 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Kernel Fusion for Transformers
Feb 12, 2026Agentic LLM inference with long contexts is increasingly limited by memory bandwidth rather than compute. In this setting, SwiGLU MLP blocks, whose large weights exceed cache capacity, become a major yet under-optimized bottleneck. We propose DeepFusionKernel, a deeply fused kernel that cuts HBM traffic and boosts cache reuse, delivering up to 13.2% speedup on H100 and 9.7% on A100 over SGLang. Integrated with SGLang and paired with a kernel scheduler, DeepFusionKernel ensures consistent accelerations over generation lengths, while remaining adaptable to diverse models, inference configurations, and hardware platforms.
Dynamic Expert Sharing: Decoupling Memory from Parallelism in Mixture-of-Experts Diffusion LLMs
Jan 31, 2026Among parallel decoding paradigms, diffusion large language models (dLLMs) have emerged as a promising candidate that balances generation quality and throughput. However, their integration with Mixture-of-Experts (MoE) architectures is constrained by an expert explosion: as the number of tokens generated in parallel increases, the number of distinct experts activated grows nearly linearly. This results in substantial memory traffic that pushes inference into a memory-bound regime, negating the efficiency gains of both MoE and parallel decoding. To address this challenge, we propose Dynamic Expert Sharing (DES), a novel technique that shifts MoE optimization from token-centric pruning and conventional expert skipping methods to sequence-level coreset selection. To maximize expert reuse, DES identifies a compact, high-utility set of experts to satisfy the requirements of an entire parallel decoding block. We introduce two innovative selection strategies: (1) Intra-Sequence Sharing (DES-Seq), which adapts optimal allocation to the sequence level, and (2) Saliency-Aware Voting (DES-Vote), a novel mechanism that allows tokens to collectively elect a coreset based on aggregated router weights. Extensive experiments on MoE dLLMs demonstrate that DES reduces unique expert activations by over 55% and latency by up to 38%, while retaining 99% of vanilla accuracy, effectively decoupling memory overhead from the degree of parallelism.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025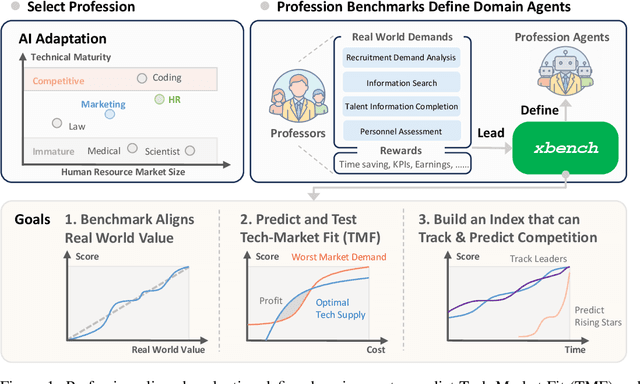

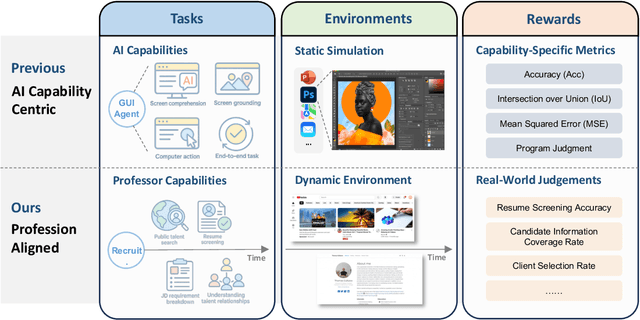
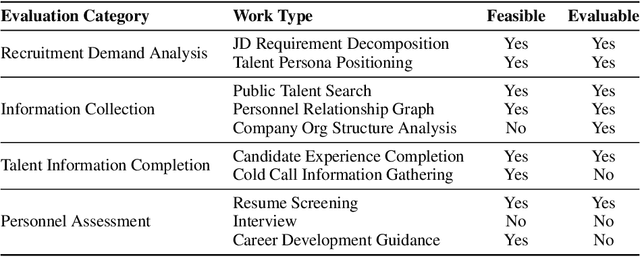
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Rethinking Optimal Verification Granularity for Compute-Efficient Test-Time Scaling
May 16, 2025Test-time scaling (TTS) has proven effective in enhancing the reasoning capabilities of large language models (LLMs). Verification plays a key role in TTS, simultaneously influencing (1) reasoning performance and (2) compute efficiency, due to the quality and computational cost of verification. In this work, we challenge the conventional paradigms of verification, and make the first attempt toward systematically investigating the impact of verification granularity-that is, how frequently the verifier is invoked during generation, beyond verifying only the final output or individual generation steps. To this end, we introduce Variable Granularity Search (VG-Search), a unified algorithm that generalizes beam search and Best-of-N sampling via a tunable granularity parameter g. Extensive experiments with VG-Search under varying compute budgets, generator-verifier configurations, and task attributes reveal that dynamically selecting g can improve the compute efficiency and scaling behavior. Building on these findings, we propose adaptive VG-Search strategies that achieve accuracy gains of up to 3.1\% over Beam Search and 3.6\% over Best-of-N, while reducing FLOPs by over 52\%. We will open-source the code to support future research.
