 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025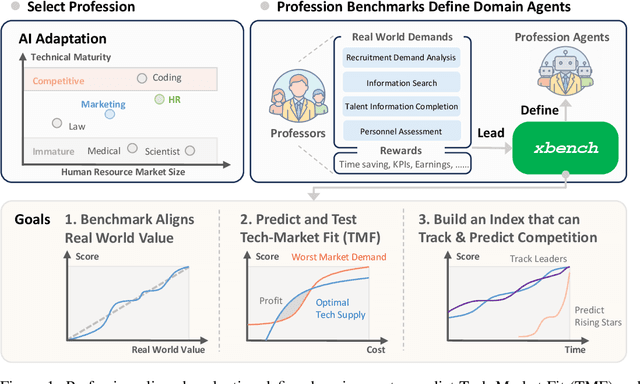

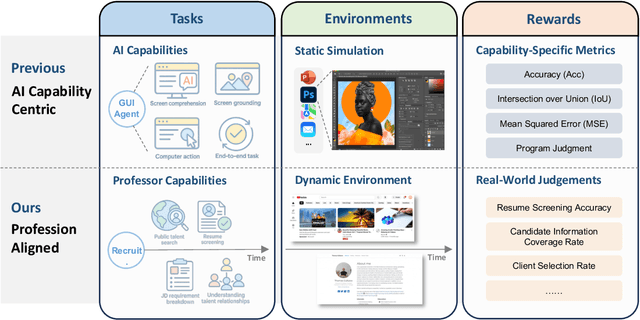
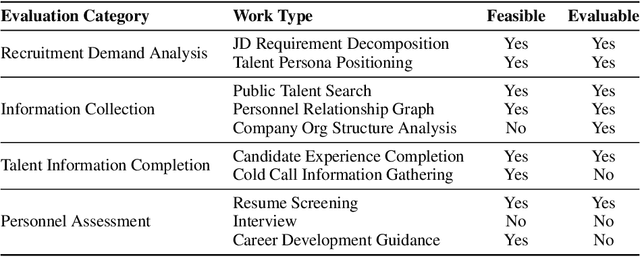
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Building Category Graphs Representation with Spatial and Temporal Attention for Visual Navigation
Dec 06, 2023



Given an object of interest, visual navigation aims to reach the object's location based on a sequence of partial observations. To this end, an agent needs to 1) learn a piece of certain knowledge about the relations of object categories in the world during training and 2) look for the target object based on the pre-learned object category relations and its moving trajectory in the current unseen environment. In this paper, we propose a Category Relation Graph (CRG) to learn the knowledge of object category layout relations and a Temporal-Spatial-Region (TSR) attention architecture to perceive the long-term spatial-temporal dependencies of objects helping the navigation. We learn prior knowledge of object layout, establishing a category relationship graph to deduce the positions of specific objects. Subsequently, we introduced TSR to capture the relationships of objects in temporal, spatial, and regions within the observation trajectories. Specifically, we propose a Temporal attention module (T) to model the temporal structure of the observation sequence, which implicitly encodes the historical moving or trajectory information. Then, a Spatial attention module (S) is used to uncover the spatial context of the current observation objects based on the category relation graph and past observations. Last, a Region attention module (R) shifts the attention to the target-relevant region. Based on the visual representation extracted by our method, the agent can better perceive the environment and easily learn superior navigation policy. Experiments on AI2-THOR demonstrate our CRG-TSR method significantly outperforms existing methods regarding both effectiveness and efficiency. The code has been included in the supplementary material and will be publicly available.
A Reliable Representation with Bidirectional Transition Model for Visual Reinforcement Learning Generalization
Dec 04, 2023Visual reinforcement learning has proven effective in solving control tasks with high-dimensional observations. However, extracting reliable and generalizable representations from vision-based observations remains a central challenge. Inspired by the human thought process, when the representation extracted from the observation can predict the future and trace history, the representation is reliable and accurate in comprehending the environment. Based on this concept, we introduce a Bidirectional Transition (BiT) model, which leverages the ability to bidirectionally predict environmental transitions both forward and backward to extract reliable representations. Our model demonstrates competitive generalization performance and sample efficiency on two settings of the DeepMind Control suite. Additionally, we utilize robotic manipulation and CARLA simulators to demonstrate the wide applicability of our method.
PyramidFlow: High-Resolution Defect Contrastive Localization using Pyramid Normalizing Flow
Mar 05, 2023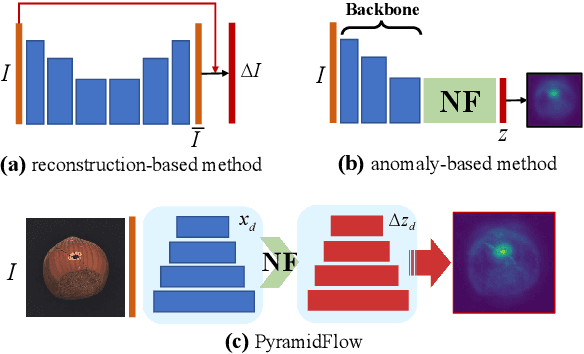



