 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating, Reconstructing, and Representing Discrete and Continuous Data: Generalized Diffusion with Learnable Encoding-Decoding
Feb 29, 2024The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), autoregressive models, and diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce generalized diffusion with learnable encoder-decoder (DiLED), that seamlessly integrates the core capabilities for broad applicability and enhanced performance. DiLED generalizes the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, DiLED is compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), DiLED naturally applies to different data types. Extensive experiments on text, proteins, and images demonstrate DiLED's flexibility to handle diverse data and tasks and its strong improvement over various existing models.
Language Models Meet World Models: Embodied Experiences Enhance Language Models
May 22, 2023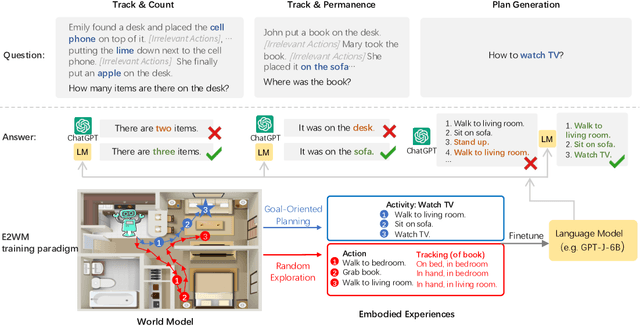

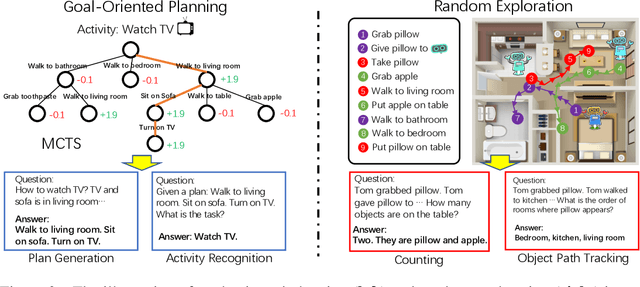
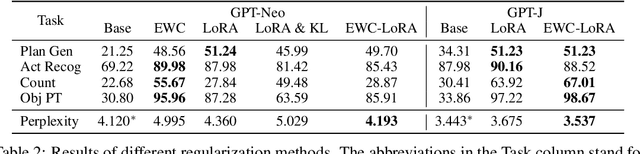
While large language models (LMs) have shown remarkable capabilities across numerous tasks, they often struggle with simple reasoning and planning in physical environments, such as understanding object permanence or planning household activities. The limitation arises from the fact that LMs are trained only on written text and miss essential embodied knowledge and skills. In this paper, we propose a new paradigm of enhancing LMs by finetuning them with world models, to gain diverse embodied knowledge while retaining their general language capabilities. Our approach deploys an embodied agent in a world model, particularly a simulator of the physical world (VirtualHome), and acquires a diverse set of embodied experiences through both goal-oriented planning and random exploration. These experiences are then used to finetune LMs to teach diverse abilities of reasoning and acting in the physical world, e.g., planning and completing goals, object permanence and tracking, etc. Moreover, it is desirable to preserve the generality of LMs during finetuning, which facilitates generalizing the embodied knowledge across tasks rather than being tied to specific simulations. We thus further introduce the classical elastic weight consolidation (EWC) for selective weight updates, combined with low-rank adapters (LoRA) for training efficiency. Extensive experiments show our approach substantially improves base LMs on 18 downstream tasks by 64.28% on average. In particular, the small LMs (1.3B and 6B) enhanced by our approach match or even outperform much larger LMs (e.g., ChatGPT).
