 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
TileLang: A Composable Tiled Programming Model for AI Systems
Apr 24, 2025Modern AI workloads rely heavily on optimized computing kernels for both training and inference. These AI kernels follow well-defined data-flow patterns, such as moving tiles between DRAM and SRAM and performing a sequence of computations on those tiles. However, writing high-performance kernels remains complex despite the clarity of these patterns. Achieving peak performance requires careful, hardware-centric optimizations to fully leverage modern accelerators. While domain-specific compilers attempt to reduce the burden of writing high-performance kernels, they often struggle with usability and expressiveness gaps. In this paper, we present TileLang, a generalized tiled programming model for more efficient AI Kernel programming. TileLang decouples scheduling space (thread binding, layout, tensorize and pipeline) from dataflow, and encapsulated them as a set of customization annotations and primitives. This approach allows users to focus on the kernel's data-flow itself, while leaving most other optimizations to compilers. We conduct comprehensive experiments on commonly-used devices, across numerous experiments, our evaluation shows that TileLang can achieve state-of-the-art performance in key kernels, demonstrating that its unified block-and-thread paradigm and transparent scheduling capabilities deliver both the power and flexibility demanded by modern AI system development.
AttentionEngine: A Versatile Framework for Efficient Attention Mechanisms on Diverse Hardware Platforms
Feb 21, 2025Transformers and large language models (LLMs) have revolutionized machine learning, with attention mechanisms at the core of their success. As the landscape of attention variants expands, so too do the challenges of optimizing their performance, particularly across different hardware platforms. Current optimization strategies are often narrowly focused, requiring extensive manual intervention to accommodate changes in model configurations or hardware environments. In this paper, we introduce AttentionEngine, a comprehensive framework designed to streamline the optimization of attention mechanisms across heterogeneous hardware backends. By decomposing attention computation into modular operations with customizable components, AttentionEngine enables flexible adaptation to diverse algorithmic requirements. The framework further automates kernel optimization through a combination of programmable templates and a robust cross-platform scheduling strategy. Empirical results reveal performance gains of up to 10x on configurations beyond the reach of existing methods. AttentionEngine offers a scalable, efficient foundation for developing and deploying attention mechanisms with minimal manual tuning. Our code has been open-sourced and is available at https://github.com/microsoft/AttentionEngine.
WaferLLM: A Wafer-Scale LLM Inference System
Feb 06, 2025Emerging AI accelerators increasingly adopt wafer-scale manufacturing technologies, integrating hundreds of thousands of AI cores in a mesh-based architecture with large distributed on-chip memory (tens of GB in total) and ultra-high on-chip memory bandwidth (tens of PB/s). However, current LLM inference systems, optimized for shared memory architectures like GPUs, fail to fully exploit these accelerators. We introduce WaferLLM, the first wafer-scale LLM inference system. WaferLLM is guided by a novel PLMR device model that captures the unique hardware characteristics of wafer-scale architectures. Leveraging this model, WaferLLM pioneers wafer-scale LLM parallelism, optimizing the utilization of hundreds of thousands of on-chip cores. It also introduces MeshGEMM and MeshGEMV, the first GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerators. Evaluations show that WaferLLM achieves 200$\times$ better wafer-scale accelerator utilization than state-of-the-art systems. On a commodity wafer-scale accelerator, WaferLLM delivers 606$\times$ faster and 22$\times$ more energy-efficient GEMV compared to an advanced GPU. For LLMs, WaferLLM enables 39$\times$ faster decoding with 1.7$\times$ better energy efficiency. We anticipate these numbers will grow significantly as wafer-scale AI models, software, and hardware continue to mature.
LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration
Aug 12, 2024As large language model (LLM) inference demands ever-greater resources, there is a rapid growing trend of using low-bit weights to shrink memory usage and boost inference efficiency. However, these low-bit LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), which is a crucial yet under-explored operation that involves multiplying lower-precision weights with higher-precision activations. Unfortunately, current hardware does not natively support mpGEMM, resulting in indirect and inefficient dequantization-based implementations. To address the mpGEMM requirements in low-bit LLMs, we explored the lookup table (LUT)-based approach for mpGEMM. However, a conventional LUT implementation falls short of its potential. To fully harness the power of LUT-based mpGEMM, we introduce LUT Tensor Core, a software-hardware co-design optimized for low-bit LLM inference. Specifically, we introduce software-based operator fusion and table symmetrization techniques to optimize table precompute and table storage, respectively. Then, LUT Tensor Core proposes the hardware design featuring an elongated tiling shape design to enhance table reuse and a bit-serial design to support various precision combinations in mpGEMM. Moreover, we design an end-to-end compilation stack with new instructions for LUT-based mpGEMM, enabling efficient LLM compilation and optimizations. The evaluation on low-bit LLMs (e.g., BitNet, LLAMA) shows that LUT Tensor Core achieves more than a magnitude of improvements on both compute density and energy efficiency.
