 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024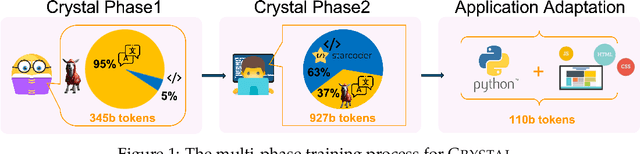
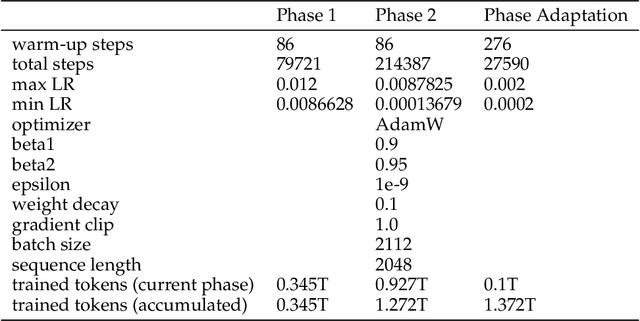
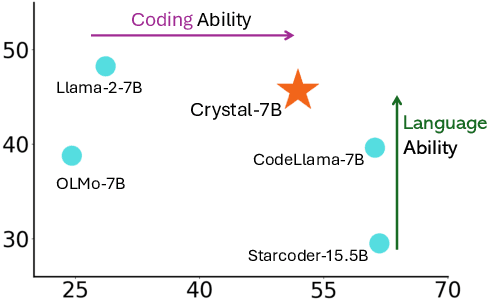
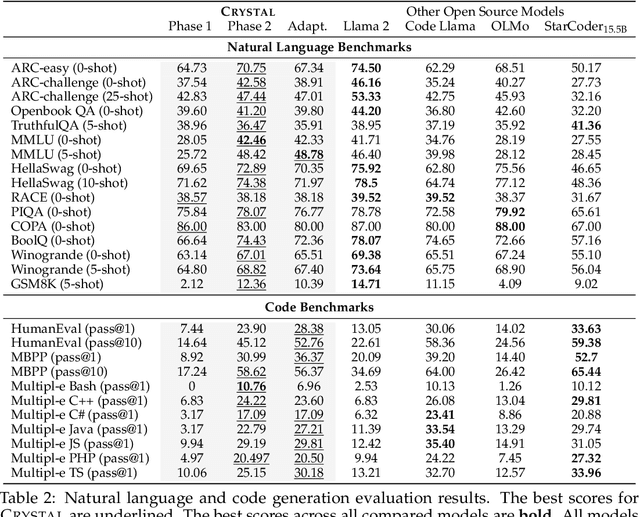
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
SciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
SlimPajama-DC: Understanding Data Combinations for LLM Training
Sep 19, 2023



This paper aims to understand the impacts of various data combinations (e.g., web text, wikipedia, github, books) on the training of large language models using SlimPajama. SlimPajama is a rigorously deduplicated, multi-source dataset, which has been refined and further deduplicated to 627B tokens from the extensive 1.2T tokens RedPajama dataset contributed by Together. We've termed our research as SlimPajama-DC, an empirical analysis designed to uncover fundamental characteristics and best practices associated with employing SlimPajama in the training of large language models. During our research with SlimPajama, two pivotal observations emerged: (1) Global deduplication vs. local deduplication. We analyze and discuss how global (across different sources of datasets) and local (within the single source of dataset) deduplications affect the performance of trained models. (2) Proportions of high-quality/highly-deduplicated multi-source datasets in the combination. To study this, we construct six configurations of SlimPajama dataset and train individual ones using 1.3B Cerebras-GPT model with Alibi and SwiGLU. Our best configuration outperforms the 1.3B model trained on RedPajama using the same number of training tokens by a significant margin. All our 1.3B models are trained on Cerebras 16$\times$ CS-2 cluster with a total of 80 PFLOP/s in bf16 mixed precision. We further extend our discoveries (such as increasing data diversity is crucial after global deduplication) on a 7B model with large batch-size training. Our models and the separate SlimPajama-DC datasets are available at: https://huggingface.co/MBZUAI-LLM and https://huggingface.co/datasets/cerebras/SlimPajama-627B.