FlexMoE: Scaling Large-scale Sparse Pre-trained Model Training via Dynamic Device Placement
Apr 08, 2023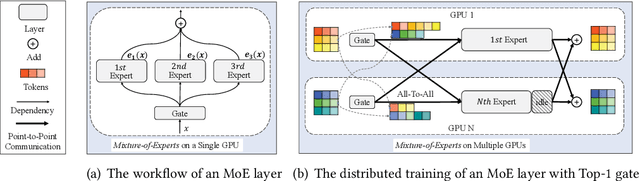

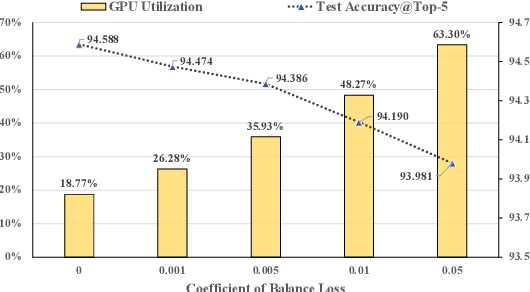
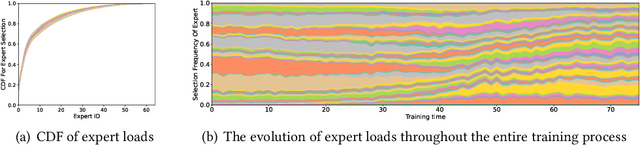
With the increasing data volume, there is a trend of using large-scale pre-trained models to store the knowledge into an enormous number of model parameters. The training of these models is composed of lots of dense algebras, requiring a huge amount of hardware resources. Recently, sparsely-gated Mixture-of-Experts (MoEs) are becoming more popular and have demonstrated impressive pretraining scalability in various downstream tasks. However, such a sparse conditional computation may not be effective as expected in practical systems due to the routing imbalance and fluctuation problems. Generally, MoEs are becoming a new data analytics paradigm in the data life cycle and suffering from unique challenges at scales, complexities, and granularities never before possible. In this paper, we propose a novel DNN training framework, FlexMoE, which systematically and transparently address the inefficiency caused by dynamic dataflow. We first present an empirical analysis on the problems and opportunities of training MoE models, which motivates us to overcome the routing imbalance and fluctuation problems by a dynamic expert management and device placement mechanism. Then we introduce a novel scheduling module over the existing DNN runtime to monitor the data flow, make the scheduling plans, and dynamically adjust the model-to-hardware mapping guided by the real-time data traffic. A simple but efficient heuristic algorithm is exploited to dynamically optimize the device placement during training. We have conducted experiments on both NLP models (e.g., BERT and GPT) and vision models (e.g., Swin). And results show FlexMoE can achieve superior performance compared with existing systems on real-world workloads -- FlexMoE outperforms DeepSpeed by 1.70x on average and up to 2.10x, and outperforms FasterMoE by 1.30x on average and up to 1.45x.
* Accepted by SIGMOD 2023
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
Aug 01, 2022

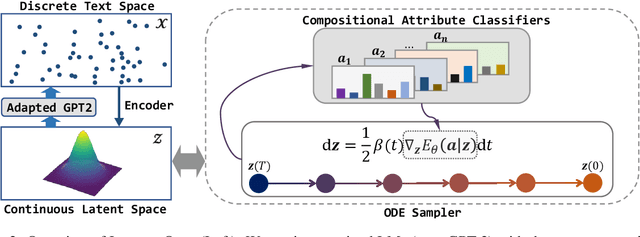
Real-world text applications often involve composing a wide range of text control operations, such as editing the text w.r.t. an attribute, manipulating keywords and structure, and generating new text of desired properties. Prior work typically learns/finetunes a language model (LM) to perform individual or specific subsets of operations. Recent research has studied combining operations in a plug-and-play manner, often with costly search or optimization in the complex sequence space. This paper proposes a new efficient approach for composable text operations in the compact latent space of text. The low-dimensionality and differentiability of the text latent vector allow us to develop an efficient sampler based on ordinary differential equations (ODEs) given arbitrary plug-in operators (e.g., attribute classifiers). By connecting pretrained LMs (e.g., GPT2) to the latent space through efficient adaption, we then decode the sampled vectors into desired text sequences. The flexible approach permits diverse control operators (sentiment, tense, formality, keywords, etc.) acquired using any relevant data from different domains. Experiments show that composing those operators within our approach manages to generate or edit high-quality text, substantially improving over previous methods in terms of generation quality and efficiency.