Scaling Deep Learning Computation over the Inter-Core Connected Intelligence Processor
Aug 09, 2024As AI chips incorporate numerous parallelized cores to scale deep learning (DL) computing, inter-core communication is enabled recently by employing high-bandwidth and low-latency interconnect links on the chip (e.g., Graphcore IPU). It allows each core to directly access the fast scratchpad memory in other cores, which enables new parallel computing paradigms. However, without proper support for the scalable inter-core connections in current DL compilers, it is hard for developers to exploit the benefits of this new architecture. We present T10, the first DL compiler to exploit the inter-core communication bandwidth and distributed on-chip memory on AI chips. To formulate the computation and communication patterns of tensor operators in this new architecture, T10 introduces a distributed tensor abstraction rTensor. T10 maps a DNN model to execution plans with a generalized compute-shift pattern, by partitioning DNN computation into sub-operators and mapping them to cores, so that the cores can exchange data following predictable patterns. T10 makes globally optimized trade-offs between on-chip memory consumption and inter-core communication overhead, selects the best execution plan from a vast optimization space, and alleviates unnecessary inter-core communications. Our evaluation with a real inter-core connected AI chip, the Graphcore IPU, shows up to 3.3$\times$ performance improvement, and scalability support for larger models, compared to state-of-the-art DL compilers and vendor libraries.
T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge
Jun 25, 2024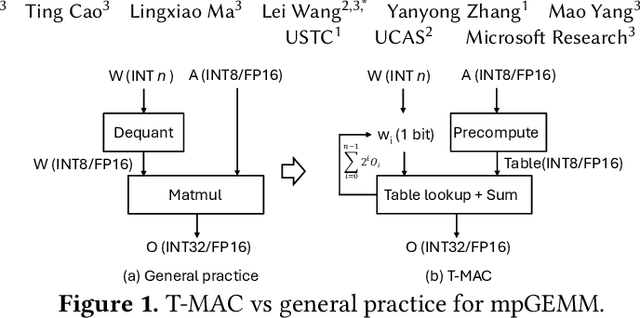

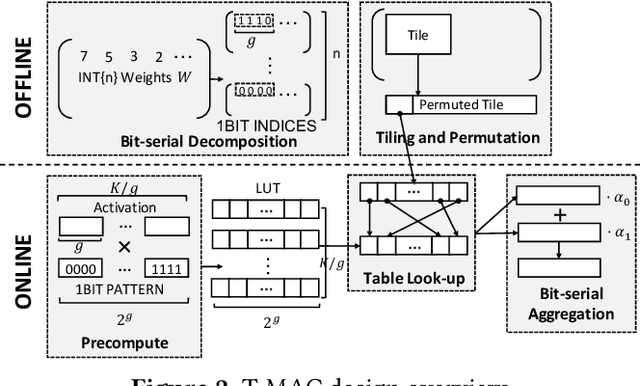

The deployment of Large Language Models (LLMs) on edge devices is increasingly important to enhance on-device intelligence. Weight quantization is crucial for reducing the memory footprint of LLMs on devices. However, low-bit LLMs necessitate mixed precision matrix multiplication (mpGEMM) of low precision weights and high precision activations during inference. Existing systems, lacking native support for mpGEMM, resort to dequantize weights for high precision computation. Such an indirect way can lead to a significant inference overhead. In this paper, we introduce T-MAC, an innovative lookup table(LUT)-based method designed for efficient low-bit LLM (i.e., weight-quantized LLM) inference on CPUs. T-MAC directly supports mpGEMM without dequantization, while simultaneously eliminating multiplications and reducing additions required. Specifically, T-MAC transforms the traditional data-type-centric multiplication to bit-wise table lookup, and enables a unified and scalable mpGEMM solution. Our LUT-based kernels scale linearly to the weight bit-width. Evaluated on low-bit Llama and BitNet models, T-MAC demonstrates up to 4x increase in throughput and 70% reduction in energy consumption compared to llama.cpp. For BitNet-b1.58-3B, T-MAC delivers a token generation throughput of 30 tokens/s with a single core and 71 tokens/s with eight cores on M2-Ultra, and 11 tokens/s on lower-end devices like Raspberry Pi 5, which significantly exceeds the adult average reading speed. T-MAC with LUT-based computing paradigm, paves the way for the practical deployment of low-bit LLMs on resource-constrained edge devices without compromising computational efficiency. The system is open-sourced at https://github.com/microsoft/T-MAC.