TileLang: A Composable Tiled Programming Model for AI Systems
Apr 24, 2025Modern AI workloads rely heavily on optimized computing kernels for both training and inference. These AI kernels follow well-defined data-flow patterns, such as moving tiles between DRAM and SRAM and performing a sequence of computations on those tiles. However, writing high-performance kernels remains complex despite the clarity of these patterns. Achieving peak performance requires careful, hardware-centric optimizations to fully leverage modern accelerators. While domain-specific compilers attempt to reduce the burden of writing high-performance kernels, they often struggle with usability and expressiveness gaps. In this paper, we present TileLang, a generalized tiled programming model for more efficient AI Kernel programming. TileLang decouples scheduling space (thread binding, layout, tensorize and pipeline) from dataflow, and encapsulated them as a set of customization annotations and primitives. This approach allows users to focus on the kernel's data-flow itself, while leaving most other optimizations to compilers. We conduct comprehensive experiments on commonly-used devices, across numerous experiments, our evaluation shows that TileLang can achieve state-of-the-art performance in key kernels, demonstrating that its unified block-and-thread paradigm and transparent scheduling capabilities deliver both the power and flexibility demanded by modern AI system development.
LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration
Aug 12, 2024As large language model (LLM) inference demands ever-greater resources, there is a rapid growing trend of using low-bit weights to shrink memory usage and boost inference efficiency. However, these low-bit LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), which is a crucial yet under-explored operation that involves multiplying lower-precision weights with higher-precision activations. Unfortunately, current hardware does not natively support mpGEMM, resulting in indirect and inefficient dequantization-based implementations. To address the mpGEMM requirements in low-bit LLMs, we explored the lookup table (LUT)-based approach for mpGEMM. However, a conventional LUT implementation falls short of its potential. To fully harness the power of LUT-based mpGEMM, we introduce LUT Tensor Core, a software-hardware co-design optimized for low-bit LLM inference. Specifically, we introduce software-based operator fusion and table symmetrization techniques to optimize table precompute and table storage, respectively. Then, LUT Tensor Core proposes the hardware design featuring an elongated tiling shape design to enhance table reuse and a bit-serial design to support various precision combinations in mpGEMM. Moreover, we design an end-to-end compilation stack with new instructions for LUT-based mpGEMM, enabling efficient LLM compilation and optimizations. The evaluation on low-bit LLMs (e.g., BitNet, LLAMA) shows that LUT Tensor Core achieves more than a magnitude of improvements on both compute density and energy efficiency.