 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve and Refine: Exemplar-based Neural Comment Generation
Oct 09, 2020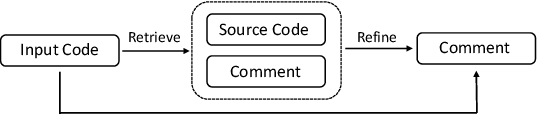
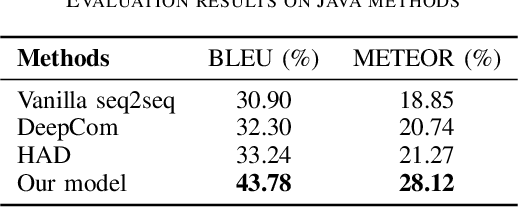
Code comment generation which aims to automatically generate natural language descriptions for source code, is a crucial task in the field of automatic software development. Traditional comment generation methods use manually-crafted templates or information retrieval (IR) techniques to generate summaries for source code. In recent years, neural network-based methods which leveraged acclaimed encoder-decoder deep learning framework to learn comment generation patterns from a large-scale parallel code corpus, have achieved impressive results. However, these emerging methods only take code-related information as input. Software reuse is common in the process of software development, meaning that comments of similar code snippets are helpful for comment generation. Inspired by the IR-based and template-based approaches, in this paper, we propose a neural comment generation approach where we use the existing comments of similar code snippets as exemplars to guide comment generation. Specifically, given a piece of code, we first use an IR technique to retrieve a similar code snippet and treat its comment as an exemplar. Then we design a novel seq2seq neural network that takes the given code, its AST, its similar code, and its exemplar as input, and leverages the information from the exemplar to assist in the target comment generation based on the semantic similarity between the source code and the similar code. We evaluate our approach on a large-scale Java corpus, which contains about 2M samples, and experimental results demonstrate that our model outperforms the state-of-the-art methods by a substantial margin.
Code Generation as a Dual Task of Code Summarization
Oct 14, 2019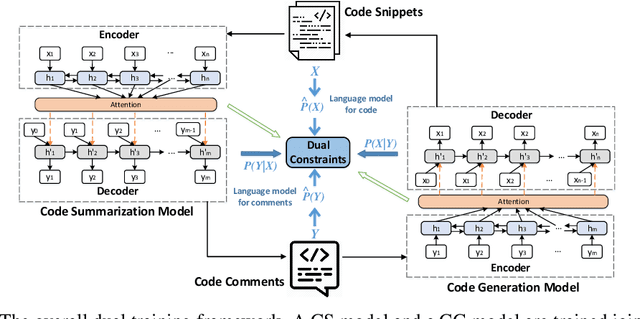
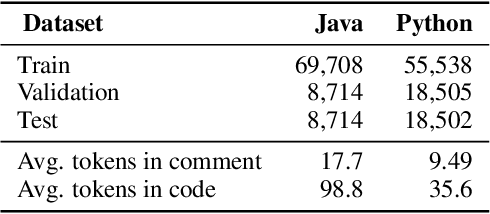
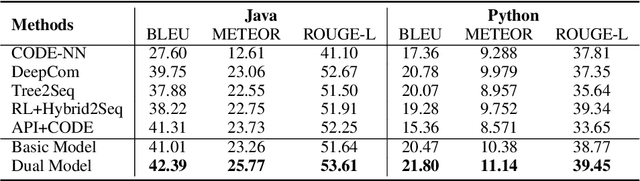

Code summarization (CS) and code generation (CG) are two crucial tasks in the field of automatic software development. Various neural network-based approaches are proposed to solve these two tasks separately. However, there exists a specific intuitive correlation between CS and CG, which have not been exploited in previous work. In this paper, we apply the relations between two tasks to improve the performance of both tasks. In other words, exploiting the duality between the two tasks, we propose a dual training framework to train the two tasks simultaneously. In this framework, we consider the dualities on probability and attention weights, and design corresponding regularization terms to constrain the duality. We evaluate our approach on two datasets collected from GitHub, and experimental results show that our dual framework can improve the performance of CS and CG tasks over baselines.