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Feb 27, 2024Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
BitNet: Scaling 1-bit Transformers for Large Language Models
Oct 17, 2023The increasing size of large language models has posed challenges for deployment and raised concerns about environmental impact due to high energy consumption. In this work, we introduce BitNet, a scalable and stable 1-bit Transformer architecture designed for large language models. Specifically, we introduce BitLinear as a drop-in replacement of the nn.Linear layer in order to train 1-bit weights from scratch. Experimental results on language modeling show that BitNet achieves competitive performance while substantially reducing memory footprint and energy consumption, compared to state-of-the-art 8-bit quantization methods and FP16 Transformer baselines. Furthermore, BitNet exhibits a scaling law akin to full-precision Transformers, suggesting its potential for effective scaling to even larger language models while maintaining efficiency and performance benefits.
FlexMoE: Scaling Large-scale Sparse Pre-trained Model Training via Dynamic Device Placement
Apr 08, 2023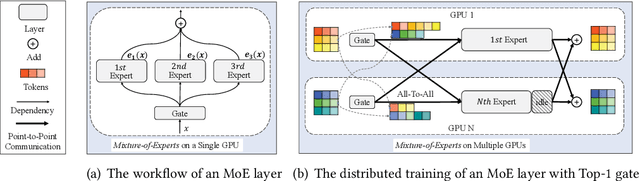

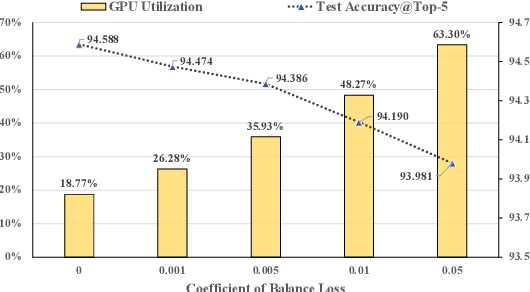
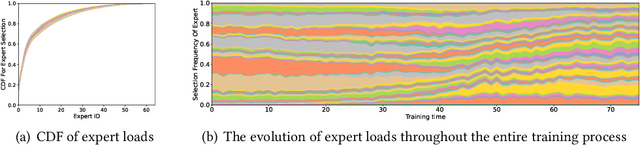
With the increasing data volume, there is a trend of using large-scale pre-trained models to store the knowledge into an enormous number of model parameters. The training of these models is composed of lots of dense algebras, requiring a huge amount of hardware resources. Recently, sparsely-gated Mixture-of-Experts (MoEs) are becoming more popular and have demonstrated impressive pretraining scalability in various downstream tasks. However, such a sparse conditional computation may not be effective as expected in practical systems due to the routing imbalance and fluctuation problems. Generally, MoEs are becoming a new data analytics paradigm in the data life cycle and suffering from unique challenges at scales, complexities, and granularities never before possible. In this paper, we propose a novel DNN training framework, FlexMoE, which systematically and transparently address the inefficiency caused by dynamic dataflow. We first present an empirical analysis on the problems and opportunities of training MoE models, which motivates us to overcome the routing imbalance and fluctuation problems by a dynamic expert management and device placement mechanism. Then we introduce a novel scheduling module over the existing DNN runtime to monitor the data flow, make the scheduling plans, and dynamically adjust the model-to-hardware mapping guided by the real-time data traffic. A simple but efficient heuristic algorithm is exploited to dynamically optimize the device placement during training. We have conducted experiments on both NLP models (e.g., BERT and GPT) and vision models (e.g., Swin). And results show FlexMoE can achieve superior performance compared with existing systems on real-world workloads -- FlexMoE outperforms DeepSpeed by 1.70x on average and up to 2.10x, and outperforms FasterMoE by 1.30x on average and up to 1.45x.
* Accepted by SIGMOD 2023