 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom In, Reason Out: Efficient Far-field Anomaly Detection in Expressway Surveillance Videos via Focused VLM Reasoning Guided by Bayesian Inference
Apr 28, 2026Expressway video anomaly detection is essential for safety management. However, identifying anomalies across diverse scenes remains challenging, particularly for far-field targets exhibiting subtle abnormal vehicle motions. While Vision-Language Models (VLMs) demonstrate strong semantic reasoning capabilities, processing global frames causes attention dilution for these far-field objects and incurs prohibitive computational costs. To address these issues, we propose VIBES, an asynchronous collaborative framework utilizing VLMs guided by Bayesian inference. Specifically, to overcome poor generalization across varying expressway environments, we introduce an online Bayesian inference module. This module continuously evaluates vehicle trajectories to dynamically update the probabilistic boundaries of normal driving behaviors, serving as an asynchronous trigger to precisely localize anomalies in space and time. Instead of processing the continuous video stream, the VLM processes only the localized visual regions indicated by the trigger. This targeted visual input prevents attention dilution and enables accurate semantic reasoning. Extensive evaluations demonstrate that VIBES improves detection accuracy for far-field anomalies and reduces computational overhead, achieving high real-time efficiency and explainability while demonstrating generalization across diverse expressway conditions.
STK-Adapter: Incorporating Evolving Graph and Event Chain for Temporal Knowledge Graph Extrapolation
Apr 21, 2026Temporal Knowledge Graph (TKG) extrapolation aims to predict future events based on historical facts. Recent studies have attempted to enhance TKG extrapolation by integrating TKG's evolving structural representations and textual event chains into Large Language Models (LLMs). Yet, two main challenges limit these approaches: (1) The loss of essential spatial-temporal information due to shallow alignment between TKG's graph evolving structural representation and the LLM's semantic space, and (2) the progressive dilution of the TKG's evolving structural features during LLM fine-tuning. To address these challenges, we propose the Spatial-Temporal Knowledge Adapter (STK-Adapter), which flexibly integrates the evolving graph encoder and the LLM to facilitate TKG reasoning. In STK-Adapter, a Spatial-Temporal MoE is designed to capture spatial structures and temporal patterns inherent in TKGs. An Event-Aware MoE is employed to model intricate temporal semantics dependencies within event chains. In addition, a Cross-Modality Alignment MoE is proposed to facilitate deep cross-modality alignment by TKG-guided attention experts. Extensive experiments on benchmark datasets demonstrate that STK-Adapter significantly outperforms state-of-the-art methods and exhibits strong generalization capabilities in cross-dataset task. The code is available at https://github.com/Zhaoshuyuan0246/STK-Adapter.
DiSGMM: A Method for Time-varying Microscopic Weight Completion on Road Networks
Mar 31, 2026Microscopic road-network weights represent fine-grained, time-varying traffic conditions obtained from individual vehicles. An example is travel speeds associated with road segments as vehicles traverse them. These weights support tasks including traffic microsimulation and vehicle routing with reliability guarantees. We study the problem of time-varying microscopic weight completion. During a time slot, the available weights typically cover only some road segments. Weight completion recovers distributions for the weights of every road segment at the current time slot. This problem involves two challenges: (i) contending with two layers of sparsity, where weights are missing at both the network layer (many road segments lack weights) and the segment layer (a segment may have insufficient weights to enable accurate distribution estimation); and (ii) achieving a weight distribution representation that is closed-form and can capture complex conditions flexibly, including heavy tails and multiple clusters. To address these challenges, we propose DiSGMM that combines sparsity-aware embeddings with spatiotemporal modeling to leverage sparse known weights alongside learned segment properties and long-range correlations for distribution estimation. DiSGMM represents distributions of microscopic weights as learnable Gaussian mixture models, providing closed-form distributions capable of capturing complex conditions flexibly. Experiments on two real-world datasets show that DiSGMM can outperform state-of-the-art methods.