Language Models Meet World Models: Embodied Experiences Enhance Language Models
May 22, 2023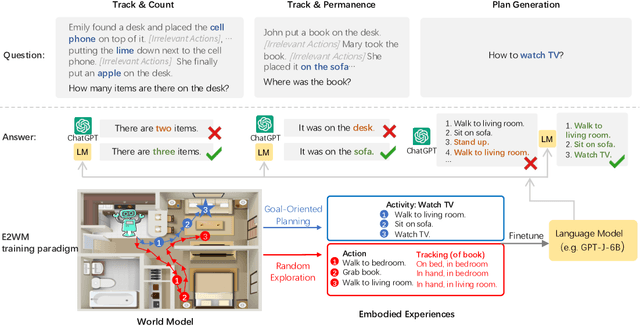

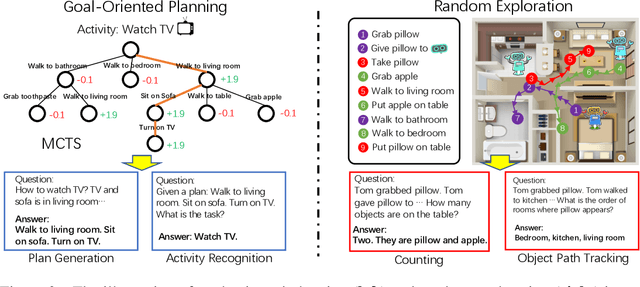
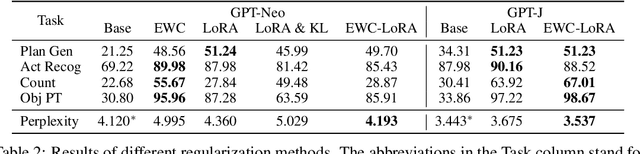
While large language models (LMs) have shown remarkable capabilities across numerous tasks, they often struggle with simple reasoning and planning in physical environments, such as understanding object permanence or planning household activities. The limitation arises from the fact that LMs are trained only on written text and miss essential embodied knowledge and skills. In this paper, we propose a new paradigm of enhancing LMs by finetuning them with world models, to gain diverse embodied knowledge while retaining their general language capabilities. Our approach deploys an embodied agent in a world model, particularly a simulator of the physical world (VirtualHome), and acquires a diverse set of embodied experiences through both goal-oriented planning and random exploration. These experiences are then used to finetune LMs to teach diverse abilities of reasoning and acting in the physical world, e.g., planning and completing goals, object permanence and tracking, etc. Moreover, it is desirable to preserve the generality of LMs during finetuning, which facilitates generalizing the embodied knowledge across tasks rather than being tied to specific simulations. We thus further introduce the classical elastic weight consolidation (EWC) for selective weight updates, combined with low-rank adapters (LoRA) for training efficiency. Extensive experiments show our approach substantially improves base LMs on 18 downstream tasks by 64.28% on average. In particular, the small LMs (1.3B and 6B) enhanced by our approach match or even outperform much larger LMs (e.g., ChatGPT).
