 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou
Aug 10, 2024In this paper, we present the practical problems and the lessons learned at short-video services from Kuaishou. In industry, a widely-used multi-task framework is the Mixture-of-Experts (MoE) paradigm, which always introduces some shared and specific experts for each task and then uses gate networks to measure related experts' contributions. Although the MoE achieves remarkable improvements, we still observe three anomalies that seriously affect model performances in our iteration: (1) Expert Collapse: We found that experts' output distributions are significantly different, and some experts have over 90% zero activations with ReLU, making it hard for gate networks to assign fair weights to balance experts. (2) Expert Degradation: Ideally, the shared-expert aims to provide predictive information for all tasks simultaneously. Nevertheless, we find that some shared-experts are occupied by only one task, which indicates that shared-experts lost their ability but degenerated into some specific-experts. (3) Expert Underfitting: In our services, we have dozens of behavior tasks that need to be predicted, but we find that some data-sparse prediction tasks tend to ignore their specific-experts and assign large weights to shared-experts. The reason might be that the shared-experts can perceive more gradient updates and knowledge from dense tasks, while specific-experts easily fall into underfitting due to their sparse behaviors. Motivated by those observations, we propose HoME to achieve a simple, efficient and balanced MoE system for multi-task learning.
TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
Feb 05, 2023Life-long user behavior modeling, i.e., extracting a user's hidden interests from rich historical behaviors in months or even years, plays a central role in modern CTR prediction systems. Conventional algorithms mostly follow two cascading stages: a simple General Search Unit (GSU) for fast and coarse search over tens of thousands of long-term behaviors and an Exact Search Unit (ESU) for effective Target Attention (TA) over the small number of finalists from GSU. Although efficient, existing algorithms mostly suffer from a crucial limitation: the \textit{inconsistent} target-behavior relevance metrics between GSU and ESU. As a result, their GSU usually misses highly relevant behaviors but retrieves ones considered irrelevant by ESU. In such case, the TA in ESU, no matter how attention is allocated, mostly deviates from the real user interests and thus degrades the overall CTR prediction accuracy. To address such inconsistency, we propose \textbf{TWo-stage Interest Network (TWIN)}, where our Consistency-Preserved GSU (CP-GSU) adopts the identical target-behavior relevance metric as the TA in ESU, making the two stages twins. Specifically, to break TA's computational bottleneck and extend it from ESU to GSU, or namely from behavior length $10^2$ to length $10^4-10^5$, we build a novel attention mechanism by behavior feature splitting. For the video inherent features of a behavior, we calculate their linear projection by efficient pre-computing \& caching strategies. And for the user-item cross features, we compress each into a one-dimentional bias term in the attention score calculation to save the computational cost. The consistency between two stages, together with the effective TA-based relevance metric in CP-GSU, contributes to significant performance gain in CTR prediction.
CodeEditor: Learning to Edit Source Code with Pre-trained Models
Oct 31, 2022



Developers often perform repetitive code editing activities for various reasons (e.g., code refactor) during software development. Many deep learning models are applied to automate code editing by learning from the code editing history. Recently, pre-trained code editing models have achieved the state-of-the-art (SOTA) results. Pre-trained models are first pre-trained with pre-training tasks and fine-tuned with the code editing task. Existing pre-training tasks mainly are code infilling tasks (e.g., masked language modeling), which are derived from the natural language processing field and are not designed for code editing. In this paper, we propose a pre-training task specialized in code editing and present an effective pre-trained code editing model named CodeEditor. Our pre-training task further improves the performance and generalization ability of code editing models. Specifically, we collect real-world code snippets as the ground truth and use a generator to rewrite them into natural but inferior versions. Then, we pre-train our CodeEditor to edit inferior versions into the ground truth, to learn edit patterns. We conduct experiments on four datasets and evaluate models in three settings. (1) In the fine-tuning setting, we fine-tune the pre-trained CodeEditor with four datasets. CodeEditor outperforms SOTA baselines by 15%, 25.5%, and 9.4% and 26.6% on four datasets. (2) In the few-shot setting, we fine-tune the pre-trained CodeEditor with limited data. CodeEditor substantially performs better than all baselines, even outperforming baselines that are fine-tuned with all data. (3) In the zero-shot setting, we evaluate the pre-trained CodeEditor without fine-tuning. CodeEditor correctly edits 1,113 programs while SOTA baselines can not work. The results prove that the superiority of our pre-training task and the pre-trained CodeEditor is more effective in automatic code editing.
