 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025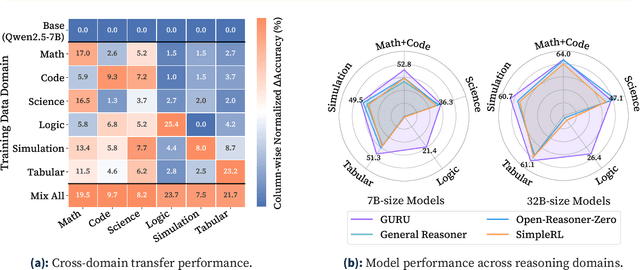
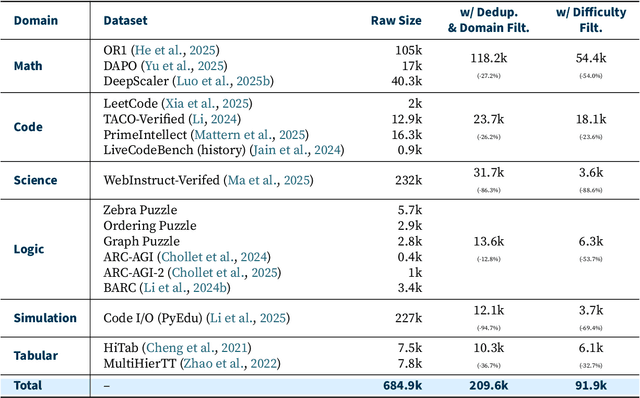
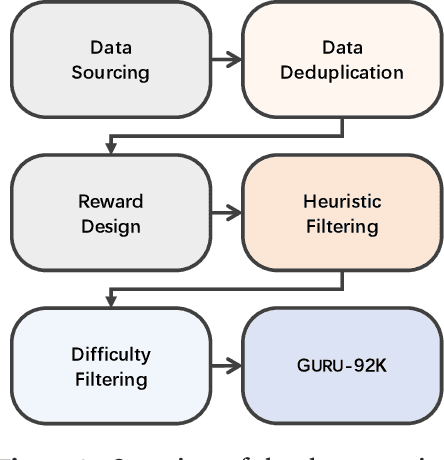

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
MegaMath: Pushing the Limits of Open Math Corpora
Apr 03, 2025



Mathematical reasoning is a cornerstone of human intelligence and a key benchmark for advanced capabilities in large language models (LLMs). However, the research community still lacks an open, large-scale, high-quality corpus tailored to the demands of math-centric LLM pre-training. We present MegaMath, an open dataset curated from diverse, math-focused sources through following practices: (1) Revisiting web data: We re-extracted mathematical documents from Common Crawl with math-oriented HTML optimizations, fasttext-based filtering and deduplication, all for acquiring higher-quality data on the Internet. (2) Recalling Math-related code data: We identified high quality math-related code from large code training corpus, Stack-V2, further enhancing data diversity. (3) Exploring Synthetic data: We synthesized QA-style text, math-related code, and interleaved text-code blocks from web data or code data. By integrating these strategies and validating their effectiveness through extensive ablations, MegaMath delivers 371B tokens with the largest quantity and top quality among existing open math pre-training datasets.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024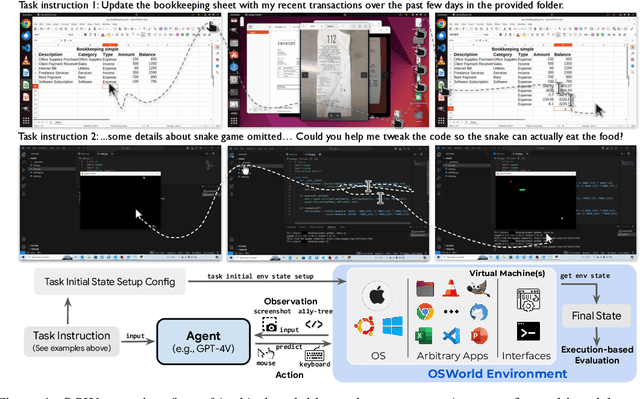