During industrial processing, unforeseen defects may arise in products due to uncontrollable factors. Although unsupervised methods have been successful in defect localization, the usual use of pre-trained models results in low-resolution outputs, which damages visual performance. To address this issue, we propose PyramidFlow, the first fully normalizing flow method without pre-trained models that enables high-resolution defect localization. Specifically, we propose a latent template-based defect contrastive localization paradigm to reduce intra-class variance, as the pre-trained models do. In addition, PyramidFlow utilizes pyramid-like normalizing flows for multi-scale fusing and volume normalization to help generalization. Our comprehensive studies on MVTecAD demonstrate the proposed method outperforms the comparable algorithms that do not use external priors, even achieving state-of-the-art performance in more challenging BTAD scenarios.
Agent-Centric Relation Graph for Object Visual Navigation
Dec 07, 2021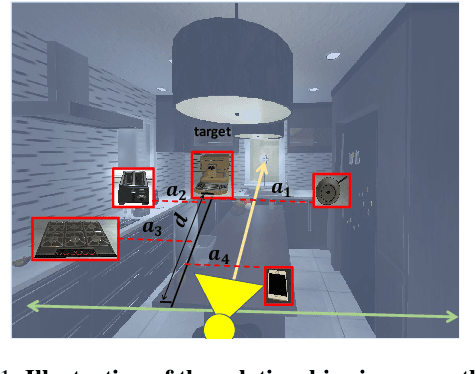
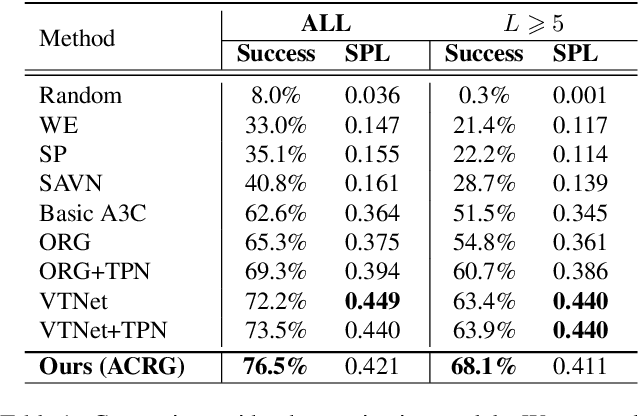
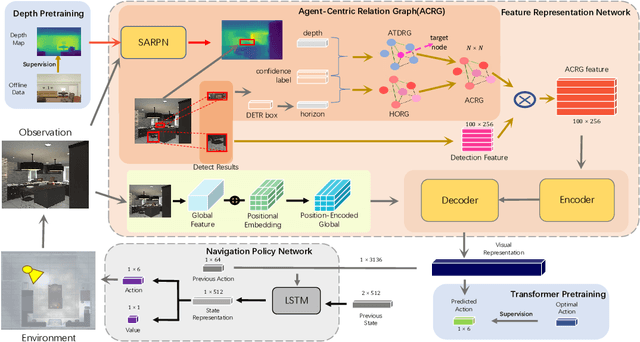
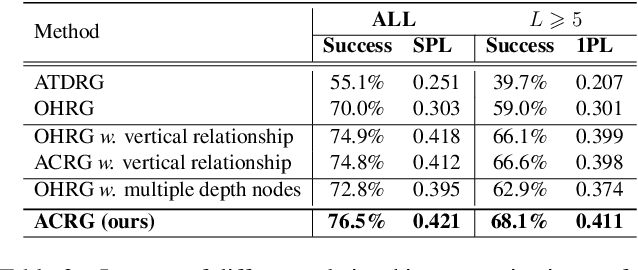
Object visual navigation aims to steer an agent towards a target object based on visual observations of the agent. It is highly desirable to reasonably perceive the environment and accurately control the agent. In the navigation task, we introduce an Agent-Centric Relation Graph (ACRG) for learning the visual representation based on the relationships in the environment. ACRG is a highly effective and reasonable structure that consists of two relationships, i.e., the relationship among objects and the relationship between the agent and the target. On the one hand, we design the Object Horizontal Relationship Graph (OHRG) that stores the relative horizontal location among objects. Note that the vertical relationship is not involved in OHRG, and we argue that OHRG is suitable for the control strategy. On the other hand, we propose the Agent-Target Depth Relationship Graph (ATDRG) that enables the agent to perceive the distance to the target. To achieve ATDRG, we utilize image depth to represent the distance. Given the above relationships, the agent can perceive the environment and output navigation actions. Given the visual representations constructed by ACRG and position-encoded global features, the agent can capture the target position to perform navigation actions. Experimental results in the artificial environment AI2-Thor demonstrate that ACRG significantly outperforms other state-of-the-art methods in unseen testing environments.