Contextual Representation Learning beyond Masked Language Modeling
Apr 08, 2022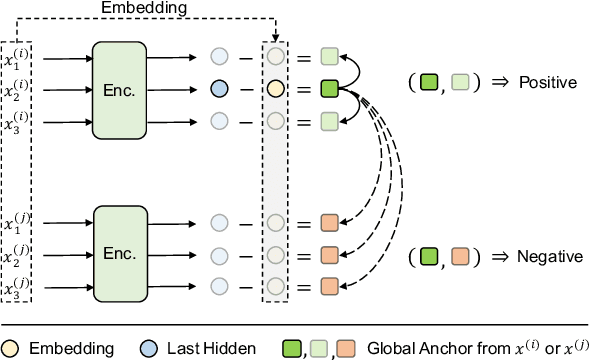


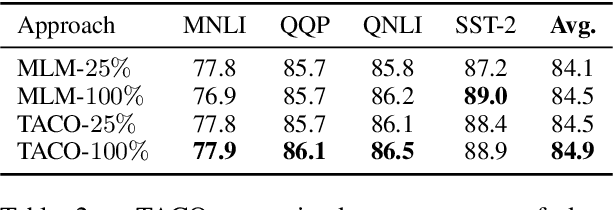
How do masked language models (MLMs) such as BERT learn contextual representations? In this work, we analyze the learning dynamics of MLMs. We find that MLMs adopt sampled embeddings as anchors to estimate and inject contextual semantics to representations, which limits the efficiency and effectiveness of MLMs. To address these issues, we propose TACO, a simple yet effective representation learning approach to directly model global semantics. TACO extracts and aligns contextual semantics hidden in contextualized representations to encourage models to attend global semantics when generating contextualized representations. Experiments on the GLUE benchmark show that TACO achieves up to 5x speedup and up to 1.2 points average improvement over existing MLMs. The code is available at https://github.com/FUZHIYI/TACO.
A Survey on Green Deep Learning
Nov 10, 2021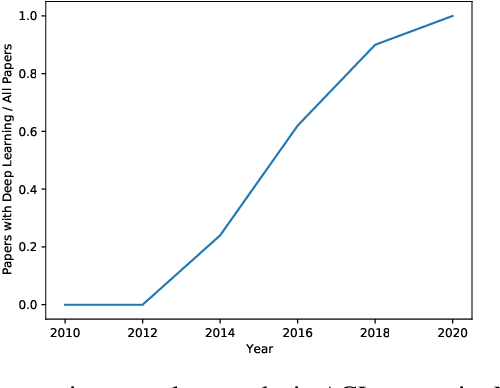
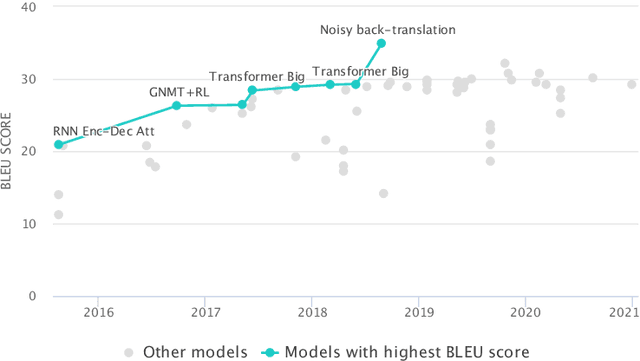
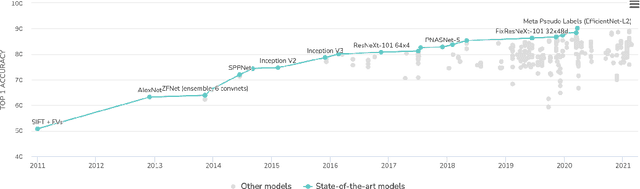

In recent years, larger and deeper models are springing up and continuously pushing state-of-the-art (SOTA) results across various fields like natural language processing (NLP) and computer vision (CV). However, despite promising results, it needs to be noted that the computations required by SOTA models have been increased at an exponential rate. Massive computations not only have a surprisingly large carbon footprint but also have negative effects on research inclusiveness and deployment on real-world applications. Green deep learning is an increasingly hot research field that appeals to researchers to pay attention to energy usage and carbon emission during model training and inference. The target is to yield novel results with lightweight and efficient technologies. Many technologies can be used to achieve this goal, like model compression and knowledge distillation. This paper focuses on presenting a systematic review of the development of Green deep learning technologies. We classify these approaches into four categories: (1) compact networks, (2) energy-efficient training strategies, (3) energy-efficient inference approaches, and (4) efficient data usage. For each category, we discuss the progress that has been achieved and the unresolved challenges.