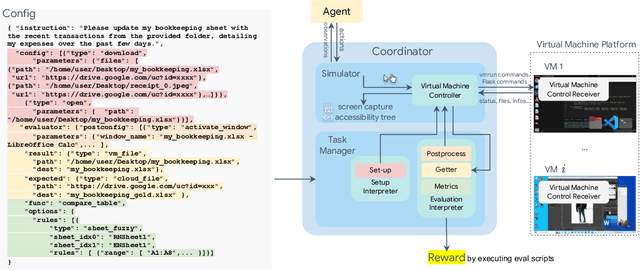

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
What Are Tools Anyway? A Survey from the Language Model Perspective
Mar 18, 2024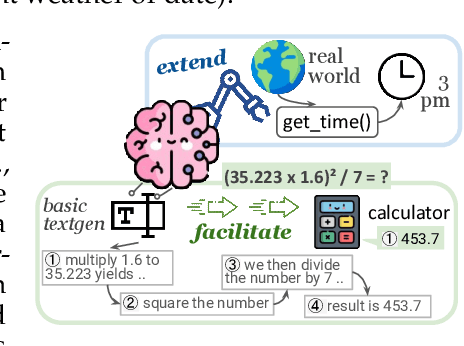
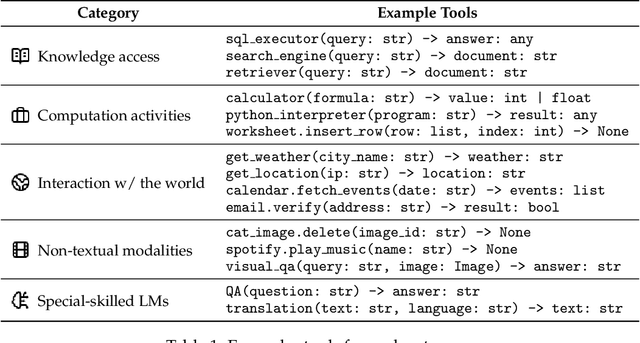
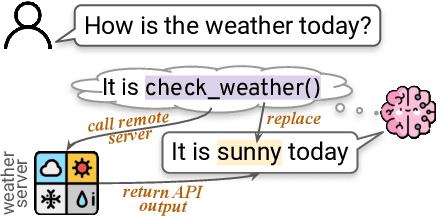
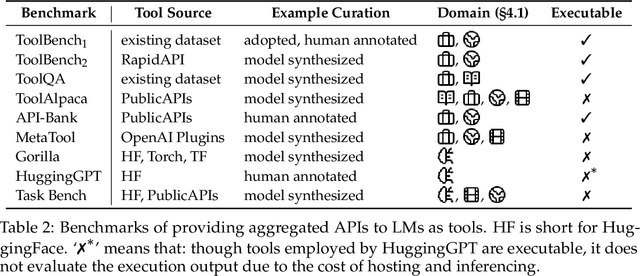
Language models (LMs) are powerful yet mostly for text generation tasks. Tools have substantially enhanced their performance for tasks that require complex skills. However, many works adopt the term "tool" in different ways, raising the question: What is a tool anyway? Subsequently, where and how do tools help LMs? In this survey, we provide a unified definition of tools as external programs used by LMs, and perform a systematic review of LM tooling scenarios and approaches. Grounded on this review, we empirically study the efficiency of various tooling methods by measuring their required compute and performance gains on various benchmarks, and highlight some challenges and potential future research in the field.
OpenAgents: An Open Platform for Language Agents in the Wild
Oct 16, 2023



Language agents show potential in being capable of utilizing natural language for varied and intricate tasks in diverse environments, particularly when built upon large language models (LLMs). Current language agent frameworks aim to facilitate the construction of proof-of-concept language agents while neglecting the non-expert user access to agents and paying little attention to application-level designs. We present OpenAgents, an open platform for using and hosting language agents in the wild of everyday life. OpenAgents includes three agents: (1) Data Agent for data analysis with Python/SQL and data tools; (2) Plugins Agent with 200+ daily API tools; (3) Web Agent for autonomous web browsing. OpenAgents enables general users to interact with agent functionalities through a web user interface optimized for swift responses and common failures while offering developers and researchers a seamless deployment experience on local setups, providing a foundation for crafting innovative language agents and facilitating real-world evaluations. We elucidate the challenges and opportunities, aspiring to set a foundation for future research and development of real-world language agents.
Lemur: Harmonizing Natural Language and Code for Language Agents
Oct 10, 2023We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. https://github.com/OpenLemur/Lemur
Batch Prompting: Efficient Inference with Large Language Model APIs
Jan 19, 2023Performing inference on hundreds of thousands of samples with large language models (LLMs) can be computationally and financially costly. We propose batch prompting, a simple alternative prompting approach that enables the LLM to run inference in batches, instead of one sample at a time. Our method reduces both token and time costs while retaining downstream performance. We theoretically demonstrate that under a few-shot in-context learning setting, the inference costs decrease almost inverse linearly with the number of samples in each batch. We extensively validate the effectiveness of batch prompting on ten datasets across commonsense QA, arithmetic reasoning, and NLI/NLU: batch prompting significantly~(up to $5\times$ with six samples in batch) reduces the LLM (Codex) inference token and time costs while achieving better or comparable performance. Our analysis shows that the number of samples in each batch and the complexity of tasks affect its performance. Further, batch prompting can be applied across different LLMs and reasoning methods.