TreeMix: Compositional Constituency-based Data Augmentation for Natural Language Understanding
May 12, 2022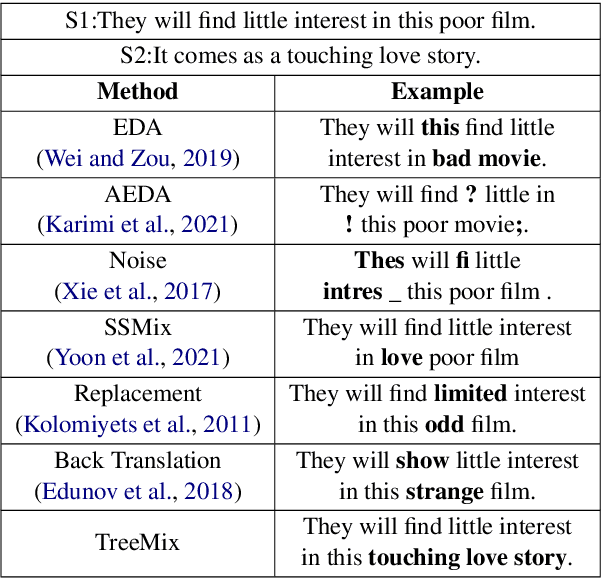
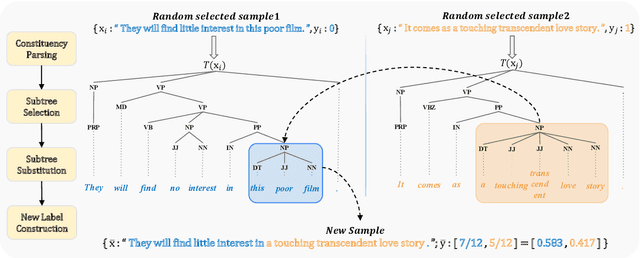

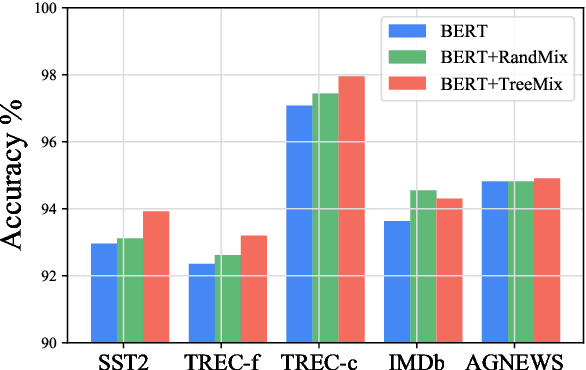
Data augmentation is an effective approach to tackle over-fitting. Many previous works have proposed different data augmentations strategies for NLP, such as noise injection, word replacement, back-translation etc. Though effective, they missed one important characteristic of language--compositionality, meaning of a complex expression is built from its sub-parts. Motivated by this, we propose a compositional data augmentation approach for natural language understanding called TreeMix. Specifically, TreeMix leverages constituency parsing tree to decompose sentences into constituent sub-structures and the Mixup data augmentation technique to recombine them to generate new sentences. Compared with previous approaches, TreeMix introduces greater diversity to the samples generated and encourages models to learn compositionality of NLP data. Extensive experiments on text classification and SCAN demonstrate that TreeMix outperforms current state-of-the-art data augmentation methods.
