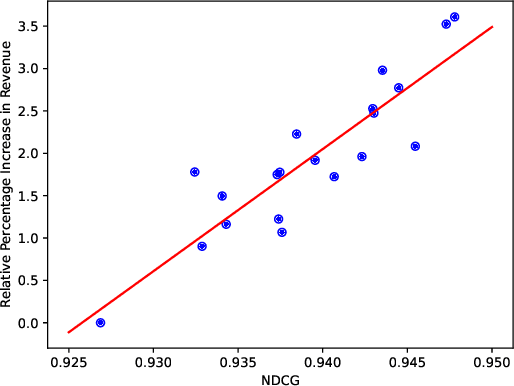
The scaling law is a notable property of neural network models and has significantly propelled the development of large language models. Scaling laws hold great promise in guiding model design and resource allocation. Recent research increasingly shows that scaling laws are not limited to NLP tasks or Transformer architectures; they also apply to domains such as recommendation. However, there is still a lack of literature on scaling law research in online advertisement retrieval systems. This may be because 1) identifying the scaling law for resource cost and online revenue is often expensive in both time and training resources for large-scale industrial applications, and 2) varying settings for different systems prevent the scaling law from being applied across various scenarios. To address these issues, we propose a lightweight paradigm to identify the scaling law of online revenue and machine cost for a certain online advertisement retrieval scenario with a low experimental cost. Specifically, we focus on a sole factor (FLOPs) and propose an offline metric named R/R* that exhibits a high linear correlation with online revenue for retrieval models. We estimate the machine cost offline via a simulation algorithm. Thus, we can transform most online experiments into low-cost offline experiments. We conduct comprehensive experiments to verify the effectiveness of our proposed metric R/R* and to identify the scaling law in the online advertisement retrieval system of Kuaishou. With the scaling law, we demonstrate practical applications for ROI-constrained model designing and multi-scenario resource allocation in Kuaishou advertising system. To the best of our knowledge, this is the first work to study the scaling laws for online advertisement retrieval of real-world systems, showing great potential for scaling law in advertising system optimization.
Adaptive Neural Ranking Framework: Toward Maximized Business Goal for Cascade Ranking Systems
Oct 16, 2023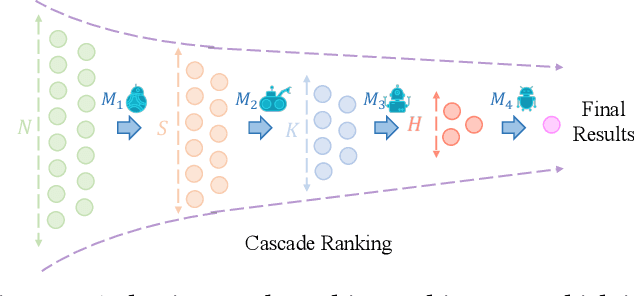

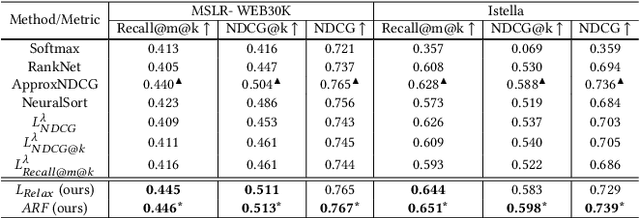
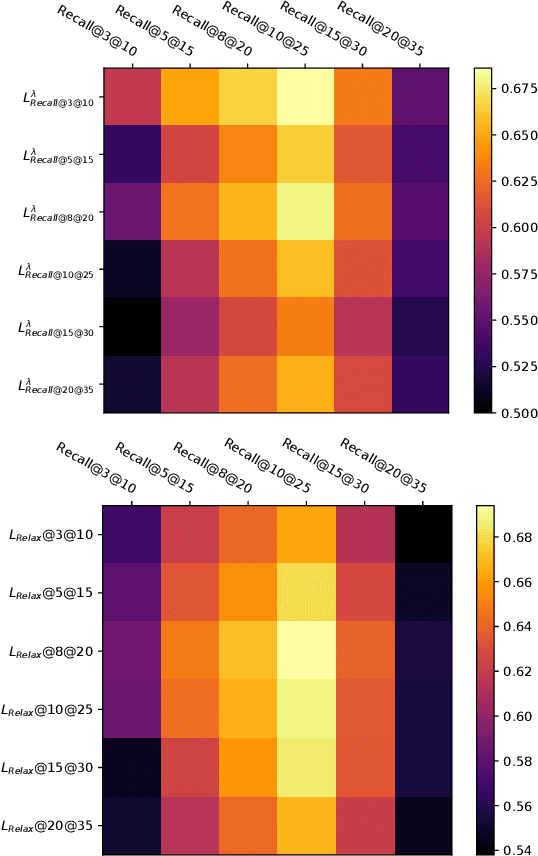
Cascade ranking is widely used for large-scale top-k selection problems in online advertising and recommendation systems, and learning-to-rank is an important way to optimize the models in cascade ranking systems. Previous works on learning-to-rank usually focus on letting the model learn the complete order or pay more attention to the order of top materials, and adopt the corresponding rank metrics as optimization targets. However, these optimization targets can not adapt to various cascade ranking scenarios with varying data complexities and model capabilities; and the existing metric-driven methods such as the Lambda framework can only optimize a rough upper bound of the metric, potentially resulting in performance misalignment. To address these issues, we first propose a novel perspective on optimizing cascade ranking systems by highlighting the adaptability of optimization targets to data complexities and model capabilities. Concretely, we employ multi-task learning framework to adaptively combine the optimization of relaxed and full targets, which refers to metrics Recall@m@k and OAP respectively. Then we introduce a permutation matrix to represent the rank metrics and employ differentiable sorting techniques to obtain a relaxed permutation matrix with controllable approximate error bound. This enables us to optimize both the relaxed and full targets directly and more appropriately using the proposed surrogate losses within the deep learning framework. We named this method as Adaptive Neural Ranking Framework. We use the NeuralSort method to obtain the relaxed permutation matrix and draw on the uncertainty weight method in multi-task learning to optimize the proposed losses jointly. Experiments on a total of 4 public and industrial benchmarks show the effectiveness and generalization of our method, and online experiment shows that our method has significant application value.