Structure-aware Pre-training for Table Understanding with Tree-based Transformers
Nov 06, 2020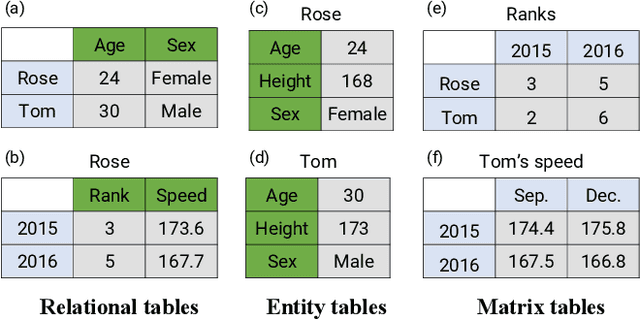
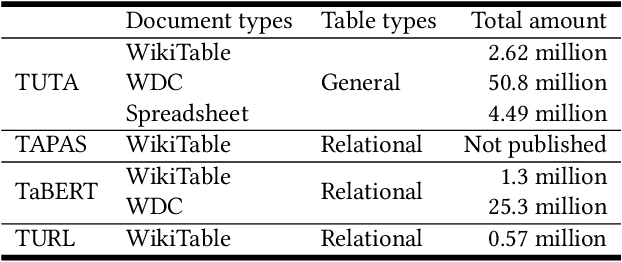
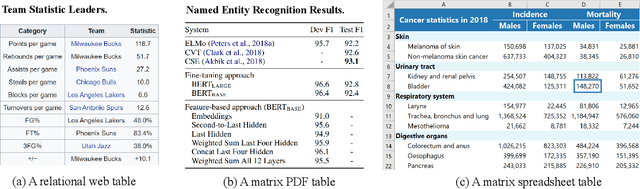

Tables are widely used with various structures to organize and present data. Recent attempts on table understanding mainly focus on relational tables, yet overlook to other common table structures. In this paper, we propose TUTA, a unified pre-training architecture for understanding generally structured tables. Since understanding a table needs to leverage both spatial, hierarchical, and semantic information, we adapt the self-attention strategy with several key structure-aware mechanisms. First, we propose a novel tree-based structure called a bi-dimensional coordinate tree, to describe both the spatial and hierarchical information in tables. Upon this, we extend the pre-training architecture with two core mechanisms, namely the tree-based attention and tree-based position embedding. Moreover, to capture table information in a progressive manner, we devise three pre-training objectives to enable representations at the token, cell, and table levels. TUTA pre-trains on a wide range of unlabeled tables and fine-tunes on a critical task in the field of table structure understanding, i.e. cell type classification. Experiment results show that TUTA is highly effective, achieving state-of-the-art on four well-annotated cell type classification datasets.
Code Generation as a Dual Task of Code Summarization
Oct 14, 2019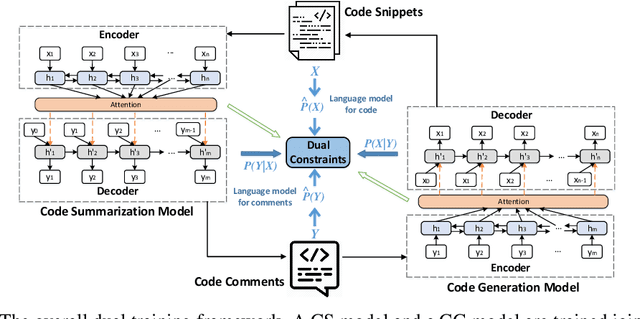
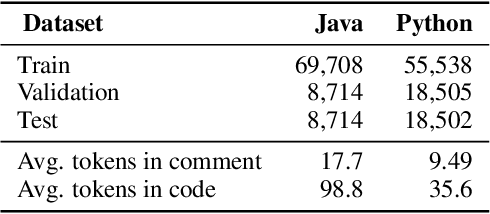
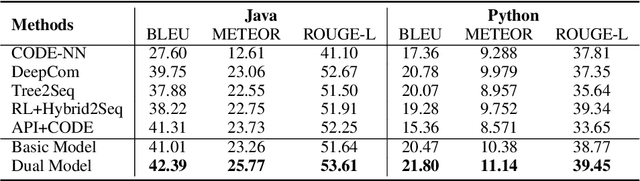

Code summarization (CS) and code generation (CG) are two crucial tasks in the field of automatic software development. Various neural network-based approaches are proposed to solve these two tasks separately. However, there exists a specific intuitive correlation between CS and CG, which have not been exploited in previous work. In this paper, we apply the relations between two tasks to improve the performance of both tasks. In other words, exploiting the duality between the two tasks, we propose a dual training framework to train the two tasks simultaneously. In this framework, we consider the dualities on probability and attention weights, and design corresponding regularization terms to constrain the duality. We evaluate our approach on two datasets collected from GitHub, and experimental results show that our dual framework can improve the performance of CS and CG tasks over baselines.