Dense-to-Sparse Gate for Mixture-of-Experts
Dec 29, 2021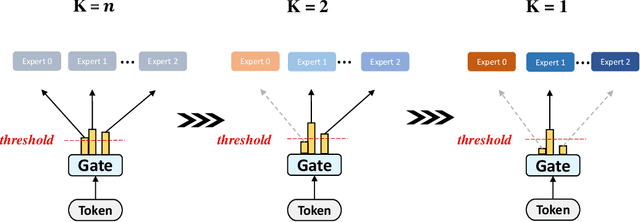

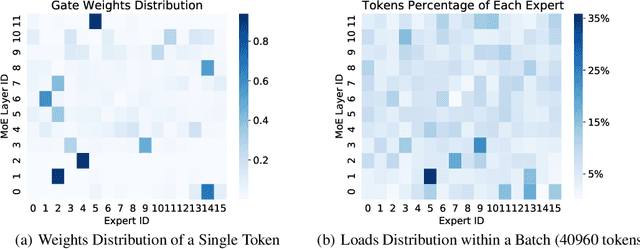
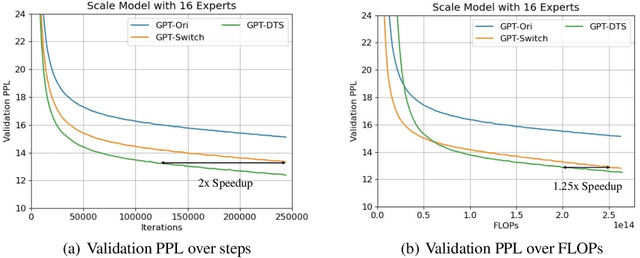
Mixture-of-experts (MoE) is becoming popular due to its success in improving the model quality, especially in Transformers. By routing tokens with a sparse gate to a few experts that each only contains part of the full model, MoE keeps the model size unchanged and significantly reduces per-token computation, which effectively scales neural networks. However, we found that the current approach of jointly training experts and the sparse gate introduces a negative impact on model accuracy, diminishing the efficiency of expensive large-scale model training. In this work, we proposed Dense-To-Sparse gate (DTS-Gate) for MoE training. Specifically, instead of using a permanent sparse gate, DTS-Gate begins as a dense gate that routes tokens to all experts, then gradually and adaptively becomes sparser while routes to fewer experts. MoE with DTS-Gate naturally decouples the training of experts and the sparse gate by training all experts at first and then learning the sparse gate. Experiments show that compared with the state-of-the-art Switch-Gate in GPT-MoE(1.5B) model with OpenWebText dataset(40GB), DTS-Gate can obtain 2.0x speed-up to reach the same validation perplexity, as well as higher FLOPs-efficiency of a 1.42x speed-up.
Don't Take It Literally: An Edit-Invariant Sequence Loss for Text Generation
Jul 23, 2021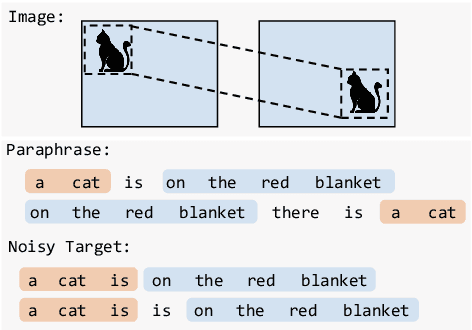
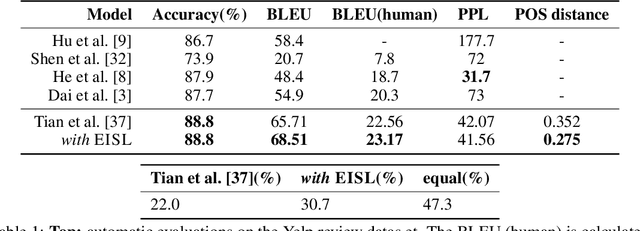
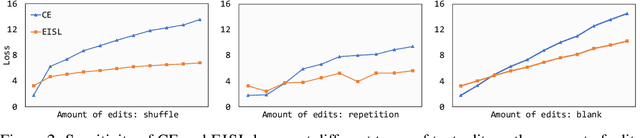
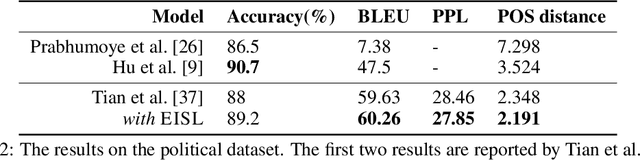
Neural text generation models are typically trained by maximizing log-likelihood with the sequence cross entropy loss, which encourages an exact token-by-token match between a target sequence with a generated sequence. Such training objective is sub-optimal when the target sequence not perfect, e.g., when the target sequence is corrupted with noises, or when only weak sequence supervision is available. To address this challenge, we propose a novel Edit-Invariant Sequence Loss (EISL), which computes the matching loss of a target n-gram with all n-grams in the generated sequence. EISL draws inspirations from convolutional networks (ConvNets) which are shift-invariant to images, hence is robust to the shift of n-grams to tolerate edits in the target sequences. Moreover, the computation of EISL is essentially a convolution operation with target n-grams as kernels, which is easy to implement with existing libraries. To demonstrate the effectiveness of EISL, we conduct experiments on three tasks: machine translation with noisy target sequences, unsupervised text style transfer, and non-autoregressive machine translation. Experimental results show our method significantly outperforms cross entropy loss on these three tasks.