On the Learning of Non-Autoregressive Transformers
Jun 13, 2022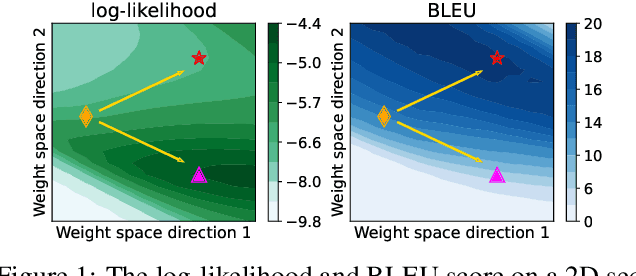


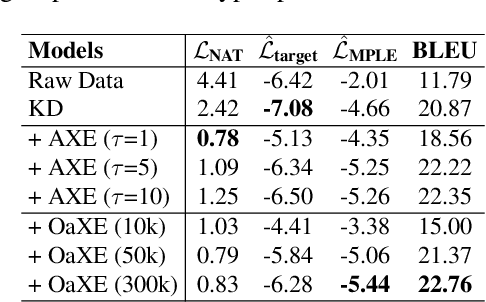
Non-autoregressive Transformer (NAT) is a family of text generation models, which aims to reduce the decoding latency by predicting the whole sentences in parallel. However, such latency reduction sacrifices the ability to capture left-to-right dependencies, thereby making NAT learning very challenging. In this paper, we present theoretical and empirical analyses to reveal the challenges of NAT learning and propose a unified perspective to understand existing successes. First, we show that simply training NAT by maximizing the likelihood can lead to an approximation of marginal distributions but drops all dependencies between tokens, where the dropped information can be measured by the dataset's conditional total correlation. Second, we formalize many previous objectives in a unified framework and show that their success can be concluded as maximizing the likelihood on a proxy distribution, leading to a reduced information loss. Empirical studies show that our perspective can explain the phenomena in NAT learning and guide the design of new training methods.
Don't Take It Literally: An Edit-Invariant Sequence Loss for Text Generation
Jul 23, 2021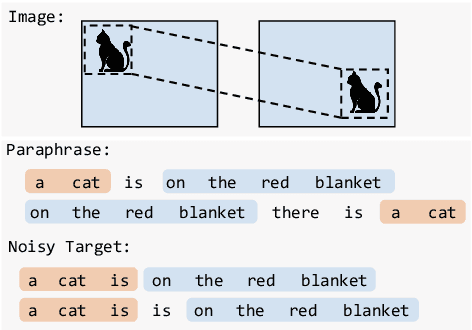
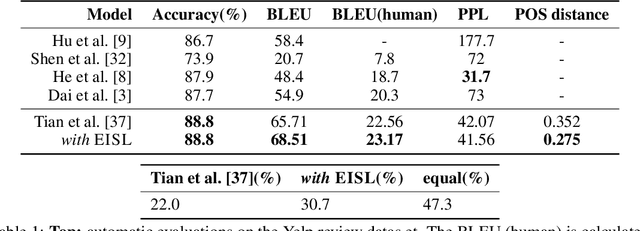
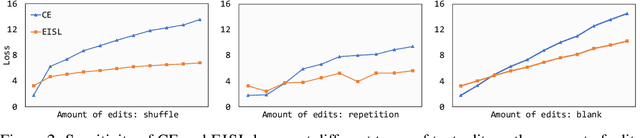
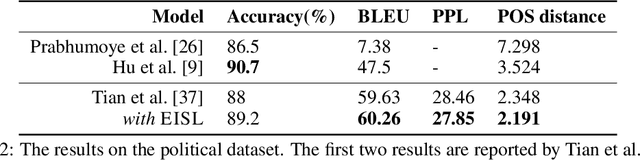
Neural text generation models are typically trained by maximizing log-likelihood with the sequence cross entropy loss, which encourages an exact token-by-token match between a target sequence with a generated sequence. Such training objective is sub-optimal when the target sequence not perfect, e.g., when the target sequence is corrupted with noises, or when only weak sequence supervision is available. To address this challenge, we propose a novel Edit-Invariant Sequence Loss (EISL), which computes the matching loss of a target n-gram with all n-grams in the generated sequence. EISL draws inspirations from convolutional networks (ConvNets) which are shift-invariant to images, hence is robust to the shift of n-grams to tolerate edits in the target sequences. Moreover, the computation of EISL is essentially a convolution operation with target n-grams as kernels, which is easy to implement with existing libraries. To demonstrate the effectiveness of EISL, we conduct experiments on three tasks: machine translation with noisy target sequences, unsupervised text style transfer, and non-autoregressive machine translation. Experimental results show our method significantly outperforms cross entropy loss on these three tasks.