 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
RATE: Reviewer Profiling and Annotation-free Training for Expertise Ranking in Peer Review Systems
Jan 27, 2026Reviewer assignment is increasingly critical yet challenging in the LLM era, where rapid topic shifts render many pre-2023 benchmarks outdated and where proxy signals poorly reflect true reviewer familiarity. We address this evaluation bottleneck by introducing LR-bench, a high-fidelity, up-to-date benchmark curated from 2024-2025 AI/NLP manuscripts with five-level self-assessed familiarity ratings collected via a large-scale email survey, yielding 1055 expert-annotated paper-reviewer-score annotations. We further propose RATE, a reviewer-centric ranking framework that distills each reviewer's recent publications into compact keyword-based profiles and fine-tunes an embedding model with weak preference supervision constructed from heuristic retrieval signals, enabling matching each manuscript against a reviewer profile directly. Across LR-bench and the CMU gold-standard dataset, our approach consistently achieves state-of-the-art performance, outperforming strong embedding baselines by a clear margin. We release LR-bench at https://huggingface.co/datasets/Gnociew/LR-bench, and a GitHub repository at https://github.com/Gnociew/RATE-Reviewer-Assign.
Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
Exploring Human-Like Thinking in Search Simulations with Large Language Models
Apr 10, 2025Simulating user search behavior is a critical task in information retrieval, which can be employed for user behavior modeling, data augmentation, and system evaluation. Recent advancements in large language models (LLMs) have opened up new possibilities for generating human-like actions including querying, browsing, and clicking. In this work, we explore the integration of human-like thinking into search simulations by leveraging LLMs to simulate users' hidden cognitive processes. Specifically, given a search task and context, we prompt LLMs to first think like a human before executing the corresponding action. As existing search datasets do not include users' thought processes, we conducted a user study to collect a new dataset enriched with users' explicit thinking. We investigate the impact of incorporating such human-like thinking on simulation performance and apply supervised fine-tuning (SFT) to teach LLMs to emulate both human thinking and actions. Our experiments span two dimensions in leveraging LLMs for user simulation: (1) with or without explicit thinking, and (2) with or without fine-tuning on the thinking-augmented dataset. The results demonstrate the feasibility and potential of incorporating human-like thinking in user simulations, though performance improvements on some metrics remain modest. We believe this exploration provides new avenues and inspirations for advancing user behavior modeling in search simulations.
Learning Cascade Ranking as One Network
Mar 12, 2025Cascade Ranking is a prevalent architecture in large-scale top-k selection systems like recommendation and advertising platforms. Traditional training methods focus on single-stage optimization, neglecting interactions between stages. Recent advances such as RankFlow and FS-LTR have introduced interaction-aware training paradigms but still struggle to 1) align training objectives with the goal of the entire cascade ranking (i.e., end-to-end recall) and 2) learn effective collaboration patterns for different stages. To address these challenges, we propose LCRON, which introduces a novel surrogate loss function derived from the lower bound probability that ground truth items are selected by cascade ranking, ensuring alignment with the overall objective of the system. According to the properties of the derived bound, we further design an auxiliary loss for each stage to drive the reduction of this bound, leading to a more robust and effective top-k selection. LCRON enables end-to-end training of the entire cascade ranking system as a unified network. Experimental results demonstrate that LCRON achieves significant improvement over existing methods on public benchmarks and industrial applications, addressing key limitations in cascade ranking training and significantly enhancing system performance.
Adaptive$^2$: Adaptive Domain Mining for Fine-grained Domain Adaptation Modeling
Dec 11, 2024



Advertising systems often face the multi-domain challenge, where data distributions vary significantly across scenarios. Existing domain adaptation methods primarily focus on building domain-adaptive neural networks but often rely on hand-crafted domain information, e.g., advertising placement, which may be sub-optimal. We think that fine-grained "domain" patterns exist that are difficult to hand-craft in online advertisement. Thus, we propose Adaptive$^2$, a novel framework that first learns domains adaptively using a domain mining module by self-supervision and then employs a shared&specific network to model shared and conflicting information. As a practice, we use VQ-VAE as the domain mining module and conduct extensive experiments on public benchmarks. Results show that traditional domain adaptation methods with hand-crafted domains perform no better than single-domain models under fair FLOPS conditions, highlighting the importance of domain definition. In contrast, Adaptive$^2$ outperforms existing approaches, emphasizing the effectiveness of our method and the significance of domain mining. We also deployed Adaptive$^2$ in the live streaming scenario of Kuaishou Advertising System, demonstrating its commercial value and potential for automatic domain identification. To the best of our knowledge, Adaptive$^2$ is the first approach to automatically learn both domain identification and adaptation in online advertising, opening new research directions for this area.
Scaling Laws for Online Advertisement Retrieval
Nov 20, 2024