Local Additivity Based Data Augmentation for Semi-supervised NER
Oct 04, 2020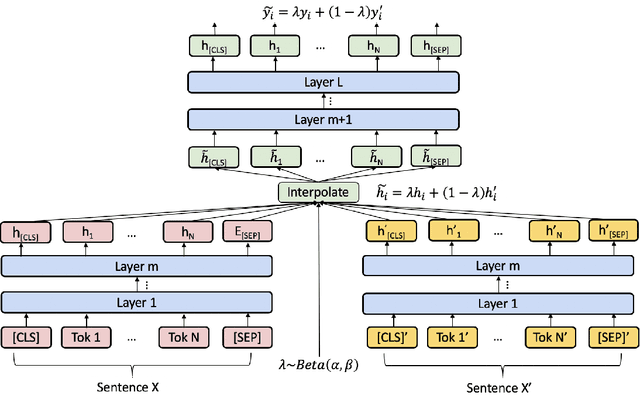

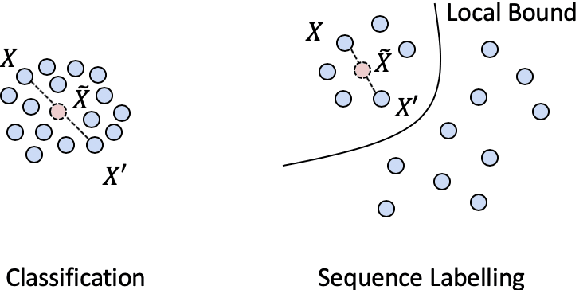
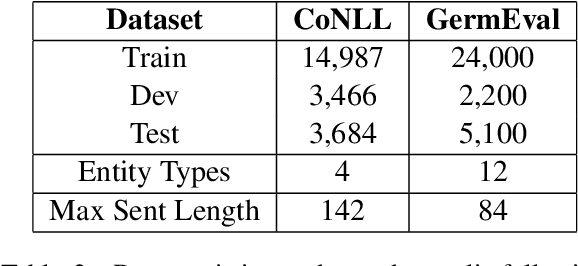
Named Entity Recognition (NER) is one of the first stages in deep language understanding yet current NER models heavily rely on human-annotated data. In this work, to alleviate the dependence on labeled data, we propose a Local Additivity based Data Augmentation (LADA) method for semi-supervised NER, in which we create virtual samples by interpolating sequences close to each other. Our approach has two variations: Intra-LADA and Inter-LADA, where Intra-LADA performs interpolations among tokens within one sentence, and Inter-LADA samples different sentences to interpolate. Through linear additions between sampled training data, LADA creates an infinite amount of labeled data and improves both entity and context learning. We further extend LADA to the semi-supervised setting by designing a novel consistency loss for unlabeled data. Experiments conducted on two NER benchmarks demonstrate the effectiveness of our methods over several strong baselines. We have publicly released our code at https://github.com/GT-SALT/LADA.