A Self-Attentional Neural Architecture for Code Completion with Multi-Task Learning
Oct 12, 2019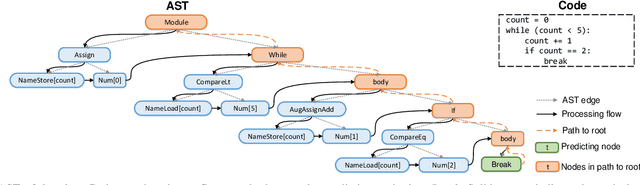
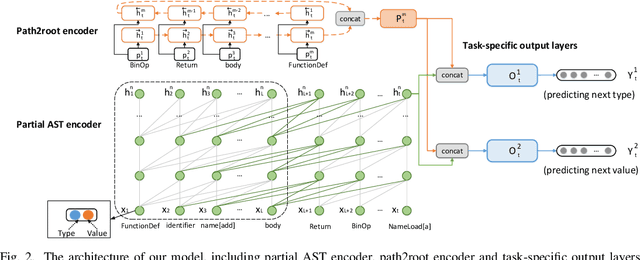
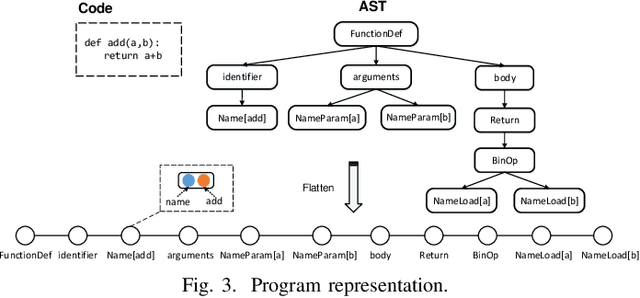
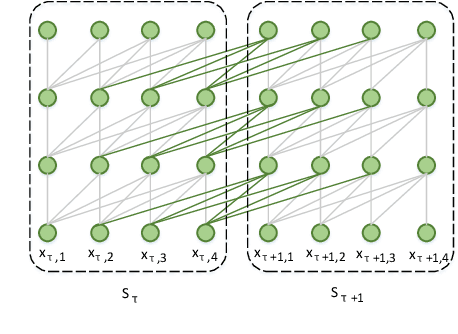
Code completion, one of the most useful features in the integrated development environments, can accelerate software development by suggesting the libraries, APIs, method names in real-time. Recent studies have shown that statistical language models can improve the performance of code completion tools through learning from large-scale software repositories. However, these models suffer from three major drawbacks: a) The hierarchical structural information of the programs is not fully utilized in the program's representation; b) In programs, the semantic relationships can be very long, existing LSTM based language models are not sufficient to model the long-term dependency. c) Existing approaches perform a specific task in one model, which leads to the underuse of the information from related tasks. In this paper, we present a novel method that introduces the hierarchical structural information into the representation of programs by considering the path from the predicting node to the root node. To capture the long-term dependency in the input programs, we apply Transformer-XL network as the base language model. Besides, we creatively propose a Multi-Task Learning (MTL) framework to learn two related tasks in code completion jointly, where knowledge acquired from one task could be beneficial to another task. Experiments on three real-world datasets demonstrate the effectiveness of our model when compared with state-of-the-art methods.
Why Do Neural Dialog Systems Generate Short and Meaningless Replies? A Comparison between Dialog and Translation
Dec 06, 2017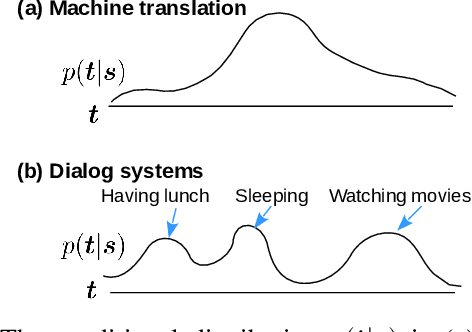
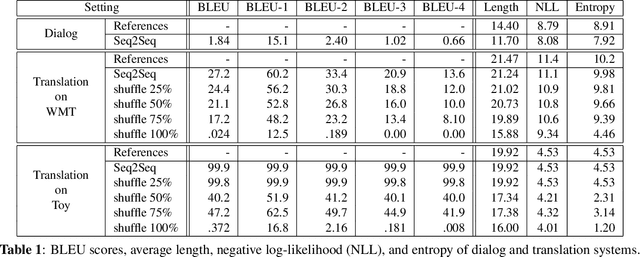
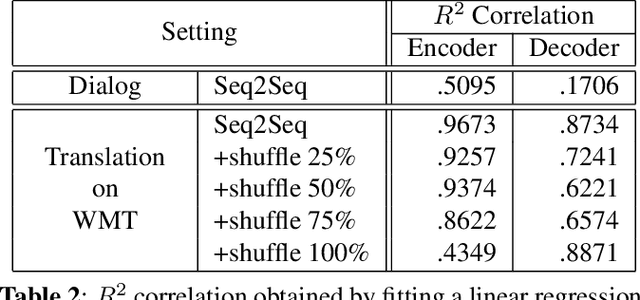
This paper addresses the question: Why do neural dialog systems generate short and meaningless replies? We conjecture that, in a dialog system, an utterance may have multiple equally plausible replies, causing the deficiency of neural networks in the dialog application. We propose a systematic way to mimic the dialog scenario in a machine translation system, and manage to reproduce the phenomenon of generating short and less meaningful sentences in the translation setting, showing evidence of our conjecture.