A Self-Attentional Neural Architecture for Code Completion with Multi-Task Learning
Oct 12, 2019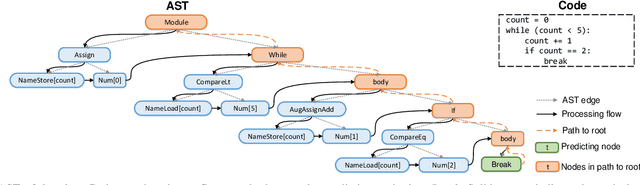
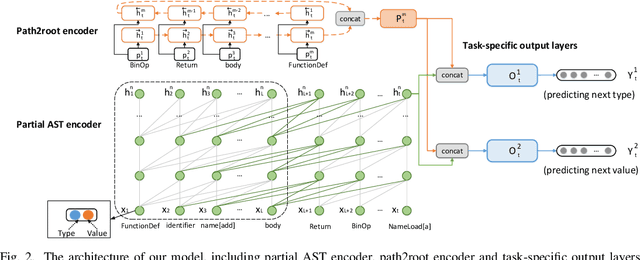
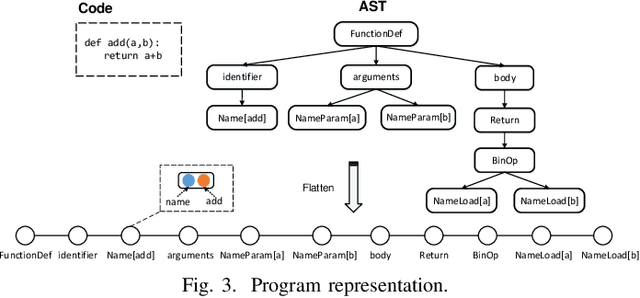
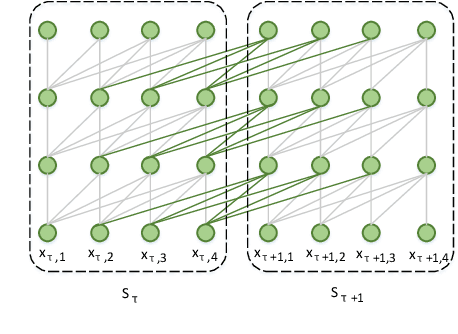
Code completion, one of the most useful features in the integrated development environments, can accelerate software development by suggesting the libraries, APIs, method names in real-time. Recent studies have shown that statistical language models can improve the performance of code completion tools through learning from large-scale software repositories. However, these models suffer from three major drawbacks: a) The hierarchical structural information of the programs is not fully utilized in the program's representation; b) In programs, the semantic relationships can be very long, existing LSTM based language models are not sufficient to model the long-term dependency. c) Existing approaches perform a specific task in one model, which leads to the underuse of the information from related tasks. In this paper, we present a novel method that introduces the hierarchical structural information into the representation of programs by considering the path from the predicting node to the root node. To capture the long-term dependency in the input programs, we apply Transformer-XL network as the base language model. Besides, we creatively propose a Multi-Task Learning (MTL) framework to learn two related tasks in code completion jointly, where knowledge acquired from one task could be beneficial to another task. Experiments on three real-world datasets demonstrate the effectiveness of our model when compared with state-of-the-art methods.