Progressive Generation of Long Text
Jun 28, 2020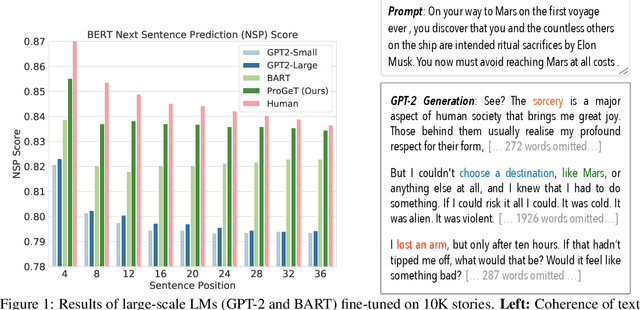
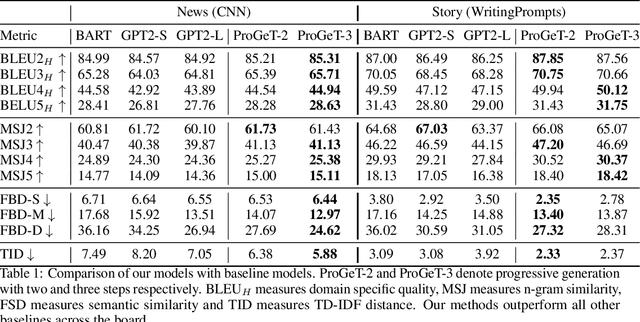
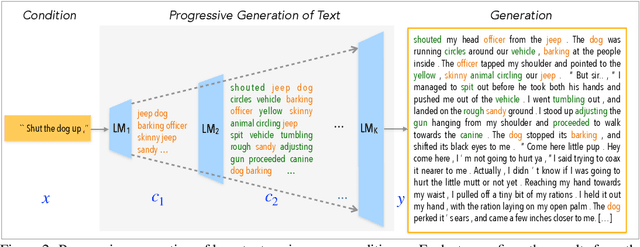
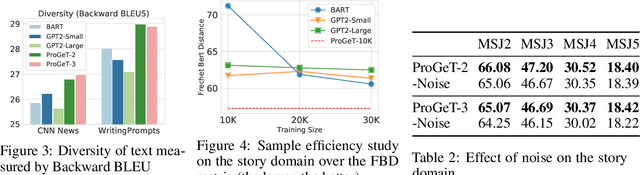
Large-scale language models pretrained on massive corpora of text, such as GPT-2, are powerful open-domain text generators. However, as our systematic examination reveals, it is still challenging for such models to generate coherent long passages of text ($>$1000 tokens), especially when the models are fine-tuned to the target domain on a small corpus. To overcome the limitation, we propose a simple but effective method of generating text in a progressive manner, inspired by generating images from low to high resolution. Our method first produces domain-specific content keywords and then progressively refines them into complete passages in multiple stages. The simple design allows our approach to take advantage of pretrained language models at each stage and effectively adapt to any target domain given only a small set of examples. We conduct a comprehensive empirical study with a broad set of evaluation metrics, and show that our approach significantly improves upon the fine-tuned GPT-2 in terms of domain-specific quality and sample efficiency. The coarse-to-fine nature of progressive generation also allows for a higher degree of control over the generated content.
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
Apr 25, 2020
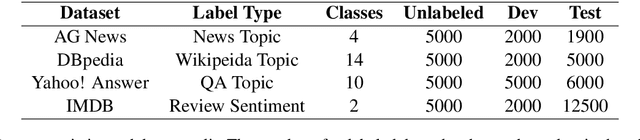
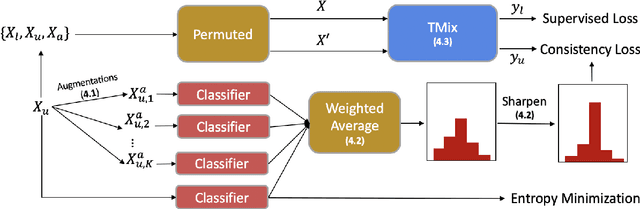
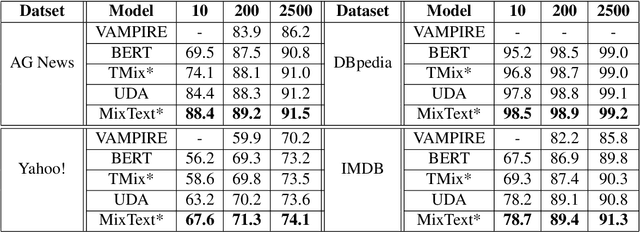
This paper presents MixText, a semi-supervised learning method for text classification, which uses our newly designed data augmentation method called TMix. TMix creates a large amount of augmented training samples by interpolating text in hidden space. Moreover, we leverage recent advances in data augmentation to guess low-entropy labels for unlabeled data, hence making them as easy to use as labeled data.By mixing labeled, unlabeled and augmented data, MixText significantly outperformed current pre-trained and fined-tuned models and other state-of-the-art semi-supervised learning methods on several text classification benchmarks. The improvement is especially prominent when supervision is extremely limited. We have publicly released our code at https://github.com/GT-SALT/MixText.