AMCAD: Adaptive Mixed-Curvature Representation based Advertisement Retrieval System
Mar 28, 2022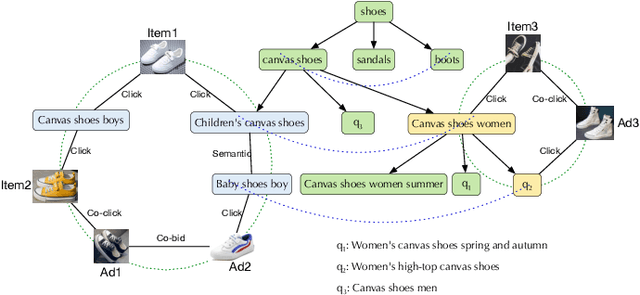
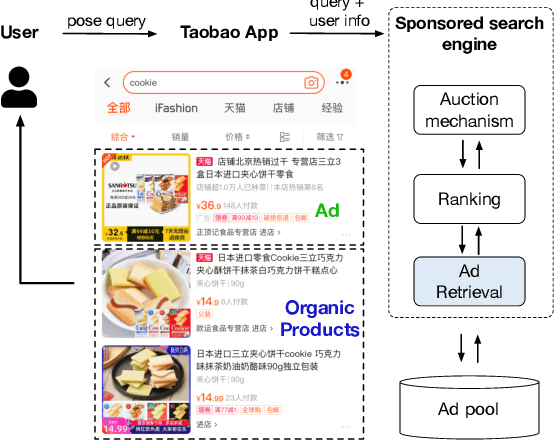
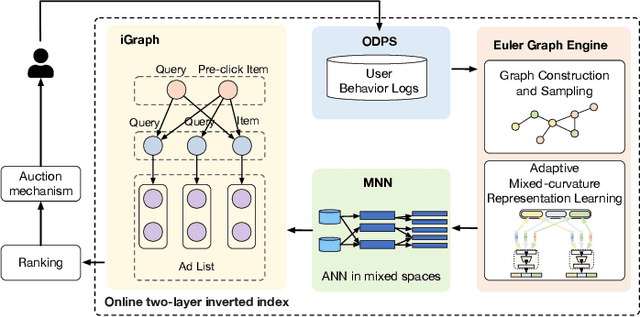
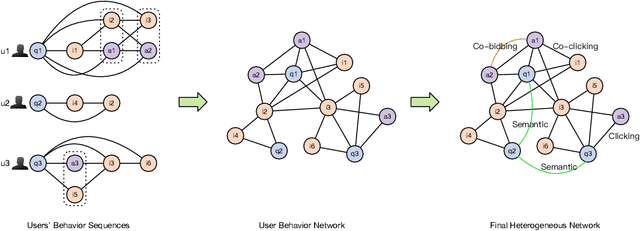
Graph embedding based retrieval has become one of the most popular techniques in the information retrieval community and search engine industry. The classical paradigm mainly relies on the flat Euclidean geometry. In recent years, hyperbolic (negative curvature) and spherical (positive curvature) representation methods have shown their superiority to capture hierarchical and cyclic data structures respectively. However, in industrial scenarios such as e-commerce sponsored search platforms, the large-scale heterogeneous query-item-advertisement interaction graphs often have multiple structures coexisting. Existing methods either only consider a single geometry space, or combine several spaces manually, which are incapable and inflexible to model the complexity and heterogeneity in the real scenario. To tackle this challenge, we present a web-scale Adaptive Mixed-Curvature ADvertisement retrieval system (AMCAD) to automatically capture the complex and heterogeneous graph structures in non-Euclidean spaces. Specifically, entities are represented in adaptive mixed-curvature spaces, where the types and curvatures of the subspaces are trained to be optimal combinations. Besides, an attentive edge-wise space projector is designed to model the similarities between heterogeneous nodes according to local graph structures and the relation types. Moreover, to deploy AMCAD in Taobao, one of the largest ecommerce platforms with hundreds of million users, we design an efficient two-layer online retrieval framework for the task of graph based advertisement retrieval. Extensive evaluations on real-world datasets and A/B tests on online traffic are conducted to illustrate the effectiveness of the proposed system.