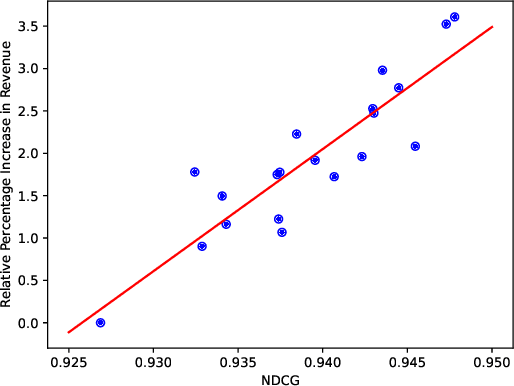
The scaling law is a notable property of neural network models and has significantly propelled the development of large language models. Scaling laws hold great promise in guiding model design and resource allocation. Recent research increasingly shows that scaling laws are not limited to NLP tasks or Transformer architectures; they also apply to domains such as recommendation. However, there is still a lack of literature on scaling law research in online advertisement retrieval systems. This may be because 1) identifying the scaling law for resource cost and online revenue is often expensive in both time and training resources for large-scale industrial applications, and 2) varying settings for different systems prevent the scaling law from being applied across various scenarios. To address these issues, we propose a lightweight paradigm to identify the scaling law of online revenue and machine cost for a certain online advertisement retrieval scenario with a low experimental cost. Specifically, we focus on a sole factor (FLOPs) and propose an offline metric named R/R* that exhibits a high linear correlation with online revenue for retrieval models. We estimate the machine cost offline via a simulation algorithm. Thus, we can transform most online experiments into low-cost offline experiments. We conduct comprehensive experiments to verify the effectiveness of our proposed metric R/R* and to identify the scaling law in the online advertisement retrieval system of Kuaishou. With the scaling law, we demonstrate practical applications for ROI-constrained model designing and multi-scenario resource allocation in Kuaishou advertising system. To the best of our knowledge, this is the first work to study the scaling laws for online advertisement retrieval of real-world systems, showing great potential for scaling law in advertising system optimization.
Reinfier and Reintrainer: Verification and Interpretation-Driven Safe Deep Reinforcement Learning Frameworks
Oct 19, 2024Ensuring verifiable and interpretable safety of deep reinforcement learning (DRL) is crucial for its deployment in real-world applications. Existing approaches like verification-in-the-loop training, however, face challenges such as difficulty in deployment, inefficient training, lack of interpretability, and suboptimal performance in property satisfaction and reward performance. In this work, we propose a novel verification-driven interpretation-in-the-loop framework Reintrainer to develop trustworthy DRL models, which are guaranteed to meet the expected constraint properties. Specifically, in each iteration, this framework measures the gap between the on-training model and predefined properties using formal verification, interprets the contribution of each input feature to the model's output, and then generates the training strategy derived from the on-the-fly measure results, until all predefined properties are proven. Additionally, the low reusability of existing verifiers and interpreters motivates us to develop Reinfier, a general and fundamental tool within Reintrainer for DRL verification and interpretation. Reinfier features breakpoints searching and verification-driven interpretation, associated with a concise constraint-encoding language DRLP. Evaluations demonstrate that Reintrainer outperforms the state-of-the-art on six public benchmarks in both performance and property guarantees. Our framework can be accessed at https://github.com/Kurayuri/Reinfier.
GraphEdit: Large Language Models for Graph Structure Learning
Mar 05, 2024



Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
Improving Expressive Power of Spectral Graph Neural Networks with Eigenvalue Correction
Jan 28, 2024In recent years, spectral graph neural networks, characterized by polynomial filters, have garnered increasing attention and have achieved remarkable performance in tasks such as node classification. These models typically assume that eigenvalues for the normalized Laplacian matrix are distinct from each other, thus expecting a polynomial filter to have a high fitting ability. However, this paper empirically observes that normalized Laplacian matrices frequently possess repeated eigenvalues. Moreover, we theoretically establish that the number of distinguishable eigenvalues plays a pivotal role in determining the expressive power of spectral graph neural networks. In light of this observation, we propose an eigenvalue correction strategy that can free polynomial filters from the constraints of repeated eigenvalue inputs. Concretely, the proposed eigenvalue correction strategy enhances the uniform distribution of eigenvalues, thus mitigating repeated eigenvalues, and improving the fitting capacity and expressive power of polynomial filters. Extensive experimental results on both synthetic and real-world datasets demonstrate the superiority of our method.