Towards Effective and Efficient Graph Alignment without Supervision
Mar 09, 2026Unsupervised graph alignment aims to find the node correspondence across different graphs without any anchor node pairs. Despite the recent efforts utilizing deep learning-based techniques, such as the embedding and optimal transport (OT)-based approaches, we observe their limitations in terms of model accuracy-efficiency tradeoff. By focusing on the exploitation of local and global graph information, we formalize them as the ``local representation, global alignment'' paradigm, and present a new ``global representation and alignment'' paradigm to resolve the mismatch between the two phases in the alignment process. We then propose \underline{Gl}obal representation and \underline{o}ptimal transport-\underline{b}ased \underline{Align}ment (\texttt{GlobAlign}), and its variant, \texttt{GlobAlign-E}, for better \underline{E}fficiency. Our methods are equipped with the global attention mechanism and a hierarchical cross-graph transport cost, able to capture long-range and implicit node dependencies beyond the local graph structure. Furthermore, \texttt{GlobAlign-E} successfully closes the time complexity gap between representative embedding and OT-based methods, reducing OT's cubic complexity to quadratic terms. Through extensive experiments, our methods demonstrate superior performance, with up to a 20\% accuracy improvement over the best competitor. Meanwhile, \texttt{GlobAlign-E} achieves the best efficiency, with an order of magnitude speedup against existing OT-based methods.
DRFormer: A Dual-Regularized Bidirectional Transformer for Person Re-identification
Feb 01, 2026Both fine-grained discriminative details and global semantic features can contribute to solving person re-identification challenges, such as occlusion and pose variations. Vision foundation models (\textit{e.g.}, DINO) excel at mining local textures, and vision-language models (\textit{e.g.}, CLIP) capture strong global semantic difference. Existing methods predominantly rely on a single paradigm, neglecting the potential benefits of their integration. In this paper, we analyze the complementary roles of these two architectures and propose a framework to synergize their strengths by a \textbf{D}ual-\textbf{R}egularized Bidirectional \textbf{Transformer} (\textbf{DRFormer}). The dual-regularization mechanism ensures diverse feature extraction and achieves a better balance in the contributions of the two models. Extensive experiments on five benchmarks show that our method effectively harmonizes local and global representations, achieving competitive performance against state-of-the-art methods.
RIPCN: A Road Impedance Principal Component Network for Probabilistic Traffic Flow Forecasting
Dec 25, 2025Accurate traffic flow forecasting is crucial for intelligent transportation services such as navigation and ride-hailing. In such applications, uncertainty estimation in forecasting is important because it helps evaluate traffic risk levels, assess forecast reliability, and provide timely warnings. As a result, probabilistic traffic flow forecasting (PTFF) has gained significant attention, as it produces both point forecasts and uncertainty estimates. However, existing PTFF approaches still face two key challenges: (1) how to uncover and model the causes of traffic flow uncertainty for reliable forecasting, and (2) how to capture the spatiotemporal correlations of uncertainty for accurate prediction. To address these challenges, we propose RIPCN, a Road Impedance Principal Component Network that integrates domain-specific transportation theory with spatiotemporal principal component learning for PTFF. RIPCN introduces a dynamic impedance evolution network that captures directional traffic transfer patterns driven by road congestion level and flow variability, revealing the direct causes of uncertainty and enhancing both reliability and interpretability. In addition, a principal component network is designed to forecast the dominant eigenvectors of future flow covariance, enabling the model to capture spatiotemporal uncertainty correlations. This design allows for accurate and efficient uncertainty estimation while also improving point prediction performance. Experimental results on real-world datasets show that our approach outperforms existing probabilistic forecasting methods.
A Generative Adaptive Replay Continual Learning Model for Temporal Knowledge Graph Reasoning
Jun 04, 2025Recent Continual Learning (CL)-based Temporal Knowledge Graph Reasoning (TKGR) methods focus on significantly reducing computational cost and mitigating catastrophic forgetting caused by fine-tuning models with new data. However, existing CL-based TKGR methods still face two key limitations: (1) They usually one-sidedly reorganize individual historical facts, while overlooking the historical context essential for accurately understanding the historical semantics of these facts; (2) They preserve historical knowledge by simply replaying historical facts, while ignoring the potential conflicts between historical and emerging facts. In this paper, we propose a Deep Generative Adaptive Replay (DGAR) method, which can generate and adaptively replay historical entity distribution representations from the whole historical context. To address the first challenge, historical context prompts as sampling units are built to preserve the whole historical context information. To overcome the second challenge, a pre-trained diffusion model is adopted to generate the historical distribution. During the generation process, the common features between the historical and current distributions are enhanced under the guidance of the TKGR model. In addition, a layer-by-layer adaptive replay mechanism is designed to effectively integrate historical and current distributions. Experimental results demonstrate that DGAR significantly outperforms baselines in reasoning and mitigating forgetting.
TransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
May 19, 2025Vehicle GPS trajectories provide valuable movement information that supports various downstream tasks and applications. A desirable trajectory learning model should be able to transfer across regions and tasks without retraining, avoiding the need to maintain multiple specialized models and subpar performance with limited training data. However, each region has its unique spatial features and contexts, which are reflected in vehicle movement patterns and difficult to generalize. Additionally, transferring across different tasks faces technical challenges due to the varying input-output structures required for each task. Existing efforts towards transferability primarily involve learning embedding vectors for trajectories, which perform poorly in region transfer and require retraining of prediction modules for task transfer. To address these challenges, we propose TransferTraj, a vehicle GPS trajectory learning model that excels in both region and task transferability. For region transferability, we introduce RTTE as the main learnable module within TransferTraj. It integrates spatial, temporal, POI, and road network modalities of trajectories to effectively manage variations in spatial context distribution across regions. It also introduces a TRIE module for incorporating relative information of spatial features and a spatial context MoE module for handling movement patterns in diverse contexts. For task transferability, we propose a task-transferable input-output scheme that unifies the input-output structure of different tasks into the masking and recovery of modalities and trajectory points. This approach allows TransferTraj to be pre-trained once and transferred to different tasks without retraining. Extensive experiments on three real-world vehicle trajectory datasets under task transfer, zero-shot, and few-shot region transfer, validating TransferTraj's effectiveness.
Harmonizing Intra-coherence and Inter-divergence in Ensemble Attacks for Adversarial Transferability
May 02, 2025The development of model ensemble attacks has significantly improved the transferability of adversarial examples, but this progress also poses severe threats to the security of deep neural networks. Existing methods, however, face two critical challenges: insufficient capture of shared gradient directions across models and a lack of adaptive weight allocation mechanisms. To address these issues, we propose a novel method Harmonized Ensemble for Adversarial Transferability (HEAT), which introduces domain generalization into adversarial example generation for the first time. HEAT consists of two key modules: Consensus Gradient Direction Synthesizer, which uses Singular Value Decomposition to synthesize shared gradient directions; and Dual-Harmony Weight Orchestrator which dynamically balances intra-domain coherence, stabilizing gradients within individual models, and inter-domain diversity, enhancing transferability across models. Experimental results demonstrate that HEAT significantly outperforms existing methods across various datasets and settings, offering a new perspective and direction for adversarial attack research.
Towards An Efficient and Effective En Route Travel Time Estimation Framework
Apr 05, 2025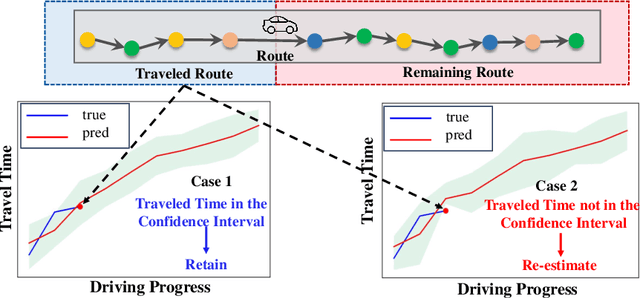

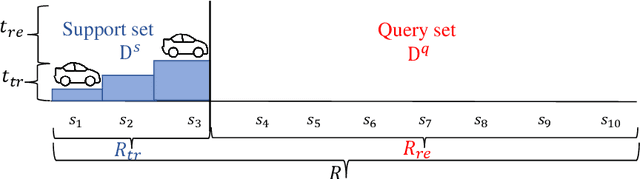

En route travel time estimation (ER-TTE) focuses on predicting the travel time of the remaining route. Existing ER-TTE methods always make re-estimation which significantly hinders real-time performance, especially when faced with the computational demands of simultaneous user requests. This results in delays and reduced responsiveness in ER-TTE services. We propose a general efficient framework U-ERTTE combining an Uncertainty-Guided Decision mechanism (UGD) and Fine-Tuning with Meta-Learning (FTML) to address these challenges. UGD quantifies the uncertainty and provides confidence intervals for the entire route. It selectively re-estimates only when the actual travel time deviates from the predicted confidence intervals, thereby optimizing the efficiency of ER-TTE. To ensure the accuracy of confidence intervals and accurate predictions that need to re-estimate, FTML is employed to train the model, enabling it to learn general driving patterns and specific features to adapt to specific tasks. Extensive experiments on two large-scale real datasets demonstrate that the U-ERTTE framework significantly enhances inference speed and throughput while maintaining high effectiveness. Our code is available at https://github.com/shenzekai/U-ERTTE