Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Word Embeddings: An Encoding Approach
Paper and Code
Jul 24, 2016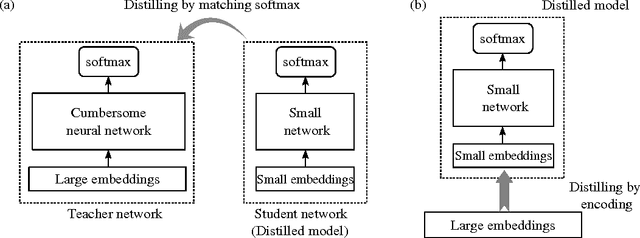
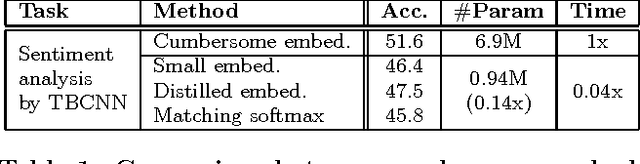

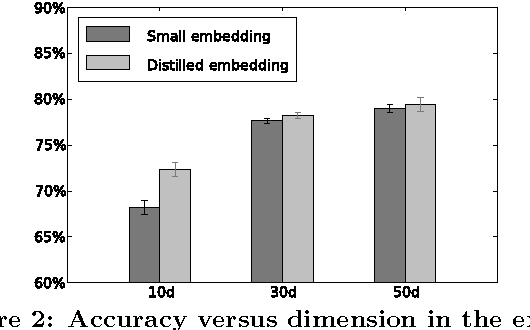
Distilling knowledge from a well-trained cumbersome network to a small one has recently become a new research topic, as lightweight neural networks with high performance are particularly in need in various resource-restricted systems. This paper addresses the problem of distilling word embeddings for NLP tasks. We propose an encoding approach to distill task-specific knowledge from a set of high-dimensional embeddings, which can reduce model complexity by a large margin as well as retain high accuracy, showing a good compromise between efficiency and performance. Experiments in two tasks reveal the phenomenon that distilling knowledge from cumbersome embeddings is better than directly training neural networks with small embeddings.
* Accepted by CIKM-16 as a short paper, and by the Representation
Learning for Natural Language Processing (RL4NLP) Workshop @ACL-16 for
presentation
View paper on