 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025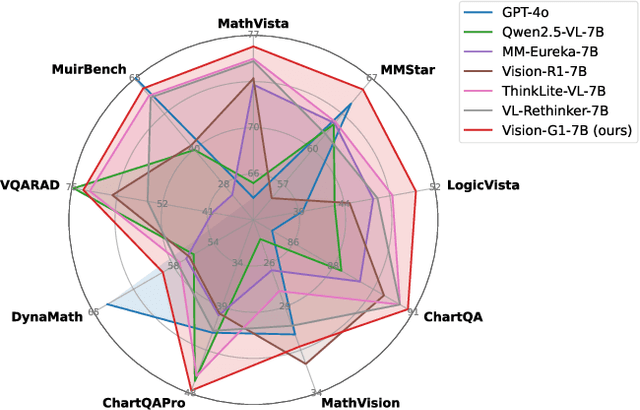
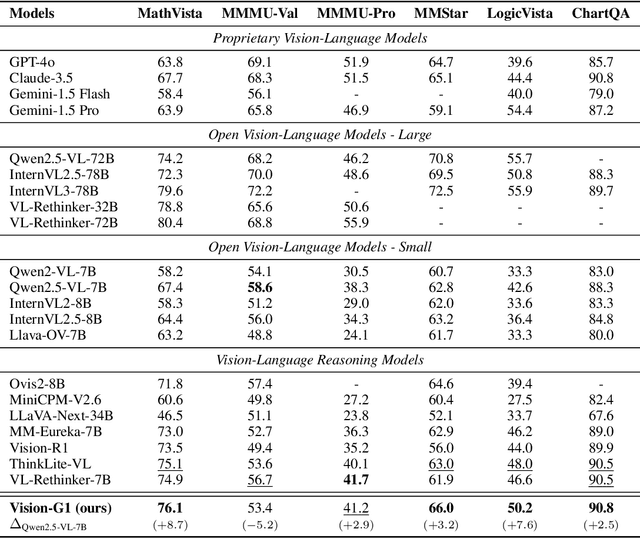
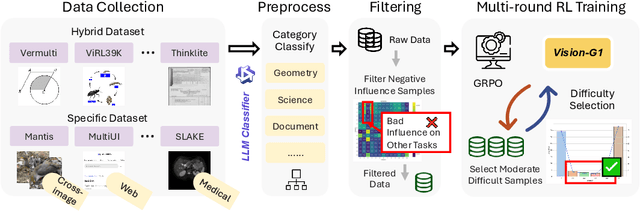
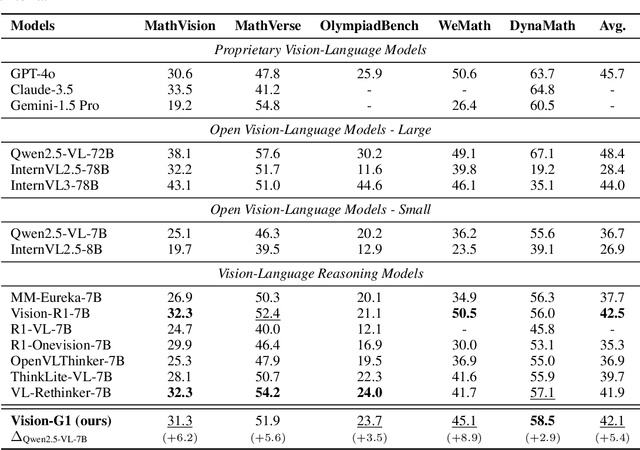
Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025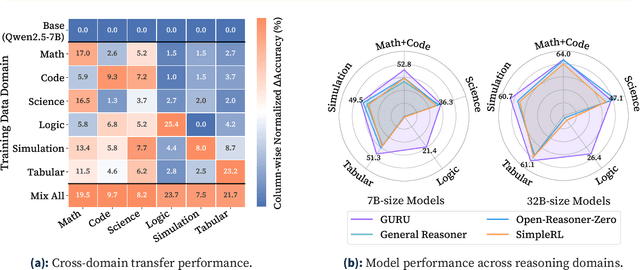
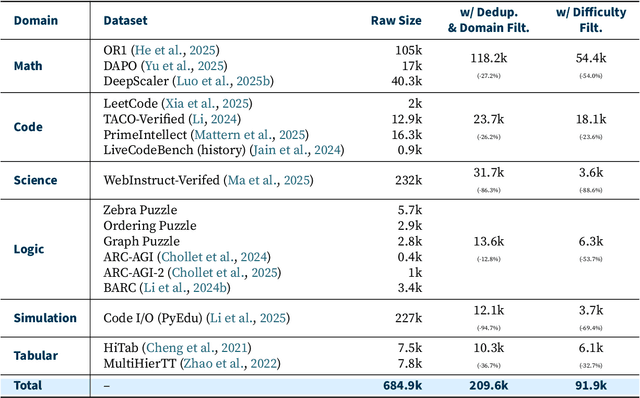
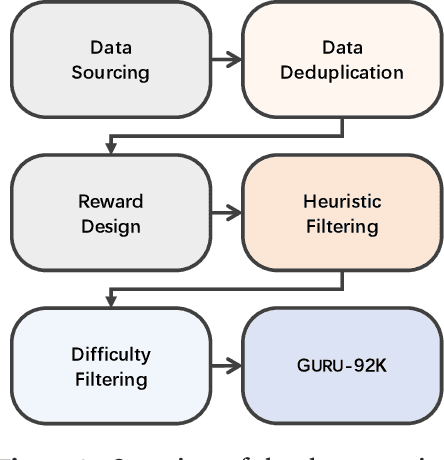

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023

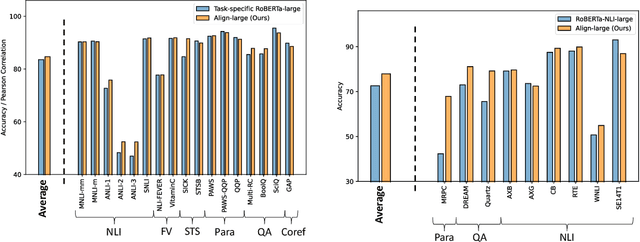

Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
AOMD: An Analogy-aware Approach to Offensive Meme Detection on Social Media
Jun 21, 2021



This paper focuses on an important problem of detecting offensive analogy meme on online social media where the visual content and the texts/captions of the meme together make an analogy to convey the offensive information. Existing offensive meme detection solutions often ignore the implicit relation between the visual and textual contents of the meme and are insufficient to identify the offensive analogy memes. Two important challenges exist in accurately detecting the offensive analogy memes: i) it is not trivial to capture the analogy that is often implicitly conveyed by a meme; ii) it is also challenging to effectively align the complex analogy across different data modalities in a meme. To address the above challenges, we develop a deep learning based Analogy-aware Offensive Meme Detection (AOMD) framework to learn the implicit analogy from the multi-modal contents of the meme and effectively detect offensive analogy memes. We evaluate AOMD on two real-world datasets from online social media. Evaluation results show that AOMD achieves significant performance gains compared to state-of-the-art baselines by detecting offensive analogy memes more accurately.